Pandas: excel 파일을 읽을 때 줄을 건너뛰는 방법
Excel 파일을 Pandas DataFrame으로 읽을 때 다음 방법을 사용하여 행을 건너뛸 수 있습니다.
방법 1: 특정 행 건너뛰기
#import DataFrame and skip row in index position 2 df = pd. read_excel (' my_data.xlsx ', skiprows=[ 2 ])
방법 2: 여러 특정 행 무시
#import DataFrame and skip rows in index positions 2 and 4 df = pd. read_excel (' my_data.xlsx ' , skiprows=[2,4 ] )
방법 3: 처음 N 줄을 무시합니다.
#import DataFrame and skip first 2 rows df = pd. read_excel (' my_data.xlsx ', skiprows= 2 )
다음 예에서는 player_data.xlsx 라는 Excel 파일을 사용하여 실제로 각 메서드를 사용하는 방법을 보여줍니다.
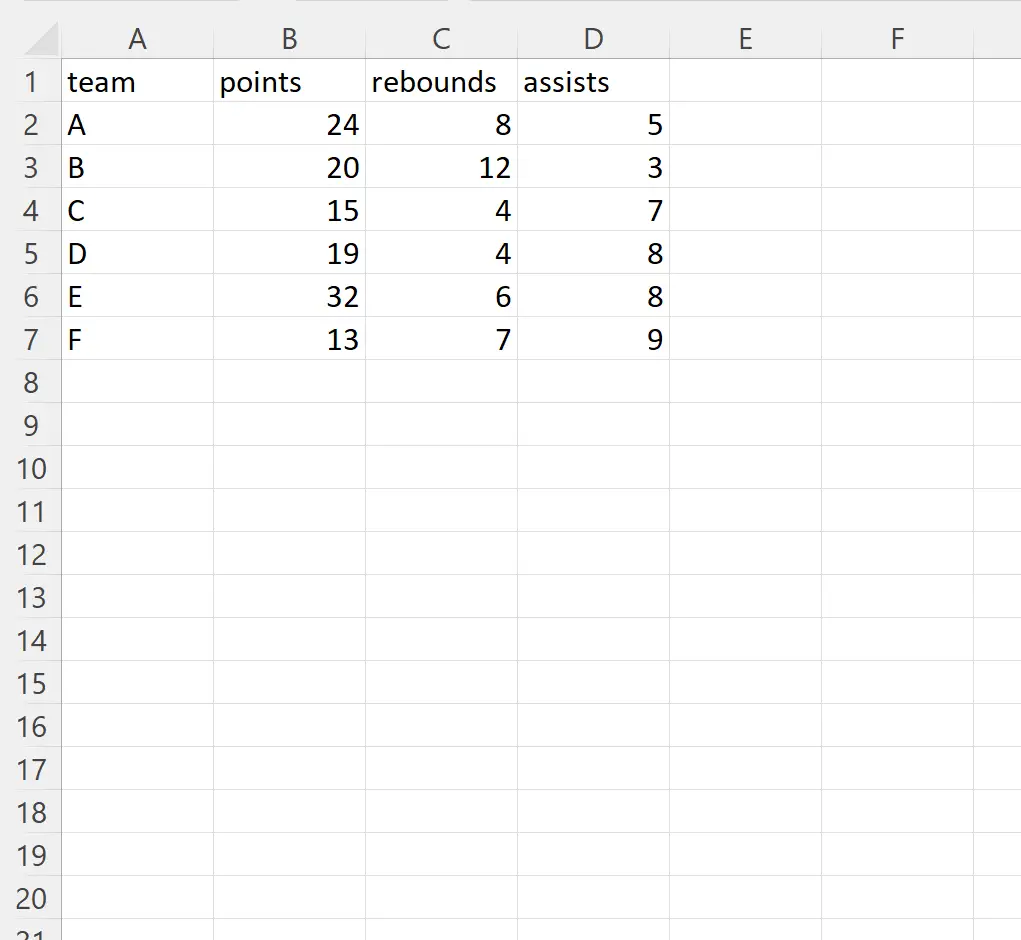
예시 1: 특정 행 무시
다음 코드를 사용하여 Excel 파일을 가져오고 인덱스 위치 2의 행을 무시할 수 있습니다.
import pandas as pd #import DataFrame and skip row in index position 2 df = pd. read_excel (' player_data.xlsx ', skiprows=[ 2 ]) #view DataFrame print (df) team points rebound assists 0 to 24 8 5 1 C 15 4 7 2 D 19 4 8 3 E 32 6 8 4 F 13 7 9
Excel 파일을 pandas DataFrame으로 가져올 때 인덱스 위치 2(팀 ‘B’ 포함)에 있는 행이 무시되었습니다.
참고 : Excel 파일의 첫 번째 줄은 0번 줄로 간주됩니다.
예시 2: 여러 특정 줄 무시
다음 코드를 사용하여 Excel 파일을 가져오고 인덱스 위치 2와 4의 행을 무시할 수 있습니다.
import pandas as pd #import DataFrame and skip rows in index positions 2 and 4 df = pd. read_excel (' player_data.xlsx ', skiprows=[ 2,4 ] ) #view DataFrame print (df) team points rebound assists 0 to 24 8 5 1 C 15 4 7 2 E 32 6 8 3 F 13 7 9
Excel 파일을 pandas DataFrame으로 가져올 때 인덱스 위치 2와 4(팀 “B” 및 “D” 포함)의 행은 무시되었습니다.
예시 3: 처음 N 줄 무시
다음 코드를 사용하여 Excel 파일을 가져오고 처음 두 줄을 무시할 수 있습니다.
import pandas as pd #import DataFrame and skip first 2 rows df = pd. read_excel (' player_data.xlsx ', skiprows= 2 ) #view DataFrame print (df) B 20 12 3 0 C 15 4 7 1 D 19 4 8 2 E 32 6 8 3 F 13 7 9
Excel 파일의 처음 두 행은 건너뛰었고 사용 가능한 다음 행(팀 “B” 포함)은 DataFrame의 헤더 행이 되었습니다.
추가 리소스
다음 튜토리얼에서는 Python에서 다른 일반적인 작업을 수행하는 방법을 설명합니다.
Pandas로 Excel 파일을 읽는 방법
Pandas DataFrame을 Excel로 내보내는 방법
NumPy 배열을 CSV 파일로 내보내는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기