ကွဲလွဲမှုကို လေ့လာခြင်း (anova)
ဤဆောင်းပါးတွင် ANOVA ဟုလည်းသိကြသော ကွဲလွဲမှု၏ခွဲခြမ်းစိတ်ဖြာမှုအား စာရင်းဇယားတွင်ဖော်ပြထားသည်။ ထို့ကြောင့်၊ ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာနည်း၊ ANOVA ဇယားက ဘာလဲ၊ အဆင့်ဆင့်ဖြေရှင်းထားသော လေ့ကျင့်ခန်းကို သင်ရှာဖွေတွေ့ရှိပါလိမ့်မည်။ ထို့အပြင်၊ ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာရန် လေးစားရမည့်အရာများ နှင့် နောက်ဆုံးတွင် ANOVA ခွဲခြမ်းစိတ်ဖြာမှု၏ အားသာချက်များနှင့် အားနည်းချက်များကား အဘယ်နည်း။
ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာခြင်း (ANOVA) ဆိုသည်မှာ အဘယ်နည်း။
စာရင်းဇယားများတွင်၊ ANOVA (Analysis of Variance) ဟုခေါ်သော ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာခြင်း သည် မတူညီသောနမူနာများ၏ ကွဲပြားမှုများကို နှိုင်းယှဉ်ရန် ခွင့်ပြုသည့် နည်းလမ်းတစ်ခုဖြစ်သည်။
ကွဲလွဲမှု၏ ခွဲခြမ်းစိတ်ဖြာခြင်း (ANOVA) ကို လူဦးရေ နှစ်ခုထက်ပိုသော နည်းလမ်းများကြား ခြားနားချက်ရှိမရှိ ခွဲခြမ်းစိတ်ဖြာရန် အသုံးပြုသည်။ ထို့ကြောင့်၊ ကွဲလွဲမှု၏ခွဲခြမ်းစိတ်ဖြာမှုအား ခွဲခြမ်းစိတ်ဖြာခြင်းဖြင့် ကျွန်ုပ်တို့အား အုပ်စုနှစ်ခု သို့မဟုတ် ထို့ထက်ပိုသောလူဦးရေသည် ကွဲပြားမှုရှိမရှိကို နမူနာနည်းလမ်းများအကြား ကွဲပြားမှုကို ခွဲခြမ်းစိတ်ဖြာခြင်းဖြင့် ဆုံးဖြတ်နိုင်စေပါသည်။
ကွဲလွဲမှု၏ ခွဲခြမ်းစိတ်ဖြာမှု၏ null hypothesis သည် ခွဲခြမ်းစိတ်ဖြာထားသော အုပ်စုအားလုံး၏ အဓိပ္ပါယ်မှာ တူညီသည်ဟု ဆိုသည်။ အစားထိုးယူဆချက်က အနည်းဆုံး နည်းလမ်းတစ်ခုသည် ကွဲပြားသည်ဟု ခံယူထားသော်လည်း၊
![\begin{cases}H_0: \mu_1=\mu_2=\ldots=\mu_k=\mu\\[2ex]H_1: \exists \mu_i\neq \mu \quad i=1,2,\ldots, k\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-6918550a8ad2954432ea33e07c7b83d0_l3.png "Rendered by QuickLaTeX.com")
ထို့ကြောင့် ကွဲလွဲမှု၏ခွဲခြမ်းစိတ်ဖြာမှုသည် အုပ်စုနှစ်ခုထက်ပိုသောနည်းလမ်းများကို နှိုင်းယှဉ်ရန်အတွက် အထူးအသုံးဝင်သည်၊ အကြောင်းမှာ ဤခွဲခြမ်းစိတ်ဖြာမှုအမျိုးအစားဖြင့် အတွဲလိုက်ဆိုလိုသည်များကို နှိုင်းယှဉ်မည့်အစား အုပ်စုအားလုံး၏ဆိုလိုရင်းကို တစ်ပြိုင်တည်းလေ့လာနိုင်သောကြောင့်ဖြစ်သည်။ ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာခြင်း၏ အားသာချက်များနှင့် အားနည်းချက်များကို အောက်တွင် ကြည့်ရှုပါမည်။
ANOVA စားပွဲ
ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာခြင်းအား ANOVA table ဟုခေါ်သော ဇယားတစ်ခုတွင် အကျဉ်းချုပ်ဖော်ပြထားပြီး ယင်း၏ဖော်မြူလာများမှာ အောက်ပါအတိုင်းဖြစ်သည်။
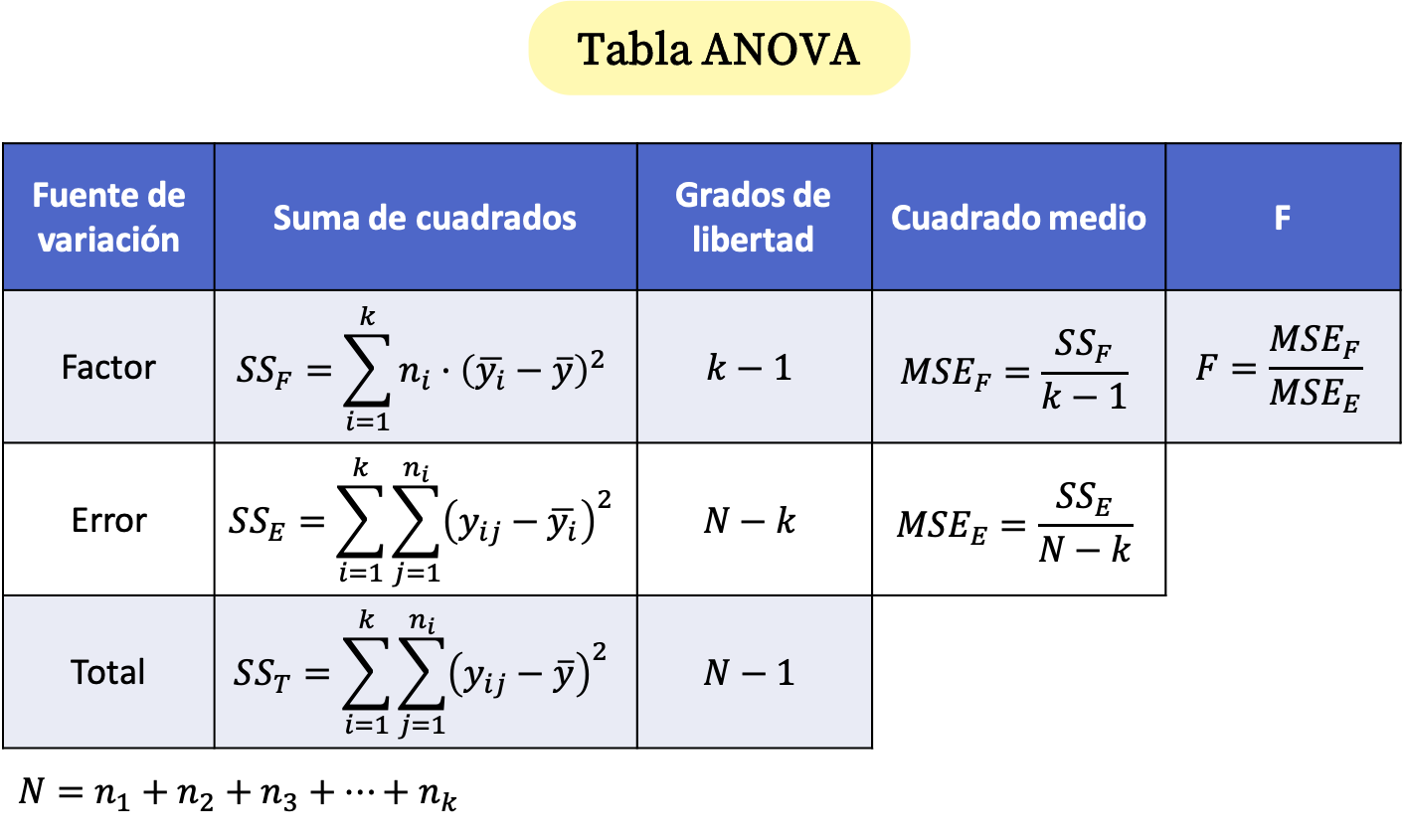
ရွှေ-
-

နမူနာအရွယ်အစား i ဖြစ်ပါတယ်။
-

လေ့လာချက် စုစုပေါင်း အရေအတွက် ဖြစ်ပါသည်။
-

ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာမှုတွင် မတူညီသောအုပ်စုများ၏ အရေအတွက်ဖြစ်သည်။
-

အုပ်စု i ၏တန်ဖိုးသည် j ဖြစ်သည်။
-

အုပ်စု i ၏ ဆိုလိုရင်းဖြစ်ပါသည်။
-

ဤသည်မှာ ခွဲခြမ်းစိတ်ဖြာထားသော အချက်အလက်အားလုံး၏ ပျမ်းမျှဖြစ်သည်။
ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာခြင်း ဥပမာ (ANOVA)
ANOVA ၏ သဘောတရားကို နားလည်သဘောပေါက်ရန် အပြီးသတ်ရန်အတွက် ဥပမာတစ်ခုကို တစ်ဆင့်ပြီးတစ်ဆင့် ဖြေရှင်းခြင်းဖြင့် ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာနည်းကို ကြည့်ကြပါစို့။
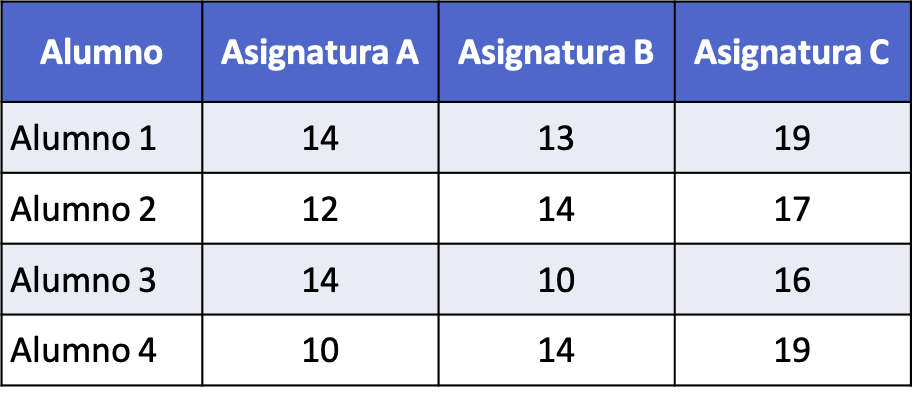
- မတူညီသောဘာသာရပ်သုံးခု (A၊ B နှင့် C) တွင် ကျောင်းသားလေးဦးမှ ရရှိသောရမှတ်များကို နှိုင်းယှဉ်ရန် စာရင်းအင်းလေ့လာမှုကို ပြုလုပ်ပါသည်။ အောက်ပါဇယားတွင် ကျောင်းသားတစ်ဦးစီမှ အများဆုံးရမှတ် 20 ဖြင့် စာမေးပွဲတစ်ခုတွင် ရရှိသောရမှတ်များကို အသေးစိတ်ဖော်ပြထားသည်။ ဘာသာရပ်တစ်ခုစီရှိ ကျောင်းသားတစ်ဦးစီမှရရှိသောရမှတ်များကို နှိုင်းယှဉ်ရန် ကွဲလွဲမှု၏ခွဲခြမ်းစိတ်ဖြာမှုတစ်ခုကို လုပ်ဆောင်ပါ။
ဤကွဲလွဲမှု၏ ခွဲခြမ်းစိတ်ဖြာမှု၏ null hypothesis မှာ ဘာသာရပ်သုံးခု၏ ရမှတ်များ၏ အဓိပ္ပါယ်သည် တူညီသည်ဟု ဆိုသည်။ အခြားတစ်ဖက်တွင်၊ null hypothesis သည် အချို့သောနည်းလမ်းများသည် ကွဲပြားသည်ဟု ဆိုသည်။
![\begin{cases}H_0: \mu_A=\mu_B=\mu_C=\mu\\[2ex]H_1: \exists \mu_i\neq \mu \quad i=A, B, C\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-d1587da405a54d6a2bae626989b04562_l3.png "Rendered by QuickLaTeX.com")
ကွဲလွဲမှု၏ခွဲခြမ်းစိတ်ဖြာမှုကို လုပ်ဆောင်ရန် ပထမဆုံးလုပ်ဆောင်ရမည့်အရာမှာ ဘာသာရပ်တစ်ခုစီ၏ပျမ်းမျှနှင့် ဒေတာစုစုပေါင်းပျမ်းမျှအား တွက်ချက်ရန်ဖြစ်သည်-




အဓိပ္ပာယ်၏တန်ဖိုးကို ကျွန်ုပ်တို့သိသည်နှင့်၊ အထက်တွင်ဖော်ပြထားသော ကွဲလွဲမှု (ANOVA) ဖော်မြူလာများကို ခွဲခြမ်းစိတ်ဖြာခြင်းဖြင့် ကျွန်ုပ်တို့သည် စတုရန်း၏ပေါင်းလဒ်များကို တွက်ချက်သည်-
![\begin{aligned}\displaystyle SS_F&=\sum_{i=1}^k n_i(\overline{y}_i-\overline{y})^2\\[2ex] SS_F&= 4\cdot (12,5-14,33)^2+4\cdot (12,75-14,33)^2+4\cdot (17,75-14,33)^2\\[2ex] SS_F&=70,17\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-77b3fecdc3b577841da684cd80297288_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_E=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y}_i)^2\\[2ex] \displaystyle SS_E=\ &(14-12,5)^2+(12-12,5)^2+(14-12,5)^2+(10-12,5)^2+\\&+(13-12,75)^2+(14-12,75)^2+(10-12,75)^2+(14-12,75)^2+\\&+(19-17,75)^2+(17-17,75)^2+(16-17,75)^2+(19-17,75)^2\\[2ex] SS_E=\ &28,50\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-aa02f1b826df45c26ead3537ecc4c7e5_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_T=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y})^2\\[2ex] \displaystyle SS_T= \ &(14-14,33)^2+(12-14,33)^2+(14-14,33)^2+(10-14,33)^2+\\&+(13-14,33)^2+(14-14,33)^2+(10-14,33)^2+(14-14,33)^2+\\&+(19-14,33)^2+(17-14,33)^2+(16-14,33)^2+(19-14,33)^2\\[2ex] SS_T= \ &98,67\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-2eb66d1d37653749f38916c905108a3b_l3.png "Rendered by QuickLaTeX.com")
ထို့နောက် အချက်၏ လွတ်လပ်မှုဒီဂရီ၊ အမှားနှင့် စုစုပေါင်းကို ဆုံးဖြတ်သည်-



ယခု ကျွန်ုပ်တို့သည် ကိန်းဂဏာန်းများ၏ နှစ်ထပ်ကိန်းများ နှင့် အမှားများကို ၎င်းတို့၏ လွတ်လပ်မှုဒီဂရီအလိုက် ပိုင်းခြားခြင်းဖြင့် ပျမ်းမျှ နှစ်ထပ်အမှားများကို တွက်ချက်သည်-


နောက်ဆုံးအနေနှင့်၊ ကျွန်ုပ်တို့သည် ယခင်အဆင့်တွင် တွက်ချက်ထားသော အမှားနှစ်ခုကို ပိုင်းခြားခြင်းဖြင့် F ကိန်းဂဏန်း၏တန်ဖိုးကို တွက်ချက်သည်-

အတိုချုပ်အားဖြင့်၊ ဥပမာဒေတာအတွက် ANOVA ဇယားသည် ဤကဲ့သို့ဖြစ်လိမ့်မည်-

ANOVA ဇယားရှိ တန်ဖိုးအားလုံးကို တွက်ချက်ပြီးသည်နှင့် ကျန်အားလုံးသည် ရရှိသောရလဒ်များကို အနက်ပြန်ဆိုရန်ဖြစ်သည်။ ဒါကိုလုပ်ဖို့၊ သက်ဆိုင်တဲ့လွတ်လပ်မှုဒီဂရီတွေနဲ့ Snedecor F ဖြန့်ဖြူးမှုမှာ F ကိန်းဂဏန်းထက်ကြီးတဲ့တန်ဖိုးကိုရရှိဖို့ ဖြစ်နိုင်ခြေကို ရှာဖို့လိုတယ်၊ ဆိုလိုတာကတော့ စာမေးပွဲရဲ့ p-value ကို ဆုံးဖြတ်ဖို့ လိုအပ်ပါတယ်-
![P[F>11,08]=0,004″ title=” Rendered by QuickLaTeX.com” height=” 18″ width=” 172″ style=” vertical-align: -5px;” ></p>
</p>
<p> ထို့ကြောင့်၊ အကယ်၍ ကျွန်ုပ်တို့သည် အရေးပါမှုအဆင့် α=0.05 (အသုံးအများဆုံး) ကိုယူပါက၊ ကျွန်ုပ်တို့သည် null hypothesis ကို ငြင်းပယ်ပြီး အခြား hypothesis ကို လက်ခံရမည်၊ အဘယ်ကြောင့်ဆိုသော် စမ်းသပ်မှု၏ p-value သည် အရေးပါမှုအဆင့်ထက် နိမ့်သောကြောင့် ဖြစ်သည်။ ဆိုလိုသည်မှာ အနည်းဆုံး လေ့လာထားသော အုပ်စုများ၏ အချို့သော နည်းလမ်းများသည် အခြားသူများနှင့် ကွဲပြားပါသည်။</p>
</p>
<p class=](https://statorials.org/wp-content/ql-cache/quicklatex.com-b706e5d710c3919d145399dc9d8efca5_l3.png)

ကွဲပြားမှုကို စက္ကန့်အနည်းငယ်အတွင်း ခွဲခြမ်းစိတ်ဖြာပေးနိုင်သော လက်ရှိ ကွန်ပျူတာပရိုဂရမ်များစွာ ရှိကြောင်း သတိပြုသင့်သည်။ သို့သော် တွက်ချက်မှုနောက်ကွယ်မှ သီအိုရီကို သိရန်လည်း အရေးကြီးပါသည်။
Variance of Analysis (ANOVA) ၏ ယူဆချက်များ
ကွဲလွဲမှု (ANOVA) ခွဲခြမ်းစိတ်ဖြာမှုကို လုပ်ဆောင်ရန်အတွက် အောက်ပါအခြေအနေများကို ဖြည့်ဆည်းပေးရမည်-
- လွတ်လပ်ရေး : သတိပြုမိသော တန်ဖိုးများသည် တစ်ခုနှင့်တစ်ခု အမှီအခိုကင်းသည်။ လေ့လာဆန်းစစ်မှုများ၏လွတ်လပ်မှုကိုသေချာစေရန်နည်းလမ်းတစ်ခုမှာ နမူနာကောက်ယူခြင်းလုပ်ငန်းစဉ်တွင် ကျပန်းထည့်သွင်းခြင်းပင်ဖြစ်သည်။
- Homoscedasticity : ကွဲလွဲမှုများတွင် တူညီမှုရှိရမည်၊ ဆိုလိုသည်မှာ အကြွင်းအကျန်များ၏ ကွဲပြားမှုသည် ကိန်းသေဖြစ်သည်။
- Normality : ကျန်အကြွင်းများကို ပုံမှန်ဖြန့်ဝေသင့်သည် သို့မဟုတ် တစ်နည်းအားဖြင့် ၎င်းတို့သည် ပုံမှန်ဖြန့်ဝေမှုအတိုင်း လုပ်ဆောင်သင့်သည်။
- Continuity : မှီခိုသော ကိန်းရှင်သည် စဉ်ဆက်မပြတ် ဖြစ်နေရမည်။
Variance of Analysis (ANOVA) အမျိုးအစားများ
ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာခြင်း (ANOVA) ဟူ၍ သုံးမျိုးရှိသည် ။
- ကွဲလွဲမှု၏ တစ်လမ်းသွား ခွဲခြမ်းစိတ်ဖြာမှု (one-way ANOVA) : ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာရာတွင်၊ ကွဲလွဲမှု၏ ခွဲခြမ်းစိတ်ဖြာမှုတွင် အချက်တစ်ချက်သာ ရှိသည်၊ ဆိုလိုသည်မှာ လွတ်လပ်သော ကိန်းရှင်တစ်ခုသာ ရှိပါသည်။
- ကွဲလွဲမှုကို နှစ်လမ်းခွဲခွဲခြမ်းစိတ်ဖြာခြင်း ( two-way ANOVA ) : ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာခြင်းတွင် အချက်နှစ်ချက်ရှိသည်၊ ထို့ကြောင့် အမှီအခိုကင်းသော ကိန်းရှင်နှစ်ခုနှင့် ၎င်းတို့ကြား အပြန်အလှန်အကျိုးသက်ရောက်မှုကို ခွဲခြမ်းစိတ်ဖြာသည်။
- ကွဲလွဲမှုအမျိုးမျိုးကို ခွဲခြမ်းစိတ်ဖြာခြင်း (MANOVA) – ကွဲလွဲမှုကို ခွဲခြမ်းစိတ်ဖြာမှုတွင် မှီခိုပြောင်းလဲနိုင်သော ကိန်းရှင်တစ်ခုထက်ပိုပါသည်။ ရည်ရွယ်ချက်မှာ အမှီအခိုကင်းသော ကိန်းရှင်များသည် ၎င်းတို့၏တန်ဖိုးကို ပြောင်းလဲခြင်းရှိမရှိ ဆုံးဖြတ်ရန်ဖြစ်သည်။
Variance of Analysis (ANOVA) ၏ အားသာချက်များနှင့် အားနည်းချက်များ
နောက်ဆုံးတွင်၊ ကွဲလွဲမှု၏ခွဲခြမ်းစိတ်ဖြာမှုကို အသုံးပြုရန် ကျွန်ုပ်တို့အတွက် သင့်လျော်သည့်အခါတွင်၊ ဤစာရင်းအင်းခွဲခြမ်းစိတ်ဖြာမှုအမျိုးအစား၏ ကန့်သတ်ချက်များမှာလည်း အဘယ်နည်း။
ကွဲလွဲမှု (ANOVA) ကို ခွဲခြမ်းစိတ်ဖြာခြင်း၏ အဓိကအားသာချက်မှာ အုပ်စုနှစ်ခုထက်ပို၍ တစ်ချိန်တည်းတွင် နှိုင်းယှဉ်နိုင်စေခြင်းဖြစ်ပါသည်။ နမူနာတစ်ခု သို့မဟုတ် နှစ်ခုသာ ခွဲခြမ်းစိတ်ဖြာနိုင်သည့် t-test နှင့်မတူဘဲ လူဦးရေအများအပြားသည် တူညီသောဆိုလိုရင်းရှိမရှိ ဆုံးဖြတ်ရန် ကွဲလွဲမှု၏ခွဲခြမ်းစိတ်ဖြာမှုကို အသုံးပြုပါသည်။
သို့ရာတွင်၊ ကွဲလွဲမှု၏ခွဲခြမ်းစိတ်ဖြာမှုသည် မည်သည့်လေ့လာမှုအုပ်စုတွင် ကွဲပြားသောအဓိပ္ပာယ်ရှိသနည်း၊ ၎င်းသည် ကျွန်ုပ်တို့အား သိသာထင်ရှားစွာကွဲပြားသောနည်းလမ်းများ ရှိမရှိ သို့မဟုတ် အားလုံးတူညီမှုရှိမရှိကိုသာ သိစေပါသည်။
အလားတူ၊ ကွဲလွဲမှု၏ခွဲခြမ်းစိတ်ဖြာမှု၏နောက်ထပ်အားနည်းချက်မှာ ANOVA ခွဲခြမ်းစိတ်ဖြာမှုကိုလုပ်ဆောင်ရန်အတွက် ယခင်ယူဆချက်လေးခု (အထက်တွင်ကြည့်ပါ) နှင့်ကိုက်ညီရမည်ဖြစ်သည်၊ မဟုတ်ပါက ကောက်ချက်ဆွဲမှားနိုင်သည်။ ထို့ကြောင့်၊ စာရင်းအင်းဒေတာအတွဲသည် ဤလိုအပ်ချက်လေးရပ်နှင့် ကိုက်ညီမှုရှိမရှိ အမြဲစစ်ဆေးသင့်သည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။