Python에서 정규성을 테스트하는 방법(4가지 방법)
많은 통계 테스트에서는 데이터 세트가 정규 분포를 따른다고 가정합니다 .
Python에서 이 가설을 확인하는 네 가지 일반적인 방법이 있습니다.
1. (시각적 방법) 히스토그램을 생성합니다.
- 히스토그램이 대략 “종” 모양이면 데이터가 정규 분포를 따르는 것으로 간주됩니다.
2. (시각적 방법) QQ 플롯을 생성합니다.
- 그림의 점이 대략 직선 대각선을 따라 있으면 데이터가 정규 분포를 따르는 것으로 간주됩니다.
3. (정식 통계 검정) Shapiro-Wilk 검정을 수행합니다.
- 검정의 p-값이 α = 0.05보다 크면 데이터가 정규 분포를 따르는 것으로 가정됩니다.
4. (공식 통계 검정) Kolmogorov-Smirnov 검정을 수행합니다.
- 검정의 p-값이 α = 0.05보다 크면 데이터가 정규 분포를 따르는 것으로 가정됩니다.
다음 예에서는 이러한 각 방법을 실제로 사용하는 방법을 보여줍니다.
방법 1: 히스토그램 만들기
다음 코드는 로그 정규 분포를 따르는 데이터 세트에 대한 히스토그램을 생성하는 방법을 보여줍니다.
import math
import numpy as np
from scipy. stats import lognorm
import matplotlib. pyplot as plt
#make this example reproducible
n.p. random . seeds (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale= math.exp (1), size=1000)
#create histogram to visualize values in dataset
plt. hist (lognorm_dataset, edgecolor=' black ', bins=20)
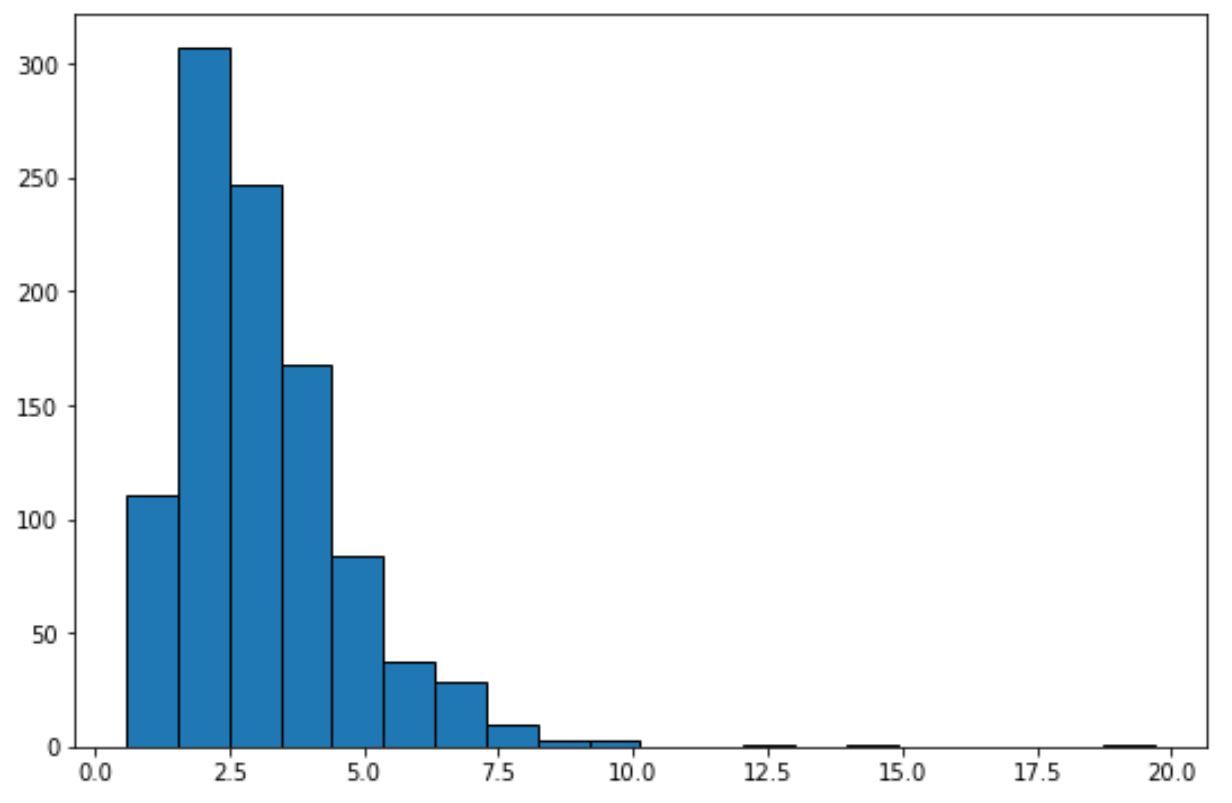
이 히스토그램만 보면 데이터세트가 “종 모양”을 나타내지 않고 정규 분포를 따르지 않는다는 것을 알 수 있습니다.
방법 2: QQ 플롯 생성
다음 코드는 로그 정규 분포를 따르는 데이터 세트에 대한 QQ 플롯을 생성하는 방법을 보여줍니다.
import math
import numpy as np
from scipy. stats import lognorm
import statsmodels. api as sm
import matplotlib. pyplot as plt
#make this example reproducible
n.p. random . seeds (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale= math.exp (1), size=1000)
#create QQ plot with 45-degree line added to plot
fig = sm. qqplot (lognorm_dataset, line=' 45 ')
plt. show ()
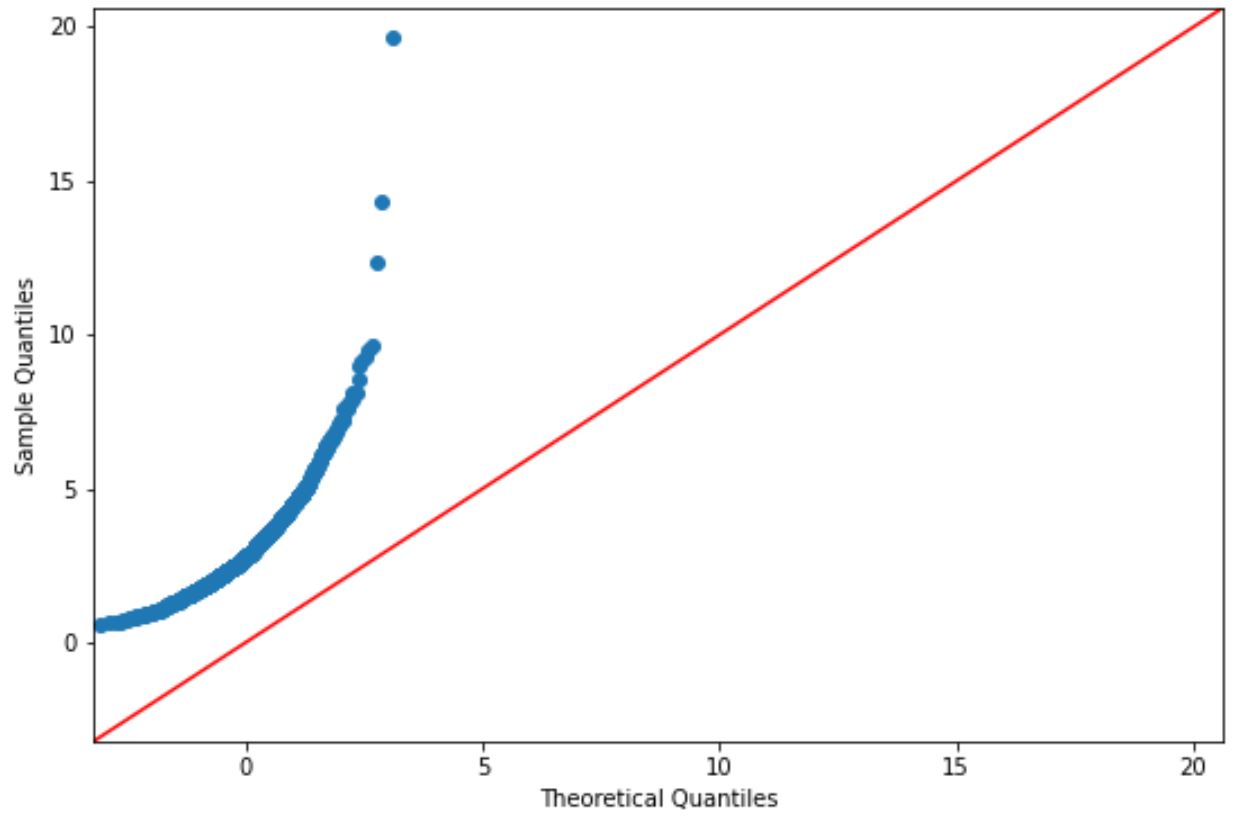
플롯 포인트가 대략 직선 대각선을 따라 있는 경우 일반적으로 데이터 세트가 정규 분포를 따른다고 가정합니다.
그러나 이 그래프의 점은 빨간색 선과 명확하게 일치하지 않으므로 이 데이터 세트가 정규 분포를 따른다고 가정할 수 없습니다.
이는 로그 정규 분포 함수를 사용하여 데이터를 생성했다는 점을 고려하면 의미가 있습니다.
방법 3: Shapiro-Wilk 테스트 수행
다음 코드는 로그 정규 분포를 따르는 데이터 세트에 대해 Shapiro-Wilk를 수행하는 방법을 보여줍니다.
import math
import numpy as np
from scipy.stats import shapiro
from scipy. stats import lognorm
#make this example reproducible
n.p. random . seeds (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale= math.exp (1), size=1000)
#perform Shapiro-Wilk test for normality
shapiro(lognorm_dataset)
ShapiroResult(statistic=0.8573324680328369, pvalue=3.880663073872444e-29)
결과에서 검정 통계량은 0.857 이고 해당 p-값은 3.88e-29 (0에 매우 가까움)임을 알 수 있습니다.
p-값이 0.05보다 작으므로 Shapiro-Wilk 검정의 귀무가설을 기각합니다.
이는 표본 데이터가 정규 분포에서 나오지 않는다고 말할 수 있는 충분한 증거가 있음을 의미합니다.
방법 4: Kolmogorov-Smirnov 테스트 수행
다음 코드는 로그 정규 분포를 따르는 데이터 세트에 대해 Kolmogorov-Smirnov 테스트를 수행하는 방법을 보여줍니다.
import math
import numpy as np
from scipy.stats import kstest
from scipy. stats import lognorm
#make this example reproducible
n.p. random . seeds (1)
#generate dataset that contains 1000 log-normal distributed values
lognorm_dataset = lognorm. rvs (s=.5, scale= math.exp (1), size=1000)
#perform Kolmogorov-Smirnov test for normality
kstest(lognorm_dataset, ' norm ')
KstestResult(statistic=0.84125708308077, pvalue=0.0)
결과에서 검정 통계량은 0.841 이고 해당 p-값은 0.0 임을 알 수 있습니다.
p-값이 0.05보다 작으므로 Kolmogorov-Smirnov 검정의 귀무가설을 기각합니다.
이는 표본 데이터가 정규 분포에서 나오지 않는다고 말할 수 있는 충분한 증거가 있음을 의미합니다.
비정규 데이터를 처리하는 방법
주어진 데이터 세트가 정규 분포를 따르지 않는 경우 다음 변환 중 하나를 수행하여 보다 정규 분포를 만들 수 있습니다.
1. 로그 변환: x 값을 log(x) 로 변환합니다.
2. 제곱근 변환: x의 값을 √x 로 변환합니다.
3. 세제곱근 변환: x 값을 x 1/3 으로 변환합니다.
이러한 변환을 수행함으로써 데이터세트는 일반적으로 보다 정규 분포를 띄게 됩니다.
Python에서 이러한 변환을 수행하는 방법을 알아보려면 이 튜토리얼을 읽어보세요.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기