Machine learning တွင် မည်သည် အံဝင်ခွင်ကျဖြစ်သနည်း။ (ရှင်းလင်းချက်နှင့် ဥပမာများ)
စက်သင်ယူမှုတွင်၊ အချို့သောဖြစ်ရပ်များနှင့် ပတ်သက်၍ တိကျသောခန့်မှန်းချက်များကို ပြုလုပ်နိုင်စေရန်အတွက် ကျွန်ုပ်တို့သည် မော်ဒယ်များကို မကြာခဏတည်ဆောက်ပါသည်။
ဥပမာအားဖြင့်၊ အထက်တန်းကျောင်းသူကျောင်းသားများအတွက် တုံ့ပြန်မှုကိန်းရှင်၏ ACT ရမှတ်ကို ခန့်မှန်းရန် လေ့လာနေခဲ့သော ခန့်မှန်းကိန်းရှင် variable နာရီများကို အသုံးပြုသည့် ဆုတ်ယုတ်မှုပုံစံ ကို ဖန်တီးလိုသည်ဆိုပါစို့။
ဤပုံစံကို တည်ဆောက်ရန်အတွက်၊ ကျောင်းခရိုင်တစ်ခုရှိ ကျောင်းသားရာနှင့်ချီအတွက် သက်ဆိုင်သော ACT ရမှတ်များကို လေ့လာသည့် နာရီများနှင့် သက်ဆိုင်သည့် အချက်အလက်များကို စုဆောင်းပါမည်။
ထို့နောက် သင်ကြားခဲ့သည့် စုစုပေါင်းနာရီအရေအတွက်အပေါ် အခြေခံ၍ ပေးထားသည့် ကျောင်းသားရရှိမည့်ရမှတ်နှင့်ပတ်သက်၍ ခန့်မှန်းချက်များကို ခန့်မှန်းနိုင်သည့် မော်ဒယ်တစ်ခုကို လေ့ကျင့် ရန် ဤဒေတာကို အသုံးပြုပါမည်။
မော်ဒယ်၏ အသုံးဝင်မှုကို အကဲဖြတ်ရန်၊ ကျွန်ုပ်တို့သည် မော်ဒယ်၏ ခန့်မှန်းချက်များသည် စောင့်ကြည့်လေ့လာထားသော အချက်အလက်နှင့် မည်မျှကိုက်ညီကြောင်း တိုင်းတာနိုင်ပါသည်။ ၎င်းကိုလုပ်ဆောင်ရန် အသုံးအများဆုံး မက်ထရစ်များထဲမှ တစ်ခုသည် အောက်ပါအတိုင်း တွက်ချက်ထားသည့် mean square error (MSE) ဖြစ်သည်။
MSE = (1/n)*Σ(y i – f(x i )) ၂
ရွှေ-
- n- လေ့လာတွေ့ရှိချက်စုစုပေါင်း
- y i : IT Observation ၏ တုံ့ပြန်မှုတန်ဖိုး
- f(x i ): i th observation ၏ ခန့်မှန်းထားသော တုံ့ပြန်မှုတန်ဖိုး
မော်ဒယ်ခန့်မှန်းချက်များသည် စောင့်ကြည့်မှုများနှင့် နီးကပ်လေ၊ MSE သည် နိမ့်လေဖြစ်သည်။
သို့သော်လည်း စက်သင်ယူမှုတွင် ပြုလုပ်ခဲ့သော အကြီးမားဆုံးအမှားတစ်ခုမှာ MSE လေ့ကျင့်မှုကို လျှော့ချရန် မော်ဒယ်များကို အကောင်းဆုံးဖြစ်အောင် ပြုလုပ်ခြင်းဖြစ်ပြီး၊ ဆိုလိုသည်မှာ၊ မော်ဒယ်ခန့်မှန်းချက်များသည် ကျွန်ုပ်တို့လေ့ကျင့်ပေးထားသည့် မော်ဒယ်ဒေတာနှင့် မည်မျှကိုက်ညီမှုရှိသည်လဲ။
မော်ဒယ်တစ်ခုသည် လေ့ကျင့်ရေး MSE ကို လျှော့ချရန် အလွန်အကျွံ အာရုံစိုက်သောအခါ၊ အခွင့်အလမ်းကြောင့် ရိုးရှင်းသော လေ့ကျင့်မှုဒေတာတွင် ပုံစံများကို ရှာဖွေရန် အလွန်ခက်ခဲလေ့ရှိသည်။ ထို့နောက် မော်ဒယ်ကို မမြင်ရသော ဒေတာများတွင် အသုံးပြုသောအခါ၊ ၎င်း၏ စွမ်းဆောင်ရည်မှာ ညံ့ဖျင်းပါသည်။
ဤဖြစ်စဉ်ကို overfitting ဟုခေါ်သည်။ ကျွန်ုပ်တို့သည် လေ့ကျင့်ရေးဒေတာနှင့် အလွန်နီးကပ်စွာ “မော်ဒယ်” ကို အံကိုက်ဖြစ်ပြီး ဒေတာအသစ်တွင် ခန့်မှန်းမှုများပြုလုပ်ရန်အတွက် အသုံးမဝင်သော မော်ဒယ်တစ်ခုကို တည်ဆောက်သည့်အခါ ၎င်းသည် ဖြစ်ပေါ်လာပါသည်။
Overfitting ဥပမာ
အံဝင်ခွင်ကျဖြစ်မှုကို နားလည်ရန်၊ ACT ရမှတ်ကို ခန့်မှန်းရန် နာရီများစွာကြာ လေ့လာခဲ့သော ဆုတ်ယုတ်မှုပုံစံကို ဖန်တီးခြင်း၏ ဥပမာကို ပြန်ကြည့်ကြပါစို့။
အချို့သောကျောင်းခရိုင်ရှိ ကျောင်းသား 100 အတွက် ဒေတာကို စုဆောင်းပြီး ကိန်းရှင်နှစ်ခုကြားရှိ ဆက်စပ်မှုကို မြင်သာစေရန် အမြန်ခွဲခြမ်းစိတ်ဖြာမှုတစ်ခုကို ဖန်တီးပါစို့။
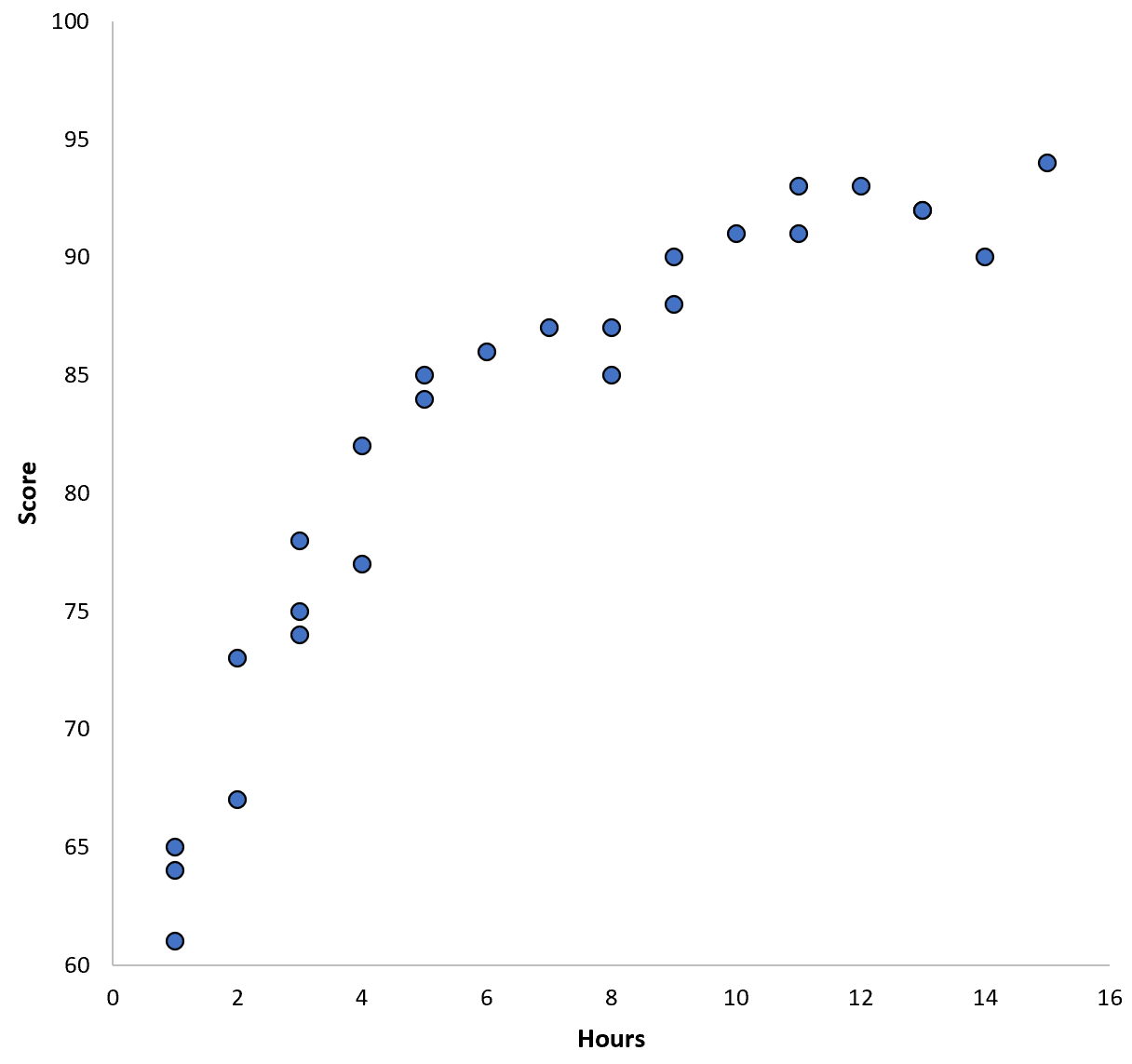
ကိန်းရှင်နှစ်ခုကြားရှိ ဆက်စပ်မှုသည် လေးထောင့်ပုံသဏ္ဍာန်ဖြစ်ပြီး၊ ထို့ကြောင့် ကျွန်ုပ်တို့သည် အောက်ဖော်ပြပါ လေးပုံတပုံ ဆုတ်ယုတ်မှုပုံစံကို အသုံးပြုသည်ဆိုပါစို့။
ရမှတ် = 60.1 + 5.4*(နာရီ) – 0.2*(နာရီ) 2
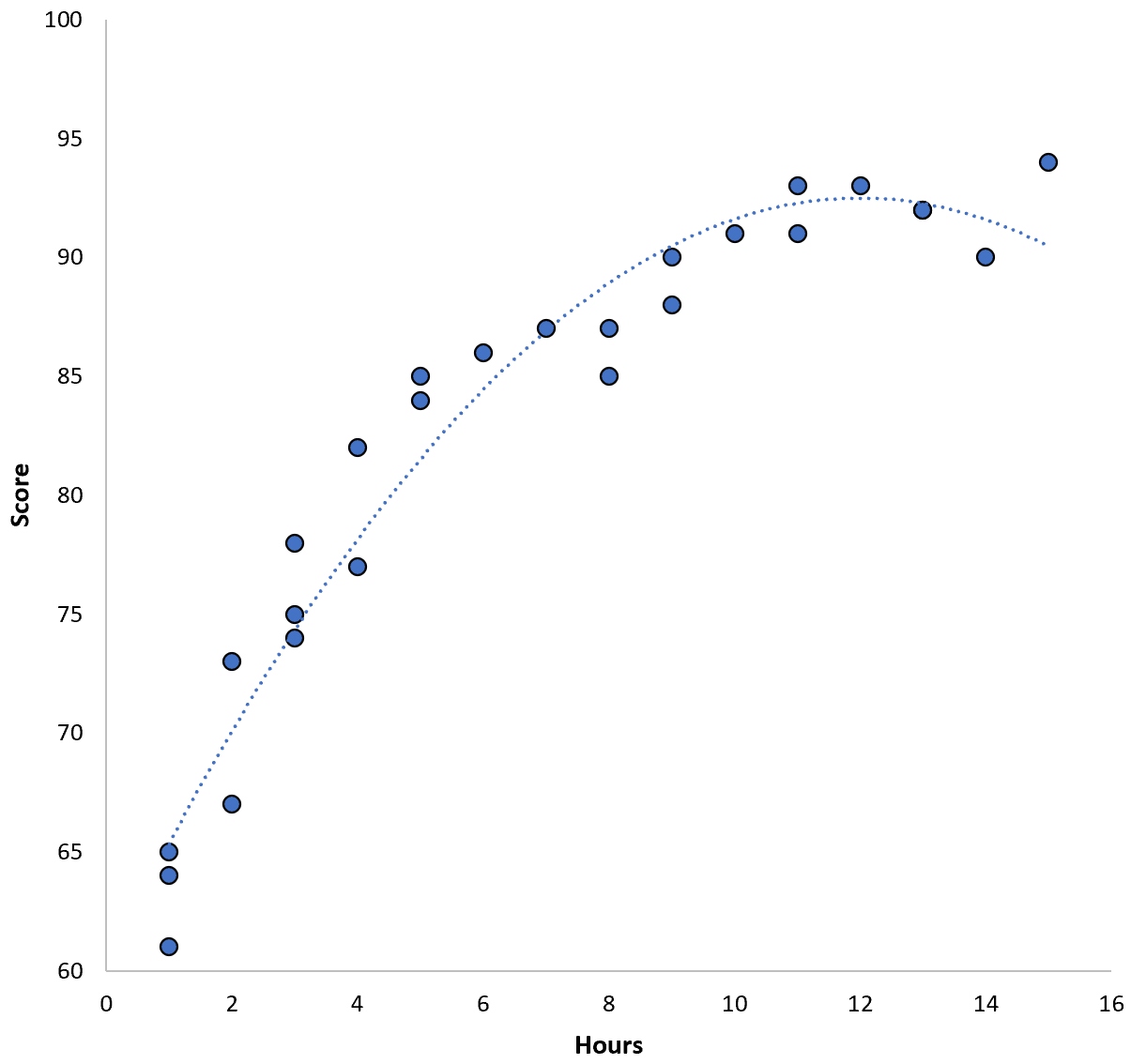
ဤမော်ဒယ်တွင် လေ့ကျင့်ရေးပျမ်းမျှစတုရန်းအမှား (MSE) 3.45 ရှိသည်။ ဆိုလိုသည်မှာ၊ မော်ဒယ်မှပြုလုပ်သော ခန့်မှန်းချက်များနှင့် အမှန်တကယ် ACT ရမှတ်များကြားတွင် root mean စတုရန်းကွာခြားချက်မှာ 3.45 ဖြစ်သည်။
သို့သော်၊ ကျွန်ုပ်တို့သည် ပိုမိုမြင့်မားသော အစီအစဥ်များစွာကို စံနမူနာပြု၍ ဤသင်တန်း MSE ကို လျှော့ချနိုင်သည်။ ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့သည် အောက်ပါပုံစံကို အသုံးပြုသည်ဆိုပါစို့။
ရမှတ် = 64.3 – 7.1*(နာရီ) + 8.1*(နာရီ) 2 – 2.1*(နာရီ) 3 + 0.2*(နာရီ ) 4 – 0.1*(နာရီ) 5 + 0.2(နာရီ) 6
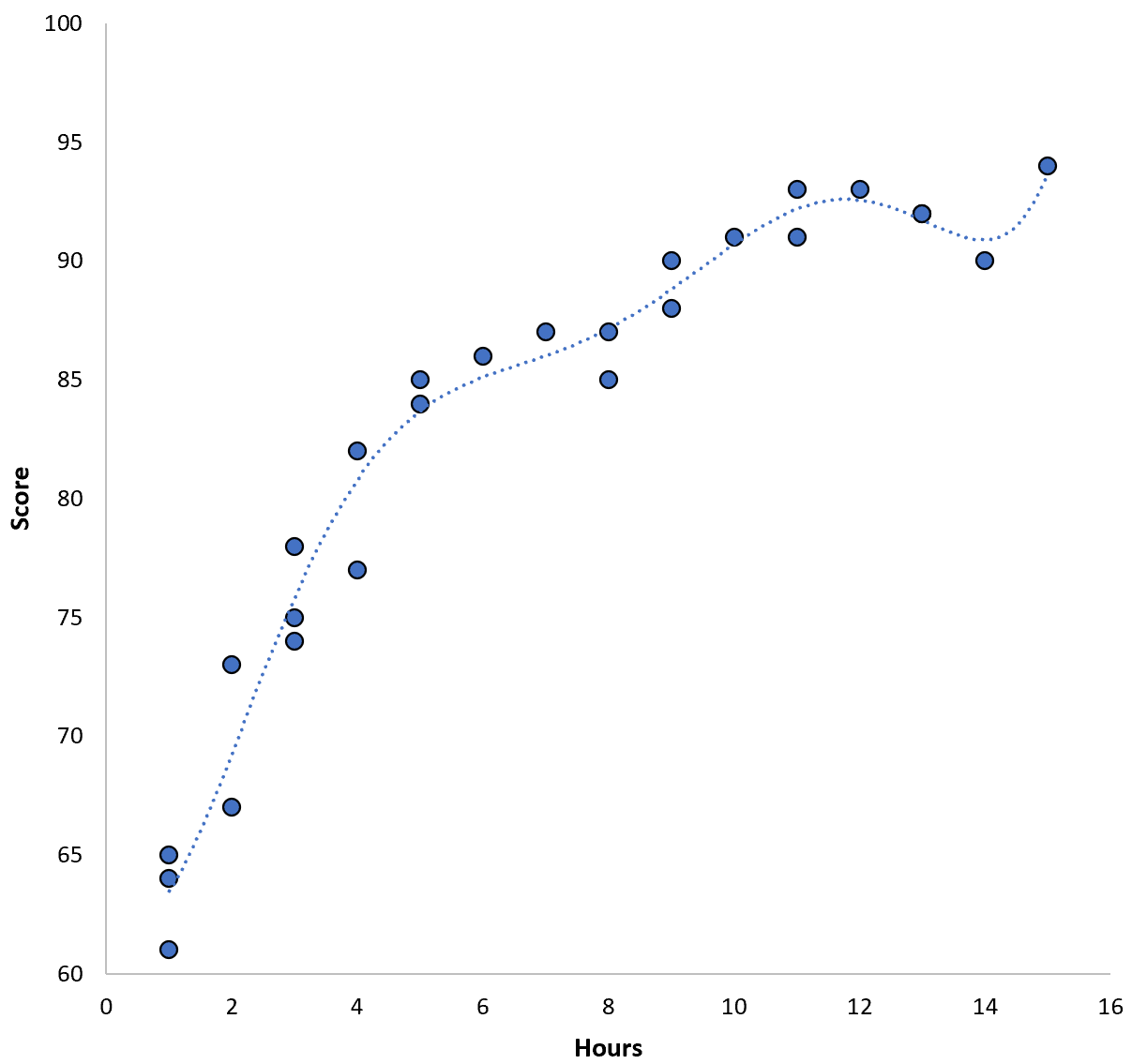
regression line သည် ယခင် regression line ထက် အမှန်တကယ် data နှင့် ပိုမိုနီးစပ်ပုံကို သတိပြုပါ။
ဤမော်ဒယ်တွင် လေ့ကျင့်ရေး root mean square error (MSE) သည် 0.89 သာရှိသည်။ ဆိုလိုသည်မှာ၊ မော်ဒယ်မှပြုလုပ်သော ခန့်မှန်းမှုများနှင့် အမှန်တကယ် ACT ရမှတ်များကြားတွင် root mean စတုရန်းကွာခြားချက်မှာ 0.89 ဖြစ်သည်။
ဤ MSE သင်တန်းသည် ယခင်မော်ဒယ်ထက် များစွာသေးငယ်ပါသည်။
သို့သော်၊ လေ့ကျင့်ရေး MSE ကို ကျွန်ုပ်တို့ သိပ်ဂရုမစိုက်ပါ ၊ ဆိုလိုသည်မှာ မော်ဒယ်၏ ခန့်မှန်းချက်များသည် မော်ဒယ်ကို လေ့ကျင့်ရန် အသုံးပြုခဲ့သည့် အချက်အလက်နှင့် မည်မျှ ကိုက်ညီသည် ။ ယင်းအစား၊ ကျွန်ုပ်တို့သည် ကျွန်ုပ်တို့၏မော်ဒယ်ကို မမြင်ရသောဒေတာအတွက် အသုံးပြုသည့်အခါ MSE စမ်းသပ်မှုကို အဓိကအာရုံစိုက်ပါသည်။
ကျွန်ုပ်တို့သည် အထက်တွင်ဖော်ပြထားသော ပိုမိုများပြားသော အစီအစဥ်ပိုလီနီယမ်ဆုတ်ယုတ်မှုပုံစံကို မမြင်ရသောဒေတာအတွဲတစ်ခုတွင် အသုံးပြုပါက၊ ၎င်းသည် ပိုမိုရိုးရှင်းသော လေးထောင့်ပုံစံဆုတ်ယုတ်မှုပုံစံထက် ပိုမိုလုပ်ဆောင်နိုင်ဖွယ်ရှိသည်။ ဆိုလိုသည်မှာ၊ ၎င်းသည်ကျွန်ုပ်တို့မလိုလားသောအရာအတိအကျဖြစ်သည့်ပိုမိုမြင့်မားသော MSE စာမေးပွဲကိုထုတ်လုပ်လိမ့်မည်။
အလွန်အကျွံမဖြစ်အောင် ဘယ်လိုရှာဖွေမလဲ။
Overfitting ကိုရှာဖွေရန် အရိုးရှင်းဆုံးနည်းလမ်းမှာ cross-validation ပြုလုပ်ခြင်းဖြစ်သည်။ အသုံးအများဆုံးနည်းလမ်းကို k-fold cross-validation ဟုခေါ်ပြီး အောက်ပါအတိုင်း လုပ်ဆောင်သည်။
အဆင့် 1- ခန့်မှန်းခြေ တူညီသော အရွယ်အစားရှိသော k အုပ်စုများ သို့မဟုတ် “ folds” တွင် သတ်မှတ်ထားသော ဒေတာကို ကျပန်းခွဲပါ။

အဆင့် 2- သင်၏ကိုင်ဆောင်ထားသည့်အစုံအဖြစ် ခေါက်များထဲမှ တစ်ခုကို ရွေးပါ။ နမူနာကို ကျန် k-1 ခေါက်သို့ ချိန်ညှိပါ။ တင်းမာနေသော အထပ်တွင် လေ့လာတွေ့ရှိချက်များကို MSE စာမေးပွဲကို တွက်ချက်ပါ။

အဆင့် 3- ဤလုပ်ငန်းစဉ် k ကြိမ်ကို ဖယ်ထုတ်ခြင်းအဖြစ် မတူညီသောအစုံကို အသုံးပြုပြီးတိုင်း၊ အကြိမ်တိုင်း ပြန်လုပ်ပါ။

အဆင့် 4- စာမေးပွဲ၏ k MSE ပျမ်းမျှအဖြစ် စာမေးပွဲ၏ အလုံးစုံ MSE ကို တွက်ချက်ပါ။
စမ်းသပ်ခြင်း MSE = (1/k)*ΣMSE i
ရွှေ-
- k: ခေါက်အရေအတွက်
- MSE i : iteration တွင် MSE ကို စမ်းသပ်ပါ။
ဤ MSE စစ်ဆေးမှုသည် ကျွန်ုပ်တို့အား ပေးထားသောမော်ဒယ်သည် အမည်မသိဒေတာအပေါ် မည်သို့လုပ်ဆောင်မည်ကို အကြံကောင်းပေးသည်။
လက်တွေ့တွင်၊ ကျွန်ုပ်တို့သည် မတူညီသော မော်ဒယ်များစွာကို အံဝင်ခွင်ကျဖြစ်စေနိုင်ပြီး ၎င်း၏ MSE စမ်းသပ်မှုကို သိရှိရန် မော်ဒယ်တစ်ခုစီတွင် k-fold အပြန်အလှန် validation ပြုလုပ်နိုင်သည်။ ထို့နောက် အနာဂတ်တွင် ခန့်မှန်းချက်များကို ပြုလုပ်ရန်အတွက် အသုံးပြုရန် အနိမ့်ဆုံး MSE စမ်းသပ်မှုဖြင့် မော်ဒယ်ကို ကျွန်ုပ်တို့ ရွေးချယ်နိုင်ပါသည်။
၎င်းသည် ကျွန်ုပ်တို့သည် လေ့ကျင့်ရေး MSE ကို နည်းပါးစေပြီး သမိုင်းအချက်အလက်နှင့် “အံဝင်ခွင်ကျ” သော မော်ဒယ်နှင့် ဆန့်ကျင်ဘက်အနေဖြင့် အနာဂတ်ဒေတာတွင် အကောင်းဆုံးလုပ်ဆောင်နိုင်ဖွယ်ရှိသည့် မော်ဒယ်ကို ရွေးချယ်ထားကြောင်း သေချာစေသည်။
ထပ်လောင်းအရင်းအမြစ်များ
စက်သင်ယူမှုတွင် ဘက်လိုက်မှုကွဲလွဲမှု အပေးအယူသည် အဘယ်နည်း။
K-Fold Cross-Validation နိဒါန်း
စက်သင်ယူမှုတွင် ဆုတ်ယုတ်မှုနှင့် အမျိုးအစားခွဲခြားမှုပုံစံများ
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။