R တွင် ကျပန်းသစ်တောများ ဖန်တီးနည်း (တစ်ဆင့်ပြီးတစ်ဆင့်)
ကြိုတင်ခန့်မှန်းကိန်းရှင်အစုတစ်ခုနှင့် တုံ့ပြန်မှုကိန်းရှင် ကြားက ဆက်ဆံရေးသည် အလွန်ရှုပ်ထွေးသောအခါ၊ ၎င်းတို့ကြားရှိ ဆက်ဆံရေးကို နမူနာယူရန် လိုင်းမဟုတ်သောနည်းလမ်းများကို အသုံးပြုလေ့ရှိသည်။
ထိုကဲ့သို့သော နည်းလမ်းတစ်ခုမှာ ဆုံးဖြတ်ချက်သစ် တစ်ခုကို တည်ဆောက်ရန်ဖြစ်သည်။ သို့သော်၊ တစ်ခုတည်းသောဆုံးဖြတ်ချက်သစ်ပင်ကိုအသုံးပြုခြင်း၏အားနည်းချက်မှာ၎င်းသည် မြင့်မားသောကွဲလွဲမှုကို ခံစားရတတ်သည်။
ဆိုလိုသည်မှာ၊ ကျွန်ုပ်တို့သည် ဒေတာအတွဲကို နှစ်ပိုင်းခွဲပြီး ဆုံးဖြတ်ချက်သစ်ကို နှစ်ခြမ်းစလုံးတွင် အသုံးချပါက၊ ရလဒ်များသည် အလွန်ကွဲပြားနိုင်သည်။
တစ်ခုတည်းသော ဆုံးဖြတ်ချက်သစ်ပင်၏ ကွဲလွဲမှုကို လျှော့ချရန် ကျွန်ုပ်တို့ အသုံးပြုနိုင်သည့် နည်းလမ်းတစ်ခုမှာ အောက်ပါအတိုင်း လုပ်ဆောင်သည့် ကျပန်းသစ်တောပုံစံကို တည်ဆောက်ခြင်းဖြစ်သည်-
1. မူရင်းဒေတာအတွဲမှ b bootstrapped နမူနာများကို ယူပါ။
2. bootstrap နမူနာတစ်ခုစီအတွက် ဆုံးဖြတ်ချက်သစ်တစ်ခုကို ဖန်တီးပါ။
- သစ်ပင်ကိုတည်ဆောက်သောအခါ၊ ခွဲခြမ်းခြင်းကိုထည့်သွင်းစဉ်းစားသည့်အခါတိုင်း၊ p ဟောကိန်းရှင်များ၏ ကျပန်းနမူနာများကိုသာ p ခန့်မှန်းသူများအစုအဝေးမှခွဲထုတ်ရန်အတွက် ကိုယ်စားလှယ်လောင်းများအဖြစ် သတ်မှတ်ခံရပါသည်။ ယေဘူယျအားဖြင့်၊ ကျွန်ုပ်တို့သည် m နှင့် ညီမျှသော √p ကို ရွေးသည်။
3. နောက်ဆုံးပုံစံတစ်ခုရရှိရန် သစ်ပင်တစ်ပင်စီမှ ခန့်မှန်းချက်များကို ပျမ်းမျှ။
ကျပန်းသစ်တောများသည် တစ်ခုတည်းသောဆုံးဖြတ်ချက်သစ်ပင်များနှင့် အိတ်စွပ်မော်ဒယ်များ ထက် များစွာပိုမိုတိကျသောပုံစံများကို ထုတ်လုပ်လေ့ရှိကြောင်း တွေ့ရှိရပါသည်။
ဤသင်ခန်းစာသည် R တွင်ဒေတာအစုံအတွက် ကျပန်းသစ်တောပုံစံတစ်ခုဖန်တီးပုံအဆင့်ဆင့်ကို ဥပမာပေးထားသည်။
အဆင့် 1- လိုအပ်သော ပက်ကေ့ခ်ျများကို တင်ပါ။
ပထမဦးစွာ၊ ဤဥပမာအတွက် လိုအပ်သော ပက်ကေ့ဂျ်များကို တင်ပါမည်။ ဤရိုးရှင်းသောဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် အထုပ်တစ်ခုသာ လိုအပ်သည်-
library (randomForest)
အဆင့် 2- ကျပန်းသစ်တောပုံစံကို ချိန်ညှိပါ။
ဤဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် လူတစ်ဦးချင်းရက်ပေါင်း 153 ရက်အတွင်း နယူးယောက်စီးတီးတွင် လေထုအရည်အသွေးကို တိုင်းတာမှုများပါရှိသော Air Quality ဟုခေါ်သော Built-in R ဒေတာအစုံကို အသုံးပြုပါမည်။
#view structure of air quality dataset str(airquality) 'data.frame': 153 obs. of 6 variables: $ Ozone: int 41 36 12 18 NA 28 23 19 8 NA ... $Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ... $ Wind: num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ... $ Temp: int 67 72 74 62 56 66 65 59 61 69 ... $Month: int 5 5 5 5 5 5 5 5 5 5 ... $Day: int 1 2 3 4 5 6 7 8 9 10 ... #find number of rows with missing values sum(! complete . cases (airquality)) [1] 42
ဤဒေတာအတွဲတွင် ပျောက်နေသောတန်ဖိုးများ 42 တန်းရှိသည်။ ထို့ကြောင့်၊ ကျပန်းသစ်တောပုံစံကို မတပ်ဆင်မီ၊ ကော်လံတစ်ခုစီတွင် ကော်လံ medians ဖြင့် ပျောက်ဆုံးနေသောတန်ဖိုးများကို ဖြည့်ပါလိမ့်မည်-
#replace NAs with column medians for (i in 1: ncol (air quality)) { airquality[,i][ is . na (airquality[, i])] <- median (airquality[, i], na . rm = TRUE ) }
ဆက်စပ်- R တွင် ပျောက်ဆုံးနေသောတန်ဖိုးများကို မည်သို့စွပ်စွဲမည်နည်း။
အောက်ဖော်ပြပါ ကုဒ်သည် randomForest ပက်ကေ့ခ်ျမှ randomForest() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ R တွင် ကျပန်းသစ်တောပုံစံကို မည်သို့အံဝင်ခွင်ကျဖြစ်စေရန် ဖော်ပြသည်။
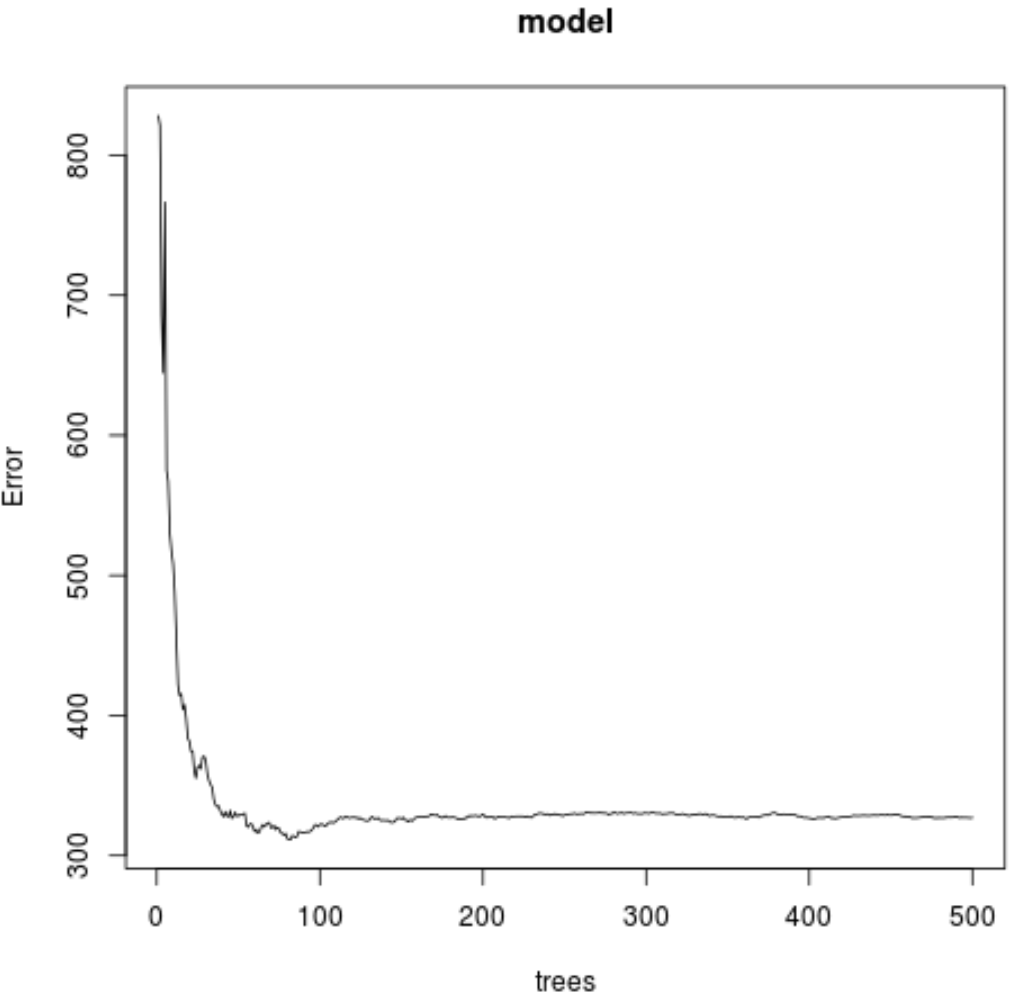
#make this example reproducible set.seed(1) #fit the random forest model model <- randomForest( formula = Ozone ~ ., data = airquality ) #display fitted model model Call: randomForest(formula = Ozone ~ ., data = airquality) Type of random forest: regression Number of trees: 500 No. of variables tried at each split: 1 Mean of squared residuals: 327.0914 % Var explained: 61 #find number of trees that produce lowest test MSE which.min(model$mse) [1] 82 #find RMSE of best model sqrt(model$mse[ which . min (model$mse)]) [1] 17.64392
ရလဒ်မှ၊ အနိမ့်ဆုံးစမ်းသပ်မှု mean square error (MSE) ကိုထုတ်လုပ်သည့်ပုံစံသည် သစ်ပင် 82 ပင်ကိုအသုံးပြုထားသည်ကိုကျွန်ုပ်တို့တွေ့မြင်နိုင်သည်။
ဤမော်ဒယ်၏ root mean square error သည် 17.64392 ဖြစ်သည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။ ၎င်းကို အိုဇုန်း၏ ခန့်မှန်းတန်ဖိုးနှင့် အမှန်တကယ် လေ့လာတွေ့ရှိထားသည့် တန်ဖိုးကြား ပျမ်းမျှ ကွာခြားချက်ဟု ကျွန်ုပ်တို့ ယူဆနိုင်သည်။
အသုံးပြုသောသစ်ပင်အရေအတွက်အပေါ်အခြေခံ၍ MSE စမ်းသပ်မှုအပိုင်းကိုထုတ်လုပ်ရန် အောက်ပါကုဒ်ကိုလည်း အသုံးပြုနိုင်သည်။
#plot the MSE test by number of trees
plot(model)
နောက်ဆုံးမော်ဒယ်ရှိ ကြိုတင်ခန့်မှန်းကိန်းရှင်တစ်ခုစီ၏ အရေးပါမှုကိုပြသသည့် ကွက်ကွက်တစ်ခုဖန်တီးရန် varImpPlot() လုပ်ဆောင်ချက်ကို ကျွန်ုပ်တို့အသုံးပြုနိုင်သည်-
#produce variable importance plot
varImpPlot(model)
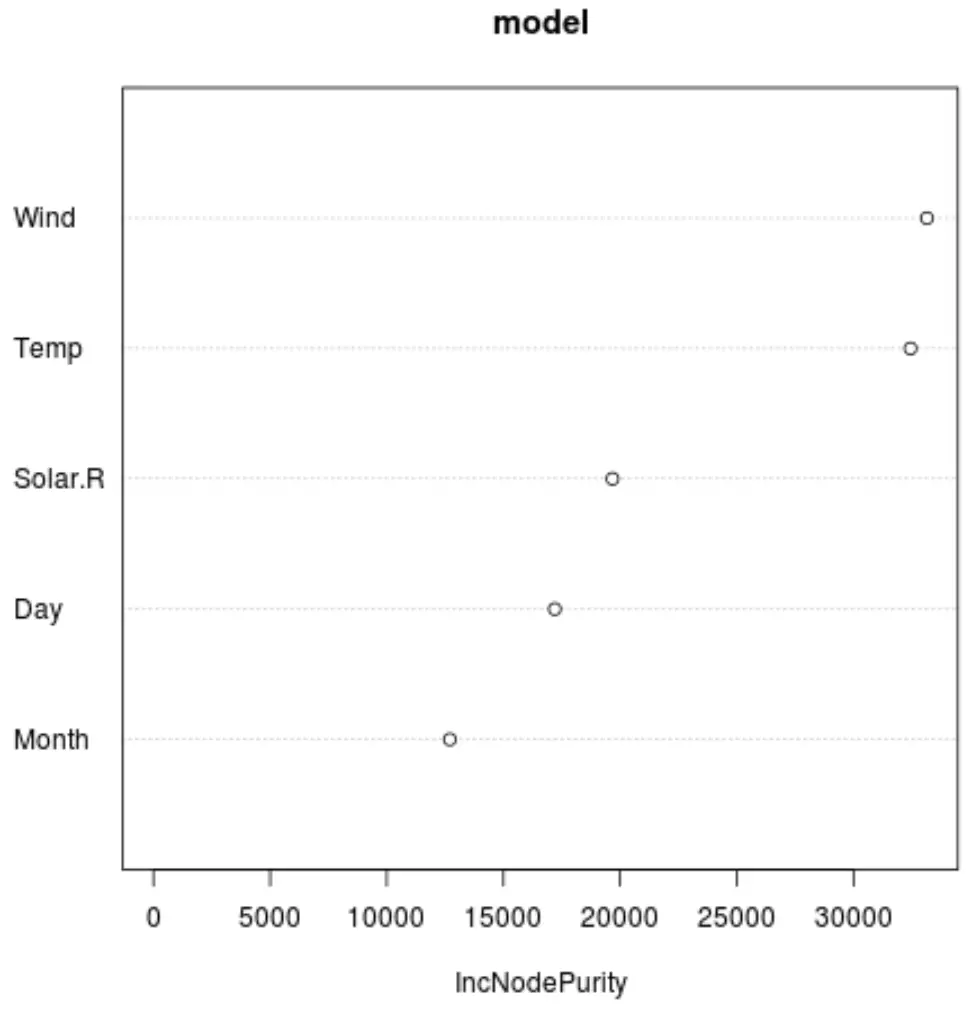
x-axis သည် y-ဝင်ရိုးပေါ်တွင်ပြသထားသော မတူညီသောကြိုတင်ခန့်မှန်းချက်များကိုဖြတ်၍ ပိုင်းခြားခြင်းလုပ်ဆောင်ချက်အဖြစ် regression သစ်ပင်များ၏ ပျမ်းမျှ node သန့်စင်မှုကို ပြသသည်။
ဂရပ်မှ၊ Wind သည် Temp ၏နောက်တွင် အရေးကြီးဆုံး ခန့်မှန်းချက်ကိန်းရှင်ဖြစ်သည်ကို ကျွန်ုပ်တို့တွေ့နိုင်သည်။
အဆင့် 3: မော်ဒယ်ကို ချိန်ညှိပါ။
ပုံမှန်အားဖြင့်၊ randomForest() လုပ်ဆောင်ချက်သည် သစ်ပင် 500 ကိုအသုံးပြုပြီး (စုစုပေါင်း ခန့်မှန်းသူများ/ 3) ခွဲခွဲတစ်ခုစီအတွက် ဖြစ်နိုင်ချေရှိသော ကိုယ်စားလှယ်လောင်းများအဖြစ် ကျပန်းရွေးချယ်ထားသော ခန့်မှန်းချက်များကို ကျပန်းရွေးချယ်သည်။ tuneRF() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ ဤဘောင်များကို ချိန်ညှိနိုင်သည်။
အောက်ဖော်ပြပါ ကုဒ်သည် အောက်ပါသတ်မှတ်ချက်များကို အသုံးပြု၍ အကောင်းဆုံးမော်ဒယ်ကို မည်သို့ရှာဖွေရမည်ကို ပြသသည်-
- ntreeTry: တည်ဆောက်ရန် သစ်ပင်အရေအတွက်။
- mtryStart- ဌာနခွဲတစ်ခုစီတွင် ထည့်သွင်းစဉ်းစားရန် ကနဦးကိန်းဂဏန်းကိန်းရှင်များ။
- အဆင့်သတ်မှတ်ချက်- ခန့်မှန်းခြေအိတ်ပြင်ပ အမှားအယွင်းသည် အချို့သောပမာဏဖြင့် တိုးတက်မလာမချင်း တိုးရန်အချက်။
- မြှင့်တင်ရန်- အဆင့်ကိန်းဂဏန်းကို ဆက်လက်တိုးမြှင့်ရန်အတွက် အိတ်ထွက်ပေါက်မှားယွင်းသည့်ပမာဏကို မြှင့်တင်ရမည်ဖြစ်သည်။
model_tuned <- tuneRF(
x=airquality[,-1], #define predictor variables
y=airquality$Ozone, #define response variable
ntreeTry= 500 ,
mtryStart= 4 ,
stepFactor= 1.5 ,
improve= 0.01 ,
trace= FALSE #don't show real-time progress
)
ဤလုပ်ဆောင်ချက်သည် x-ဝင်ရိုးပေါ်ရှိသစ်ပင်များတည်ဆောက်ရာတွင် ခွဲခြမ်းတစ်ခုစီတွင်အသုံးပြုသည့် ခန့်မှန်းကိန်းဂဏန်းအရေအတွက်နှင့် y-ဝင်ရိုးရှိ ခန့်မှန်းခြေအိတ်ပြင်ပအမှားကိုပြသသည့် အောက်ပါကွက်ကွက်ကို ထုတ်လုပ်ပေးသည်-
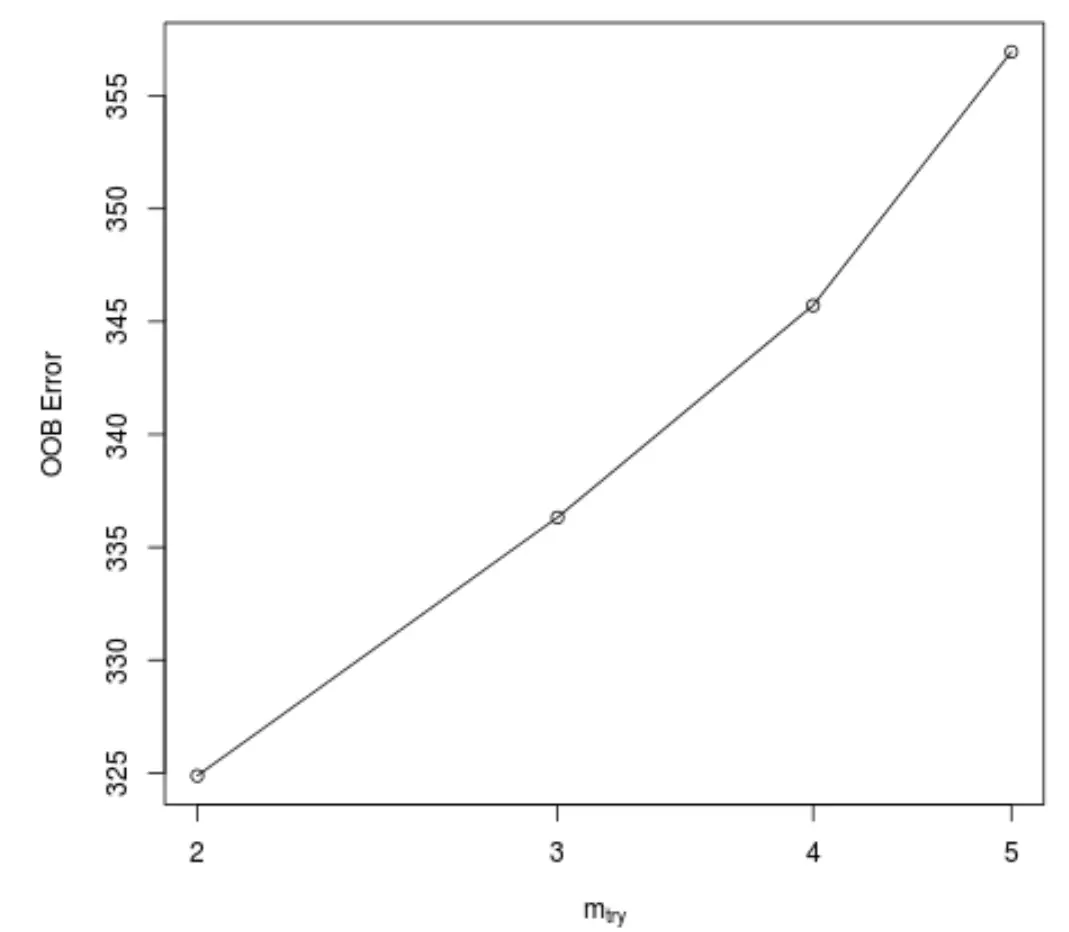
သစ်ပင်များတည်ဆောက်သောအခါတွင် ခွဲခြမ်းတစ်ခုစီတွင် ကျပန်းရွေးချယ်ထားသော ခန့်မှန်းသူ 2 ဦး ကို အသုံးပြုခြင်းဖြင့် အနိမ့်ဆုံး OOB error ကိုရရှိသည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။
၎င်းသည် အမှန်တကယ်တွင် ကနဦး randomForest() လုပ်ဆောင်ချက်မှ အသုံးပြုသည့် (စုစုပေါင်း ခန့်မှန်းသူများ/3 = 6/3 = 2) နှင့် ကိုက်ညီပါသည်။
အဆင့် 4- ခန့်မှန်းချက်များကို ပြုလုပ်ရန် နောက်ဆုံးပုံစံကို အသုံးပြုပါ။
နောက်ဆုံးတွင်၊ လေ့လာတွေ့ရှိချက်အသစ်များနှင့်ပတ်သက်၍ ခန့်မှန်းချက်များပြုလုပ်ရန် ချိန်ညှိထားသော ကျပန်းသစ်တောပုံစံကို အသုံးပြုနိုင်သည်။
#define new observation new <- data.frame(Solar.R=150, Wind=8, Temp=70, Month=5, Day=5) #use fitted bagged model to predict Ozone value of new observation predict(model, newdata=new) 27.19442
ကြိုတင်ခန့်မှန်းနိုင်သော ကိန်းရှင်များ၏ တန်ဖိုးများကို အခြေခံ၍ တပ်ဆင်ထားသော ကျပန်းသစ်တောပုံစံသည် ဤအထူးနေ့တွင် အိုဇုန်းတန်ဖိုး 27.19442 ဖြစ်မည်ဟု ခန့်မှန်းသည်။
ဤဥပမာတွင်အသုံးပြုသော R ကုဒ်အပြည့်အစုံကို ဤနေရာတွင် တွေ့နိုင်ပါသည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။