Sas တွင် qq ကွက်ကွက်ဖန်တီးနည်း
“quantile-quantile” ၏ အတိုကောက်ဖြစ်သော QQ ကွက်ကွက် တစ်ခုအား ဒေတာအတွဲတစ်ခုသည် သီအိုရီအရ ဖြန့်ဝေမှုမှ ဖြစ်နိုင်ချေရှိမရှိ အကဲဖြတ်ရန် အသုံးပြုသည်။
ကိစ္စအများစုတွင်၊ ဒေတာအစုံသည် ပုံမှန်ဖြန့်ဝေမှုနောက်သို့လိုက်ခြင်းရှိ၊ မရှိ ဆုံးဖြတ်ရန် ဤကွက်အမျိုးအစားကို အသုံးပြုသည်။
ဒေတာကို ပုံမှန်အတိုင်း ဖြန့်ဝေပါက၊ QQ ကွက်ကွက်ရှိ အမှတ်များသည် ဖြောင့်သောထောင့်ဖြတ်မျဉ်းပေါ်တွင် ရှိနေမည်ဖြစ်သည်။
အပြန်အလှန်အားဖြင့်၊ ဂရပ်ပေါ်ရှိ အမှတ်များသည် ဖြောင့်ထောင့်ဖြတ်မျဉ်းမှ သွေဖည်သွားလေ၊ ဒေတာအစုံသည် ပုံမှန်ဖြန့်ဝေမှုနောက်သို့ လိုက်ရန် ဖြစ်နိုင်ခြေနည်းလေဖြစ်သည်။
SAS တွင် QQ ကွက်ကွက်ဖန်တီးရန် အလွယ်ကူဆုံးနည်းလမ်းမှာ QQPLOT ထုတ်ပြန်ချက်နှင့်အတူ PROC UNIVARIATE ထုတ်ပြန်ချက်ကို အသုံးပြုရန်ဖြစ်သည်။
proc univariate data =my_data noprint ; qqplot my_variable; run ;
အောက်ပါဥပမာများသည် ဤ syntax ကိုလက်တွေ့တွင်မည်သို့အသုံးပြုရမည်ကိုပြသထားသည်။
မှတ်ချက် – PROC UNIVARIATE ထုတ်ပြန်ချက်မှ အလိုအလျောက်ထုတ်ပေးသည့် အခြားအကျဉ်းချုပ်စာရင်းဇယားများနှင့် ဇယားအားလုံးကို ဖယ်ရှားရန် ကျွန်ုပ်တို့သည် NOPRINT ထုတ်ပြန်ချက်ကို အသုံးပြုပါသည်။
ဥပမာ 1- ပုံမှန်ဒေတာအတွက် SAS တွင် QQ ကွက်တစ်ခု ဖန်တီးပါ။
အောက်ဖော်ပြပါ ကုဒ်သည် ပုံမှန်ဖြန့်ဝေမှု မှ ပျမ်းမျှ 10 နှင့် 2 ၏ စံသွေဖည်မှု 1000 ပါ၀င်သော လေ့လာတွေ့ရှိချက် 1000 ပါရှိသော ဒေတာအတွဲအတွက် QQ ကွက်ကွက်ဖန်တီးနည်းကို ပြသသည်-
/*generate 1000 values that follow normal distribution with mean 10 and sd 2 */
data normal_data;
do i = 1 to 1000;
x = 10 + 2* rannor (1);
output ;
end ;
run ;
/*create some plot*/
proc univariate data =normal_data noprint ;
qqplot x;
run ;
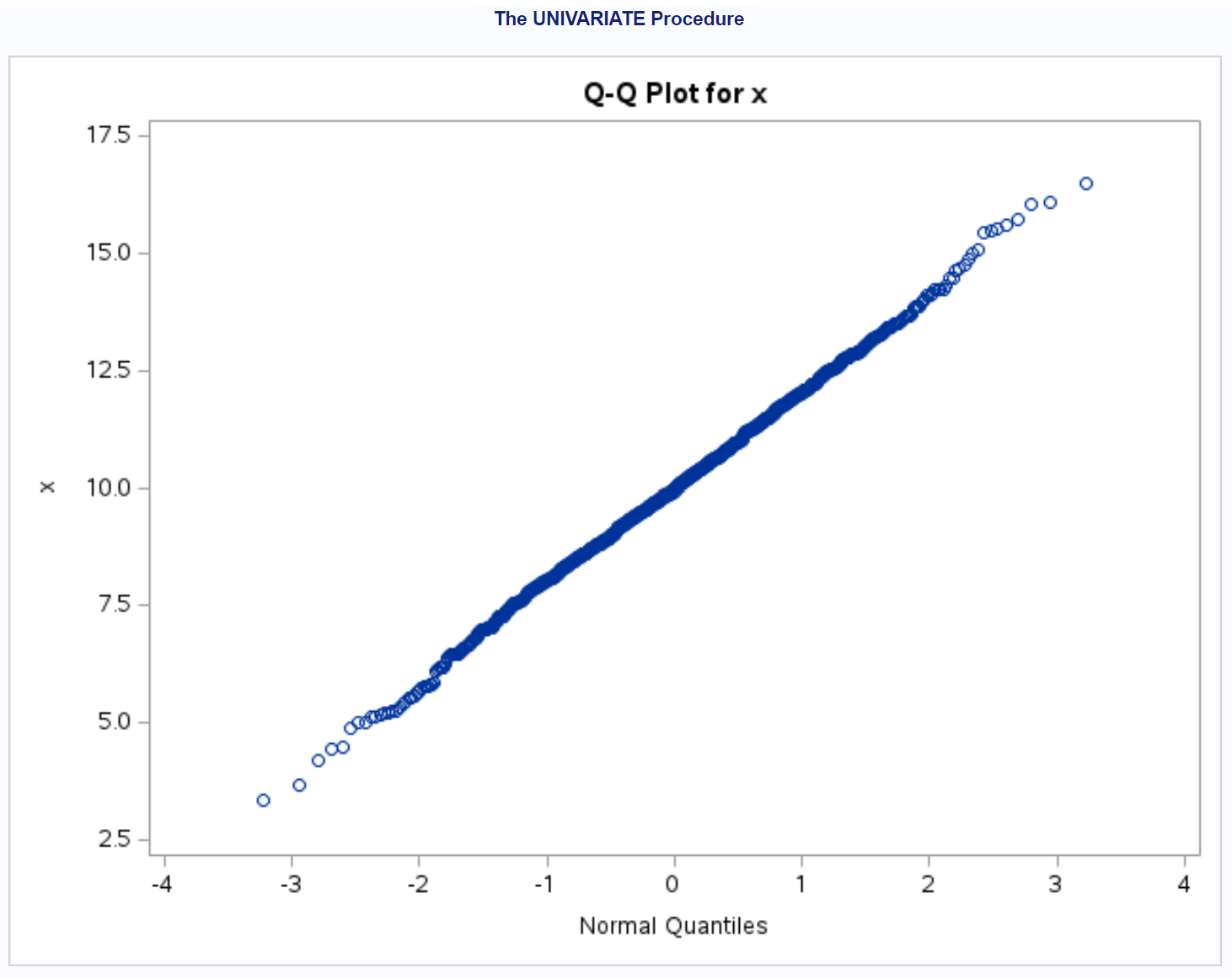
အမြီးတစ်ခုစီတစ်လျှောက်တွင် အနည်းငယ်သွေဖည်မှုအနည်းငယ်ရှိသော အမှတ်များသည် အများအားဖြင့် ဖြောင့်ထောင့်ဖြတ်မျဉ်းတစ်လျှောက်တွင် ရှိနေသည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။
ဤဂရပ်ကိုအခြေခံ၍ ဤဒေတာအတွဲကို ပုံမှန်ဖြန့်ဝေသည်ဟု ကျွန်ုပ်တို့လုံခြုံစွာယူဆနိုင်ပါသည်။
ဥပမာ 2- ပုံမှန်မဟုတ်သောဒေတာအတွက် QQ ကြံစည်မှု
ဖော်ပြပါကုဒ်သည် ထပ်ကိန်းခွဲဝေမှု တစ်ခုမှ ထုတ်ပေးသော စူးစမ်းလေ့လာမှု 1000 ပါရှိသော ဒေတာအတွဲအတွက် QQ ကွက်ကွက်ကို ဖန်တီးနည်းကို ပြသသည်-
/*generate 1000 values that follow an exponential distribution*/
data exp_data;
do i = 1 to 1000;
x = ranexp (1);
output ;
end ;
run ;
/*create some plot*/
proc univariate data =exp_data noprint ;
qqplot x;
run ;
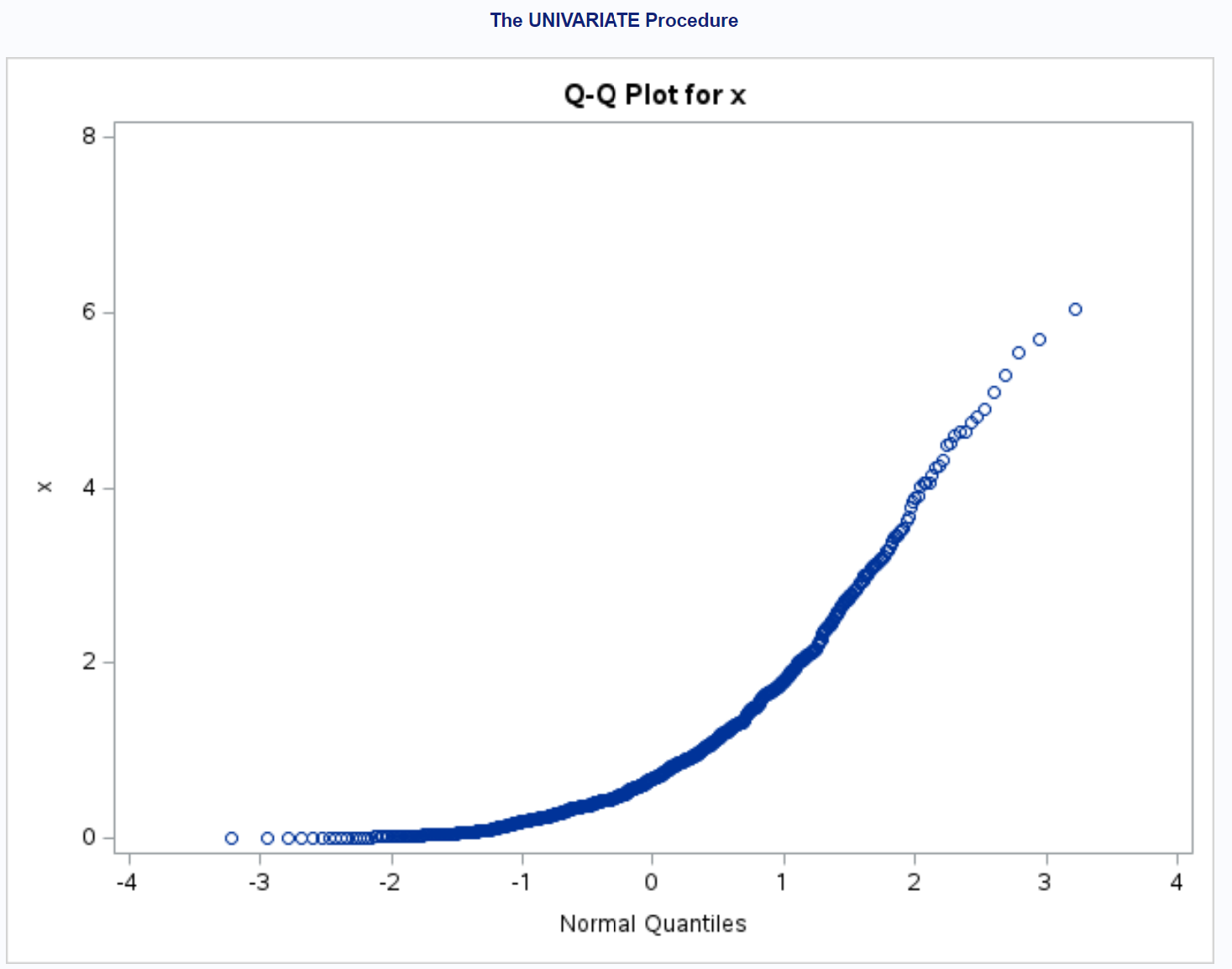
အမှတ်များသည် တည့်တည့် ထောင့်ဖြတ်မျဉ်းမှ သိသိသာသာ လွဲသွားသည်ကို ကျွန်ုပ်မြင်သည်။ ၎င်းသည် ဒေတာအတွဲအား ပုံမှန်ဖြန့်ဝေခြင်းမဟုတ်ကြောင်း ရှင်းရှင်းလင်းလင်းဖော်ပြသည်။
ဒေတာသည် ထပ်ကိန်းခွဲဝေမှုကို လိုက်နာသင့်သည်ဟု ကျွန်ုပ်တို့သတ်မှတ်ထားသောကြောင့် ၎င်းသည် အဓိပ္ပာယ်ရှိသင့်သည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် SAS တွင် အခြားဘုံအလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
SAS တွင်ပုံမှန်စစ်ဆေးမှုအတွက် Proc Univariate ကိုအသုံးပြုနည်း
SAS တွင် log transformation လုပ်နည်း
SAS တွင် outliers ကိုမည်သို့ခွဲခြားနိုင်မည်နည်း။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။