Python에서 chow 테스트를 수행하는 방법
Chow 테스트는 서로 다른 데이터 세트에 대한 두 개의 서로 다른 회귀 모델의 계수가 동일한지 여부를 테스트하는 데 사용됩니다.
이 테스트는 일반적으로 시계열 데이터를 사용하는 계량경제학 분야에서 특정 시점에 데이터에 구조적 중단이 있는지 확인하는 데 사용됩니다.
다음 단계별 예제에서는 Python에서 Chow 테스트를 수행하는 방법을 보여줍니다.
1단계: 데이터 생성
먼저 가짜 데이터를 만듭니다.
import pandas as pd #createDataFrame df = pd. DataFrame ({' x ': [1, 1, 2, 3, 4, 4, 5, 5, 6, 7, 7, 8, 8, 9, 10, 10, 11, 12, 12, 13, 14, 15, 15, 16, 17, 18, 18, 19, 20, 20], ' y ': [3, 5, 6, 10, 13, 15, 17, 14, 20, 23, 25, 27, 30, 30, 31, 33, 32, 32, 30, 32, 34, 34, 37, 35, 34, 36, 34, 37, 38, 36]}) #view first five rows of DataFrame df. head () x y 0 1 3 1 1 5 2 2 6 3 3 10 4 4 13
2단계: 데이터 시각화
다음으로, 데이터를 시각화하기 위한 간단한 산점도를 만들어 보겠습니다.
import matplotlib. pyplot as plt
#create scatterplot
plt. plot (df. x , df. y , ' o ')
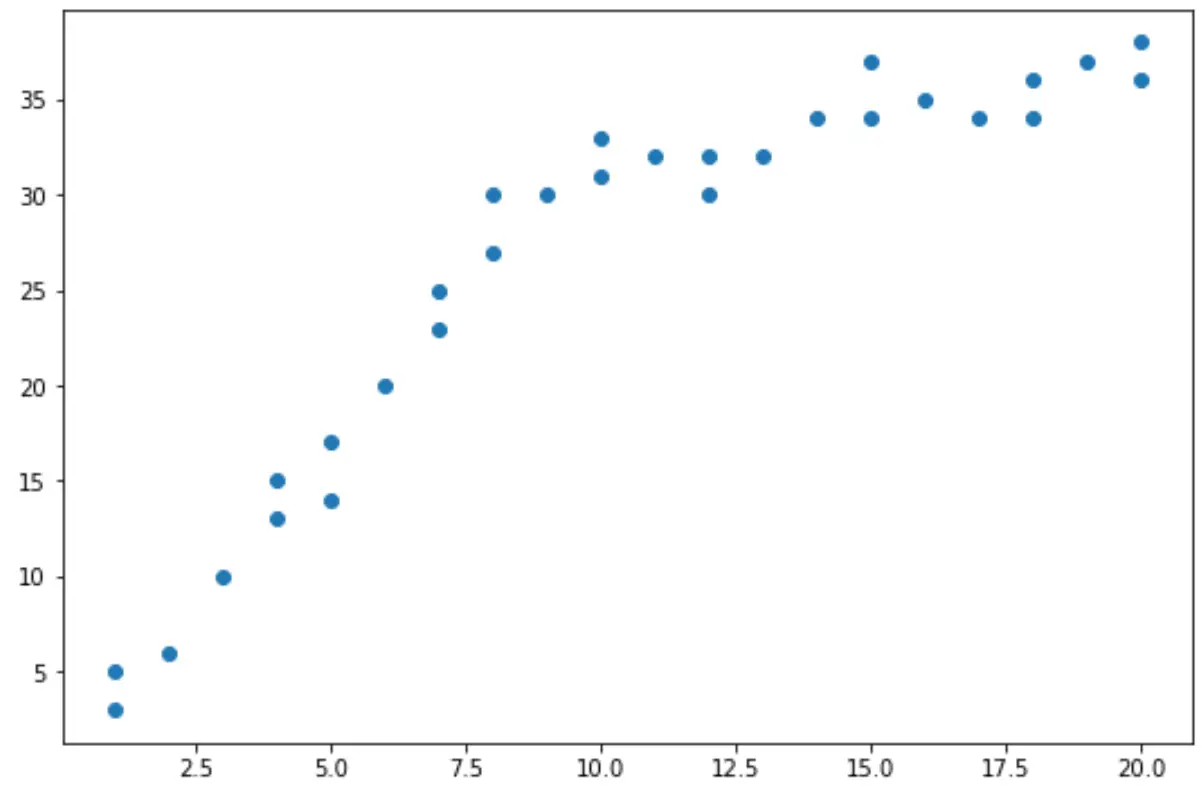
산점도에서 데이터의 추세가 x = 10에서 변하는 것으로 나타나는 것을 볼 수 있습니다.
따라서 Chow 테스트를 수행하여 x = 10의 데이터에 구조적 중단점이 있는지 확인할 수 있습니다.
3단계: 차우 테스트 수행
Python에서 chowtest 패키지의 chowtest 함수를 사용하여 Chow 테스트를 수행할 수 있습니다.
먼저 pip를 사용하여 이 패키지를 설치해야 합니다.
pip install chowtest
그런 다음 다음 구문을 사용하여 Chow 테스트를 수행할 수 있습니다.
from chow_test import chowtest chowtest ( y=df[[' y ']], last_index_in_model_1= 15 , first_index_in_model_2= 16 , significance_level= .05 ) ************************************************** ********************************* Reject the null hypothesis of equality of regression coefficients in the 2 periods. ************************************************** ********************************* Chow Statistic: 118.14097335479373 p value: 0.0 ************************************************** ********************************* (118.14097335479373, 1.1102230246251565e-16)
chowtest() 함수의 개별 인수가 의미하는 바는 다음과 같습니다.
- y : DataFrame의 응답 변수
- x : DataFrame의 예측 변수
- last_index_in_model_1 : 구조적 중단 전 마지막 지점의 인덱스 값
- first_index_in_model_2 : 구조적 중단 이후 첫 번째 지점의 인덱스 값
- Significance_level : 가설 검정에 사용할 유의 수준
테스트 결과에서 다음을 확인할 수 있습니다.
- F-검정 통계량 : 118.14
- p-값: <.0000
p-값이 0.05보다 작으므로 검정의 귀무가설을 기각할 수 있습니다. 이는 데이터에 구조적 중단점이 존재한다고 말할 수 있는 충분한 증거가 있음을 의미합니다.
즉, 두 개의 회귀선이 단일 회귀선보다 데이터에 모델을 더 효과적으로 맞출 수 있습니다.
추가 리소스
다음 튜토리얼에서는 Python에서 다른 일반적인 테스트를 수행하는 방법을 설명합니다.
Python에서 Granger 인과성 테스트를 수행하는 방법
Python에서 Breusch-Pagan 테스트를 수행하는 방법
Python에서 White의 테스트를 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기