팬더에서 누락된 값을 대치하는 방법(예제 포함)
다음 기본 구문을 사용하여 Pandas DataFrame에서 누락된 값을 대치할 수 있습니다.
df[' column_name '] = df[' column_name ']. interpolate ()
다음 예에서는 실제로 이 구문을 사용하는 방법을 보여줍니다.
예: Pandas에서 누락된 값 보간
연속 15일 동안 매장에서 발생한 총 매출을 보여주는 다음과 같은 pandas DataFrame이 있다고 가정해 보겠습니다.
import pandas as pd import numpy as np #createDataFrame df = pd. DataFrame ({' day ': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15], ' sales ': [3, 6, 8, 10, 14, 17, 20, np.nan, np.nan, np.nan, np.nan, 35, 39, 44, 49]}) #view DataFrame print (df) day sales 0 1 3.0 1 2 6.0 2 3 8.0 3 4 10.0 4 5 14.0 5 6 17.0 6 7 20.0 7 8 NaN 8 9 NaN 9 10 NaN 10 11 NaN 11 12 35.0 12 13 39.0 13 14 44.0 14 15 49.0
데이터 프레임에는 4일 동안의 판매 수치가 누락되어 있습니다.
시간 경과에 따른 매출을 시각화하기 위해 간단한 꺾은선형 차트를 만든 경우 다음과 같습니다.
#create line chart to visualize sales df[' sales ']. plot ()
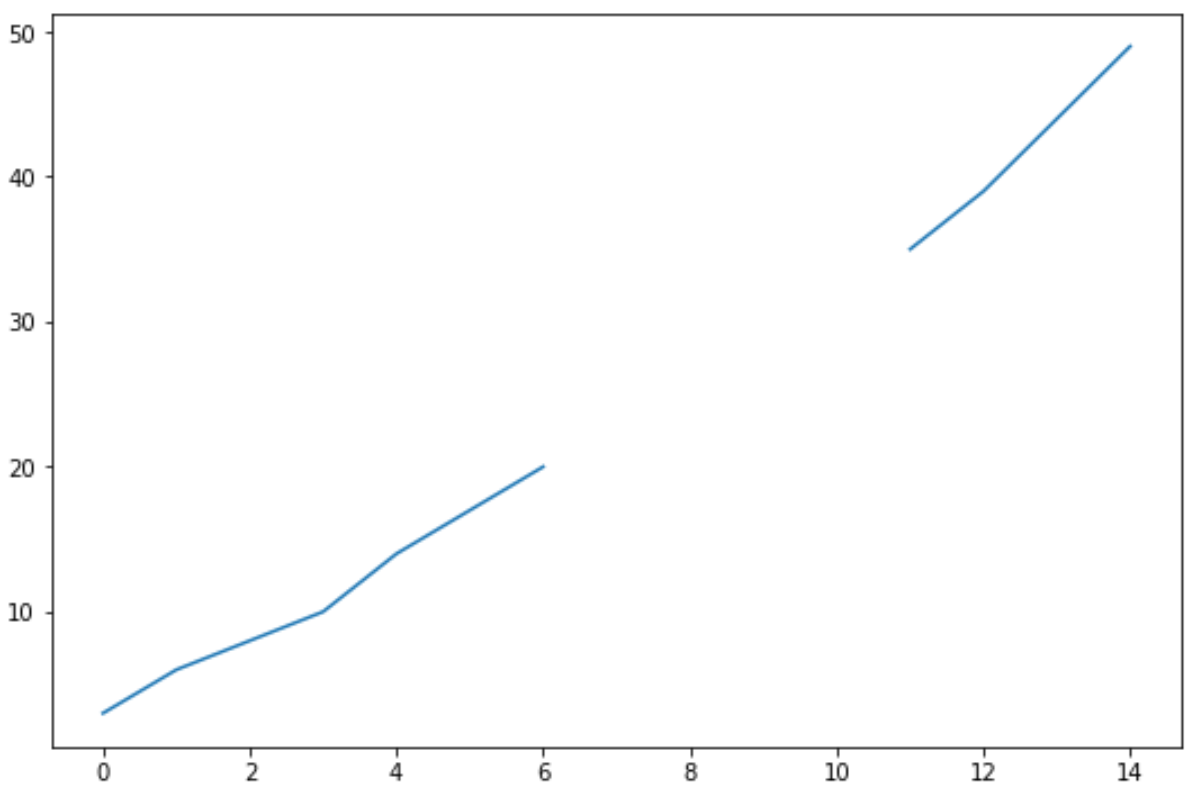
누락된 값을 채우기 위해 다음과 같이 interpolate() 함수를 사용할 수 있습니다.
#interpolate missing values in 'sales' column df[' sales '] = df[' sales ']. interpolate () #view DataFrame print (df) day sales 0 1 3.0 1 2 6.0 2 3 8.0 3 4 10.0 4 5 14.0 5 6 17.0 6 7 20.0 7 8 23.0 8 9 26.0 9 10 29.0 10 11 32.0 11 12 35.0 12 13 39.0 13 14 44.0 14 15 49.0
누락된 값은 각각 대체되었습니다.
업데이트된 데이터 프레임을 시각화하기 위해 또 다른 선 차트를 생성하면 다음과 같습니다.
#create line chart to visualize sales df[' sales ']. plot ()
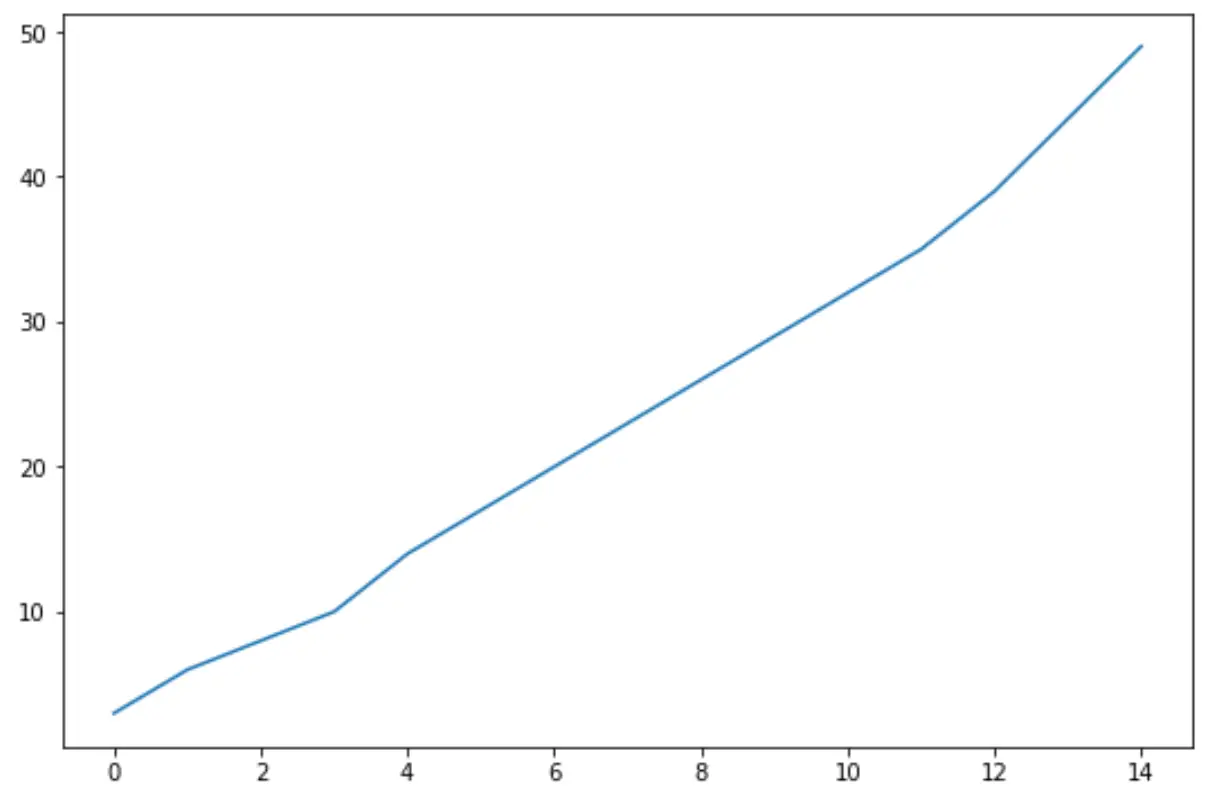
참고로 interpolate() 함수로 선택한 값은 데이터의 추세와 꽤 잘 맞는 것 같습니다.
참고 : interpolate() 함수에 대한 전체 문서는 여기에서 찾을 수 있습니다.
추가 리소스
다음 튜토리얼은 Pandas에서 누락된 값을 처리하는 방법에 대한 추가 정보를 제공합니다.
팬더에서 누락된 값을 계산하는 방법
Pandas에서 NaN 값을 문자열로 바꾸는 방법
Pandas에서 NaN 값을 0으로 바꾸는 방법
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기