R에서 tukey 테스트를 수행하는 방법
일원 분산 분석은 3개 이상의 독립 그룹 평균 간에 통계적으로 유의한 차이가 있는지 여부를 확인하는 데 사용됩니다.
ANOVA 테이블의 전체 p-값이 특정 유의 수준보다 낮으면 그룹 평균 중 하나 이상이 다른 평균과 다르다고 말할 수 있는 충분한 증거가 있는 것입니다.
그러나 이는 어떤 그룹이 서로 다른지는 알려주지 않습니다. 이는 단순히 모든 그룹 평균이 동일하지는 않다는 것을 알려줍니다. 어떤 그룹이 서로 다른지 정확히 알기 위해서는 사후 테스트를 수행해야 합니다.
가장 일반적으로 사용되는 사후 테스트 중 하나는 Tukey 테스트 로, 이를 통해 familywise 오류율을 제어하면서 각 그룹의 평균 간의 쌍별 비교를 수행할 수 있습니다.
이 튜토리얼에서는 R에서 Tukey 테스트를 수행하는 방법을 설명합니다.
참고: 연구에 포함된 그룹 중 통제 그룹으로 간주되는 그룹이 있는 경우 대신 Dunnett의 검정을 사후 검정으로 사용해야 합니다.
예: R의 Tukey 테스트
1단계: 분산분석 모델을 적합시킵니다.
다음 코드는 세 그룹(A, B, C)으로 구성된 가짜 데이터 세트를 생성하고 일원 분산 분석 모델을 데이터에 피팅하여 각 그룹의 평균값이 동일한지 확인하는 방법을 보여줍니다.
#make this example reproducible set.seed(0) #create data data <- data.frame(group = rep (c("A", "B", "C"), each = 30), values = c(runif(30, 0, 3), runif(30, 0, 5), runif(30, 1, 7))) #view first six rows of data head(data) group values 1 A 2.6900916 2 A 0.7965260 3 A 1.1163717 4 A 1.7185601 5 A 2.7246234 6 A 0.6050458 #fit one-way ANOVA model model <- aov (values~group, data=data) #view the model output summary(model) Df Sum Sq Mean Sq F value Pr(>F) group 2 98.93 49.46 30.83 7.55e-11 *** Residuals 87 139.57 1.60 --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
ANOVA 테이블의 전체 p-값이 7.55e-11 임을 알 수 있습니다. 이 숫자는 0.05보다 작으므로 각 그룹의 평균값이 동일하지 않다고 말할 수 있는 충분한 증거가 있습니다. 따라서 Tukey 테스트를 수행하여 정확히 어떤 그룹 평균이 다른지 확인할 수 있습니다.
2단계: Tukey 테스트를 수행합니다.
다음 코드는 TukeyHSD() 함수를 사용하여 Tukey 테스트를 수행하는 방법을 보여줍니다.
#perform Tukey's Test TukeyHSD(model, conf.level= .95 ) Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = values ~ group, data = data) $group diff lwr upr p adj BA 0.9777414 0.1979466 1.757536 0.0100545 CA 2.5454024 1.7656076 3.325197 0.0000000 CB 1.5676610 0.7878662 2.347456 0.0000199
p-값은 각 프로그램 간에 통계적으로 유의미한 차이가 있는지 여부를 나타냅니다. 그 결과, 각 프로그램의 평균 체중 감량은 유의수준 0.05에서 통계적으로 유의미한 차이가 있는 것으로 나타났습니다.
특히:
- B와 A 사이의 평균 차이에 대한 P 값: 0.0100545
- C와 A 간의 평균 차이에 대한 P 값: 0.0000000
- C와 B 사이의 평균 차이에 대한 P 값: 0.0000199
3단계: 결과를 시각화합니다.
또한 플롯(TukeyHSD()) 함수를 사용하여 신뢰구간을 시각화할 수도 있습니다.
#plot confidence intervals plot(TukeyHSD(model, conf.level= .95 ), las = 2 )
참고: las 인수는 눈금 레이블이 축에 수직(las=2)이어야 함을 지정합니다.
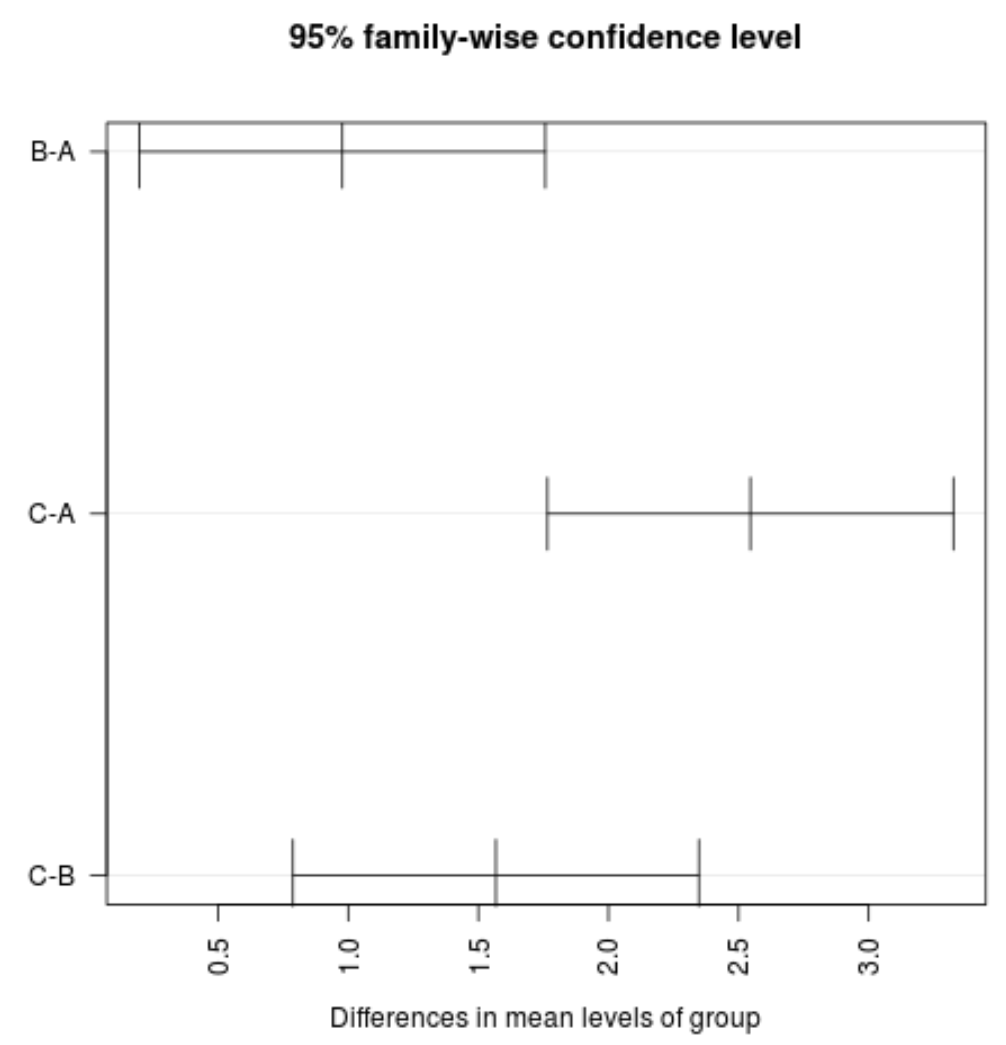
그룹 간 평균값에 대한 신뢰구간 중 어느 것도 0 값을 포함하지 않는 것을 볼 수 있습니다. 이는 세 그룹 간 평균 손실에 통계적으로 유의미한 차이가 있음을 나타냅니다. 이는 가설 검정에 대한 모든 p-값이 0.05 미만인 것과 일치합니다.
이 특정 예에서는 다음과 같은 결론을 내릴 수 있습니다.
- 그룹 C의 평균값은 그룹 A와 B의 평균값보다 상당히 높습니다.
- 그룹 B의 평균값은 그룹 A의 평균값보다 상당히 높습니다.
추가 리소스
ANOVA를 통한 사후 테스트 사용 가이드
R에서 일원 분산 분석을 수행하는 방법
R에서 양방향 ANOVA를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기