Python에서 elbow 방법을 사용하여 최적의 클러스터를 찾는 방법
기계 학습 에서 가장 일반적인 클러스터링 알고리즘 중 하나는 k-평균 클러스터링 으로 알려져 있습니다.
K-평균 클러스터링은 데이터 세트의 각 관측치를 K 클러스터 중 하나에 배치하는 기술입니다.
최종 목표는 각 클러스터 내의 관측치가 서로 매우 유사한 반면 다른 클러스터의 관측치는 서로 상당히 다른 K 개의 클러스터를 갖는 것입니다.
k-평균 군집화를 수행할 때 첫 번째 단계는 관측값을 배치하려는 군집 수인 K 값을 선택하는 것입니다.
K 값을 선택하는 가장 일반적인 방법 중 하나는 엘보우 방법(elbow method) 으로, x축에 군집 수와 y축에 제곱합의 합계를 사용하여 플롯을 생성한 다음 다음을 식별합니다. 플롯에 “무릎” 또는 회전이 나타나는 곳입니다.
“무릎”이 발생하는 x축 지점은 k-평균 클러스터링 알고리즘에 사용할 최적의 클러스터 수를 알려줍니다.
다음 예제에서는 Python에서 Elbow 메서드를 사용하는 방법을 보여줍니다.
1단계: 필요한 모듈 가져오기
먼저 k-평균 클러스터링을 수행하는 데 필요한 모든 모듈을 가져옵니다.
import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
from sklearn. cluster import KMeans
from sklearn. preprocessing import StandardScaler
2단계: DataFrame 생성
다음으로, 20명의 농구 선수에 대한 세 가지 변수가 포함된 DataFrame을 만듭니다.
#createDataFrame
df = pd. DataFrame ({' points ': [18, np.nan, 19, 14, 14, 11, 20, 28, 30, 31,
35, 33, 29, 25, 25, 27, 29, 30, 19, 23],
' assists ': [3, 3, 4, 5, 4, 7, 8, 7, 6, 9, 12, 14,
np.nan, 9, 4, 3, 4, 12, 15, 11],
' rebounds ': [15, 14, 14, 10, 8, 14, 13, 9, 5, 4,
11, 6, 5, 5, 3, 8, 12, 7, 6, 5]})
#drop rows with NA values in any columns
df = df. dropna ()
#create scaled DataFrame where each variable has mean of 0 and standard dev of 1
scaled_df = StandardScaler(). fit_transform (df)
3단계: 엘보우 방법을 사용하여 최적의 군집 수 찾기
k-평균 클러스터링을 사용하여 이 세 가지 지표를 기반으로 유사한 행위자를 그룹화한다고 가정해 보겠습니다.
Python에서 k-평균 클러스터링을 수행하려면 sklearn 모듈의 KMeans 함수를 사용할 수 있습니다.
이 함수의 가장 중요한 인수는 관측값을 배치할 클러스터 수를 지정하는 n_clusters 입니다.
최적의 클러스터 수를 결정하기 위해 모델의 SSE(제곱 오류 합계)와 클러스터 수를 표시하는 그래프를 만듭니다.
그런 다음 제곱합이 “구부러지거나” 안정되기 시작하는 “무릎”을 찾습니다. 이 지점은 최적의 클러스터 수를 나타냅니다.
다음 코드는 x축에 클러스터 수를 표시하고 y축에 SSE를 표시하는 이러한 유형의 플롯을 생성하는 방법을 보여줍니다.
#initialize kmeans parameters kmeans_kwargs = { " init ": " random ", " n_init ": 10, " random_state ": 1, } #create list to hold SSE values for each k sse = [] for k in range(1, 11): kmeans = KMeans(n_clusters=k, ** kmeans_kwargs) kmeans. fit (scaled_df) sse. append (kmeans.inertia_) #visualize results plt. plot (range(1, 11), sse) plt. xticks (range(1, 11)) plt. xlabel (" Number of Clusters ") plt. ylabel (“ SSE ”) plt. show ()
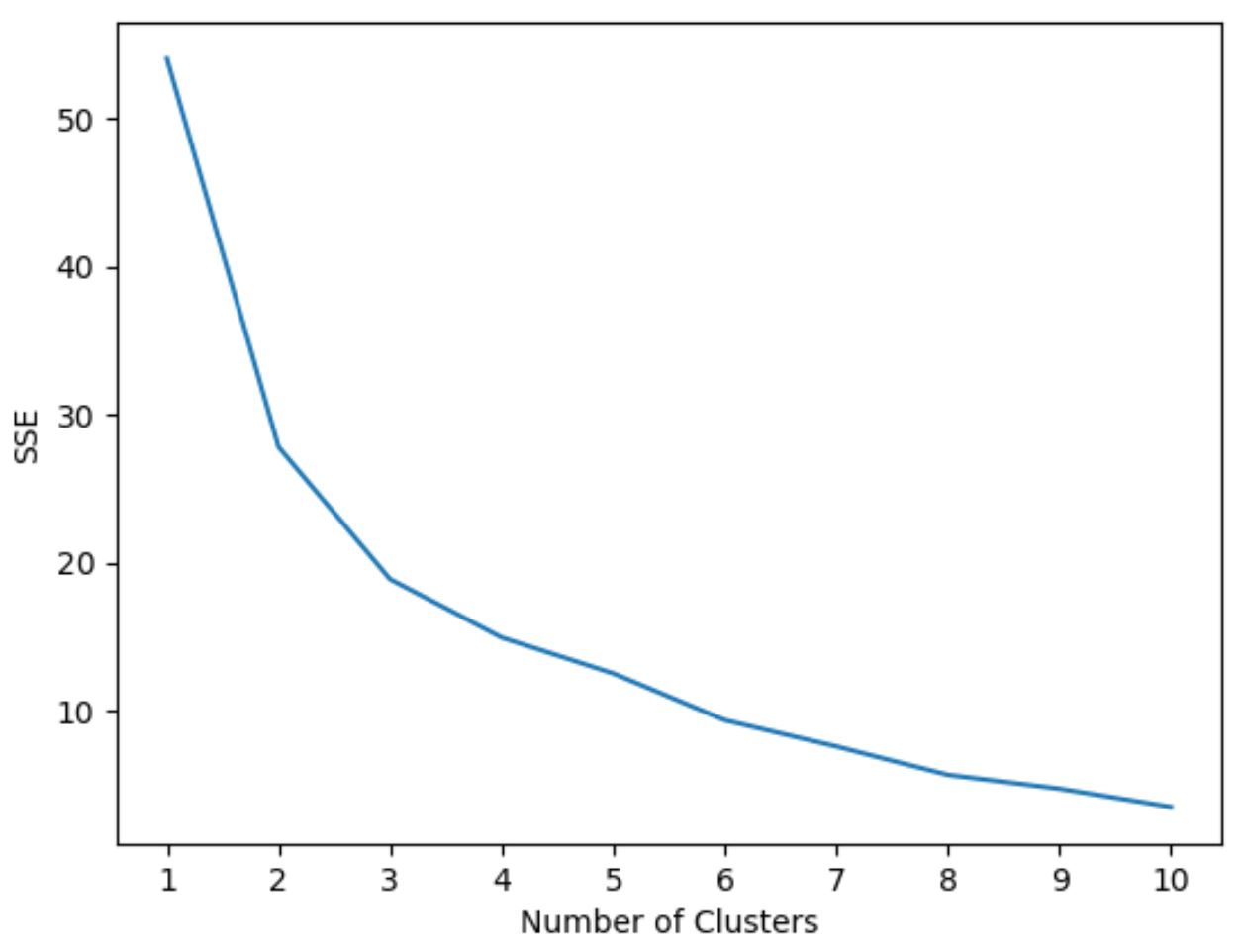
이 그래프에서는 k = 3개 클러스터 에 꼬임 또는 “무릎”이 있는 것으로 나타납니다.
따라서 다음 단계에서 k-평균 클러스터링 모델을 피팅할 때 3개의 클러스터를 사용하겠습니다.
4단계: 최적 K를 사용하여 K-평균 군집화 수행
다음 코드는 3의 k 에 대한 최적 값을 사용하여 데이터 세트에서 k-평균 클러스터링을 수행하는 방법을 보여줍니다.
#instantiate the k-means class, using optimal number of clusters
kmeans = KMeans(init=" random ", n_clusters= 3 , n_init= 10 , random_state= 1 )
#fit k-means algorithm to data
kmeans. fit (scaled_df)
#view cluster assignments for each observation
kmeans. labels_
array([1, 1, 1, 1, 1, 1, 2, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0])
결과 테이블에는 DataFrame의 각 관찰에 대한 클러스터 할당이 표시됩니다.
이러한 결과를 더 쉽게 해석할 수 있도록 각 플레이어의 클러스터 할당을 표시하는 열을 DataFrame에 추가할 수 있습니다.
#append cluster assingments to original DataFrame
df[' cluster '] = kmeans. labels_
#view updated DataFrame
print (df)
points assists rebounds cluster
0 18.0 3.0 15 1
2 19.0 4.0 14 1
3 14.0 5.0 10 1
4 14.0 4.0 8 1
5 11.0 7.0 14 1
6 20.0 8.0 13 1
7 28.0 7.0 9 2
8 30.0 6.0 5 2
9 31.0 9.0 4 0
10 35.0 12.0 11 0
11 33.0 14.0 6 0
13 25.0 9.0 5 0
14 25.0 4.0 3 2
15 27.0 3.0 8 2
16 29.0 4.0 12 2
17 30.0 12.0 7 0
18 19.0 15.0 6 0
19 23.0 11.0 5 0
클러스터 열에는 각 플레이어가 할당된 클러스터 번호(0, 1 또는 2)가 포함됩니다.
동일한 클러스터에 속한 플레이어는 포인트 , 어시스트 및 리바운드 열에 대해 대략 유사한 값을 갖습니다.
참고 : 여기에서 sklearn 의 KMeans 기능에 대한 전체 문서를 찾을 수 있습니다.
추가 리소스
다음 튜토리얼에서는 Python에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
Python에서 선형 회귀를 수행하는 방법
Python에서 로지스틱 회귀를 수행하는 방법
Python에서 K-Fold 교차 검증을 수행하는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기