일원 분산 분석을 수동으로 수행하는 방법
일원 분산 분석 (“분산 분석”)은 3개 이상의 독립 그룹의 평균을 비교하여 해당 모집단의 평균 간에 통계적으로 유의미한 차이가 있는지 확인합니다.
이 튜토리얼에서는 일원 분산 분석을 수동으로 수행하는 방법을 설명합니다.
예: 수동 일원 분산 분석
세 가지 서로 다른 시험 준비 프로그램이 특정 시험에서 서로 다른 평균 점수를 가져오는지 여부를 알고 싶다고 가정해 보겠습니다. 이를 테스트하기 위해 우리는 연구에 참여할 학생 30명을 모집하고 그들을 세 그룹으로 나눕니다.
각 그룹의 학생들은 시험 준비를 위해 다음 3주 동안 세 가지 시험 준비 프로그램 중 하나를 사용하도록 무작위로 배정됩니다. 3주 후에는 모든 학생들이 동일한 시험을 치릅니다.
각 그룹의 시험 결과는 다음과 같습니다.
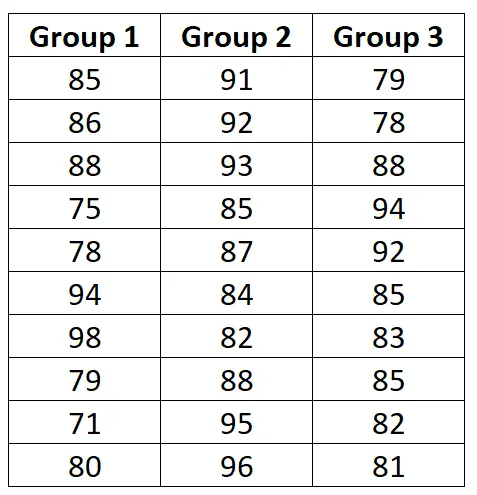
평균 시험 점수가 세 그룹 간에 다른지 확인하기 위해 일원 분산 분석을 수동으로 수행하려면 다음 단계를 따르십시오.
1단계: 그룹 평균과 전체 평균을 계산합니다.
먼저 세 그룹의 평균과 전체 평균을 계산합니다.
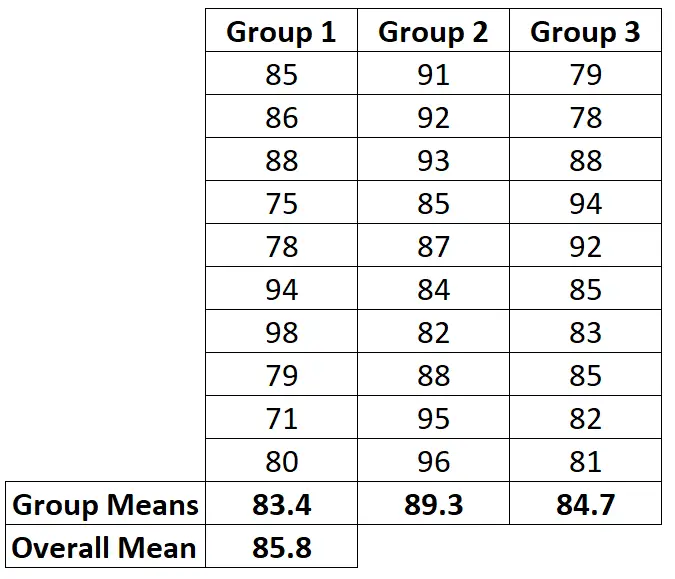
2단계: SSR을 계산합니다.
다음으로, 다음 공식을 사용하여 SSR(제곱합 회귀)을 계산합니다.
nΣ(X j – X ..) 2
금:
- n : 그룹 j의 표본 크기
- Σ : “합계”를 의미하는 그리스 기호
- X j : 그룹 j의 평균
- X .. : 전체 평균
이 예에서는 SSR = 10(83.4-85.8) 2 + 10(89.3-85.8) 2 + 10(84.7-85.8) 2 = 192.2 로 계산됩니다.
3단계: SES를 계산합니다.
다음으로, 다음 공식을 사용하여 SSE(제곱 오류의 합)를 계산합니다.
Σ( Xij – Xj ) 2
금:
- Σ : “합계”를 의미하는 그리스 기호
- X ij : 그룹 j의 i번째 관측치
- X j : 그룹 j의 평균
이 예에서는 SSE를 다음과 같이 계산합니다.
그룹 1: (85-83.4) 2 + (86-83.4) 2 + (88-83.4) 2 + (75-83.4) 2 + (78-83.4) 2 + (94-83.4) 2 + (98-83.4) 2 + (79-83.4) 2 + (71-83.4) 2 + (80-83.4) 2 = 640.4
그룹 2: (91-89.3) 2 + (92-89.3) 2 + (93-89.3) 2 + (85-89.3) 2 + (87-89.3) 2 + (84-89.3) 2 + (82-89.3) 2 + (88-89.3) 2 + (95-89.3) 2 + (96-89.3) 2 = 208.1
그룹 3: (79-84.7) 2 + (78-84.7) 2 + (88-84.7) 2 + (94-84.7) 2 + (92-84.7) 2 + (85-84.7) 2 + (83-84.7) 2 + (85-84.7) 2 + (82-84.7) 2 + (81-84.7) 2 = 252.1
ESS: 640.4 + 208.1 + 252.1 = 1,100.6
4단계: SST를 계산합니다.
다음으로, 다음 공식을 사용하여 총 제곱합(SST)을 계산합니다.
SST = SSR + SSE
이 예에서는 SST = 192.2 + 1100.6 = 1292.8
5단계: 분산분석표를 완성합니다.
이제 SSR, SSE 및 SST가 있으므로 ANOVA 테이블을 채울 수 있습니다.
| 원천 | 제곱합(SS) | df | 평균 제곱(MS) | 에프 |
|---|---|---|---|---|
| 치료 | 192.2 | 2 | 96.1 | 2,358 |
| 오류 | 1100.6 | 27 | 40.8 | |
| 총 | 1292.8 | 29 |
다음은 표의 다양한 숫자를 계산하는 방법입니다.
- 처리 df: k-1 = 3-1 = 2
- 오류 df: nk = 30-3 = 27
- 총 df: n-1 = 30-1 = 29
- SEP 처리 : SST 처리 / df = 192.2 / 2 = 96.1
- MS 오류: SSE 오류 / df = 1100.6 / 27 = 40.8
- F: MS 처리 / MS 오류 = 96.1 / 40.8 = 2.358
참고: n = 총 관측치 수, k = 그룹 수
6단계: 결과를 해석합니다.
이 일원 분산 분석의 F 검정 통계량은 2.358 입니다. 이것이 통계적으로 유의미한 결과인지 확인하려면 이를 다음 값을 사용하여 F 분포표 에서 찾은 임계 F 값과 비교해야 합니다.
- α(유의 수준) = 0.05
- DF1(분자의 자유도) = df 처리 = 2
- DF2(분모의 자유도) = 오차 df = 27
F의 임계값은 3.3541 입니다.
ANOVA 테이블의 F 검정 통계량이 F 분포 테이블의 임계값 F보다 작기 때문에 귀무 가설을 기각할 수 없습니다. 이는 세 그룹의 평균 시험 점수 간에 통계적으로 유의미한 차이가 있다고 말할 수 있는 충분한 증거가 없음을 의미합니다.
보너스 리소스: 이 일원 분산 분석 계산기를 사용하면 최대 5개 샘플에 대해 일원 분산 분석을 자동으로 수행할 수 있습니다.
저자 소개
벤자민 앤더슨
안녕하세요. 저는 통계학 교수를 퇴직하고 전임 통계 교사로 변신한 벤자민입니다. 통계 분야의 광범위한 경험과 전문 지식을 바탕으로 Statorials를 통해 학생들에게 힘을 실어주기 위해 지식을 공유하고 싶습니다. 더 알아보기