Python တွင် roc curve ဆွဲနည်း (အဆင့်ဆင့်)
Logistic regression သည် response variable binary ဖြစ်သောအခါ regression model တစ်ခုနှင့် ကိုက်ညီရန် ကျွန်ုပ်တို့အသုံးပြုသည့် ကိန်းဂဏန်းဆိုင်ရာ နည်းလမ်းတစ်ခုဖြစ်သည်။ ထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံသည် ဒေတာအစုံနှင့် မည်မျှကိုက်ညီကြောင်း အကဲဖြတ်ရန်၊ အောက်ပါ မက်ထရစ်နှစ်ခုကို ကြည့်နိုင်သည်-
- အာရုံခံစားနိုင်မှု- ရလဒ်အမှန်တကယ်အပြုသဘောဆောင်သောအခါတွင် လေ့လာမှုတစ်ခုအတွက် အပြုသဘောဆောင်သောရလဒ်ကို မော်ဒယ်က ခန့်မှန်းပေးသည့်ဖြစ်နိုင်ခြေ။ ၎င်းကို “စစ်မှန်သော အပြုသဘောနှုန်း” ဟုလည်း ခေါ်သည်။
- တိကျမှု- ရလဒ်အမှန်တကယ် အနုတ်လက္ခဏာဖြစ်သောအခါ စောင့်ကြည့်မှုတစ်ခုအတွက် အနုတ်ရလဒ်ကို မော်ဒယ်က ခန့်မှန်းသည့် ဖြစ်နိုင်ခြေ။ ၎င်းကို “စစ်မှန်သော အနုတ်လက္ခဏာနှုန်း” ဟုလည်း ခေါ်သည်။
ဤတိုင်းတာမှုနှစ်ခုကို မြင်ယောင်မြင်ယောင်ရန် နည်းလမ်းတစ်ခုမှာ “ လက်ခံသူလည်ပတ်မှုလက္ခဏာ” မျဉ်းကွေးကို ကိုယ်စားပြုသည့် ROC မျဉ်းကွေးကို ဖန်တီးရန်ဖြစ်သည်။ ၎င်းသည် ထောက်ပံ့ပို့ဆောင်မှု ဆုတ်ယုတ်မှုပုံစံ၏ အာရုံခံနိုင်စွမ်းနှင့် တိကျမှုကို ပြသသည့် ဂရပ်တစ်ခုဖြစ်သည်။
အောက်ဖော်ပြပါ အဆင့်ဆင့် ဥပမာသည် Python ရှိ ROC မျဉ်းကွေးတစ်ခုကို ဖန်တီးပြီး အဓိပ္ပာယ်ပြန်ဆိုနည်းကို ပြသထားသည်။
အဆင့် 1- လိုအပ်သော ပက်ကေ့ခ်ျများကို တင်သွင်းပါ။
ပထမဦးစွာ၊ Python တွင် ထောက်ပံ့ပို့ဆောင်ရေးဆုတ်ယုတ်မှုကို လုပ်ဆောင်ရန် လိုအပ်သော ပက်ကေ့ဂျ်များကို တင်သွင်းပါမည်။
import pandas as pd import numpy as np from sklearn. model_selection import train_test_split from sklearn. linear_model import LogisticRegression from sklearn import metrics import matplotlib. pyplot as plt
အဆင့် 2- ထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံကို အံကိုက်လုပ်ပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် ဒေတာအတွဲတစ်ခုကို တင်သွင်းပြီး ၎င်းနှင့် ထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံကို အံကိုက်လုပ်ပါမည်။
#import dataset from CSV file on Github
url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/default.csv"
data = pd. read_csv (url)
#define the predictor variables and the response variable
X = data[[' student ',' balance ',' income ']]
y = data[' default ']
#split the dataset into training (70%) and testing (30%) sets
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
#instantiate the model
log_regression = LogisticRegression()
#fit the model using the training data
log_regression. fit (X_train,y_train)
အဆင့် 3- ROC မျဉ်းကွေးကိုဆွဲပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် စစ်မှန်သော အပြုသဘောနှုန်းနှင့် မှားယွင်းသော အပြုသဘောနှုန်းကို တွက်ချက်ပြီး Matplotlib ဒေတာ ပုံဖော်ခြင်း ပက်ကေ့ဂျ်ကို အသုံးပြု၍ ROC မျဉ်းကွေးကို ဖန်တီးပါမည်-
#define metrics
y_pred_proba = log_regression. predict_proba (X_test)[::,1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred_proba)
#create ROC curve
plt. plot (fpr,tpr)
plt. ylabel (' True Positive Rate ')
plt. xlabel (' False Positive Rate ')
plt. show ()
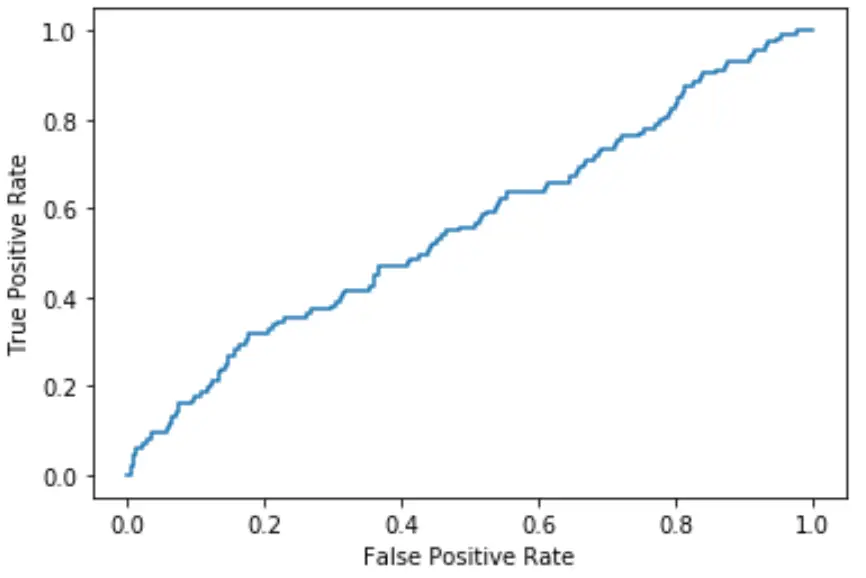
မျဉ်းကွေးသည် ကွက်ကွက်၏ဘယ်ဘက်အပေါ်ထောင့်နှင့် ပိုနီးကပ်လေလေ၊ မော်ဒယ်သည် အချက်အလက်များကို အမျိုးအစားများခွဲခြားနိုင်လေလေဖြစ်သည်။
အထက်ဖော်ပြပါ ဂရပ်မှ ကျွန်ုပ်တို့မြင်နိုင်သည်အတိုင်း၊ ဤထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံသည် ဒေတာများကို အမျိုးအစားများခွဲရန် အလွန်ညံ့ဖျင်းသောအလုပ်ဖြစ်သည်။
၎င်းကို တွက်ချက်ရန်အတွက်၊ မျဉ်းကွေးအောက်ရှိ AUC – ဧရိယာ – ကွက်ကွက်၏ မျဉ်းကွေးအောက်တွင် ကျွန်ုပ်တို့ကို ပြောပြနိုင်သည်။
AUC က 1 နဲ့ ပိုနီးစပ်လေ၊ model က ပိုကောင်းပါတယ်။ 0.5 နှင့် ညီမျှသော AUC ရှိသော မော်ဒယ်သည် ကျပန်း အမျိုးအစားများကို လုပ်ဆောင်သည့် မော်ဒယ်ထက် ပိုကောင်းမည်မဟုတ်ပါ။
အဆင့် 4- AUC ကို တွက်ချက်ပါ။
မော်ဒယ်၏ AUC ကို တွက်ချက်ရန်နှင့် ROC ကွက်ကွက်၏ ညာဘက်အောက်ထောင့်တွင် ပြသရန် အောက်ပါကုဒ်ကို ကျွန်ုပ်တို့ အသုံးပြုနိုင်သည်။
#define metrics
y_pred_proba = log_regression. predict_proba (X_test)[::,1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred_proba)
auc = metrics. roc_auc_score (y_test, y_pred_proba)
#create ROC curve
plt. plot (fpr,tpr,label=" AUC= "+str(auc))
plt. ylabel (' True Positive Rate ')
plt. xlabel (' False Positive Rate ')
plt. legend (loc=4)
plt. show ()
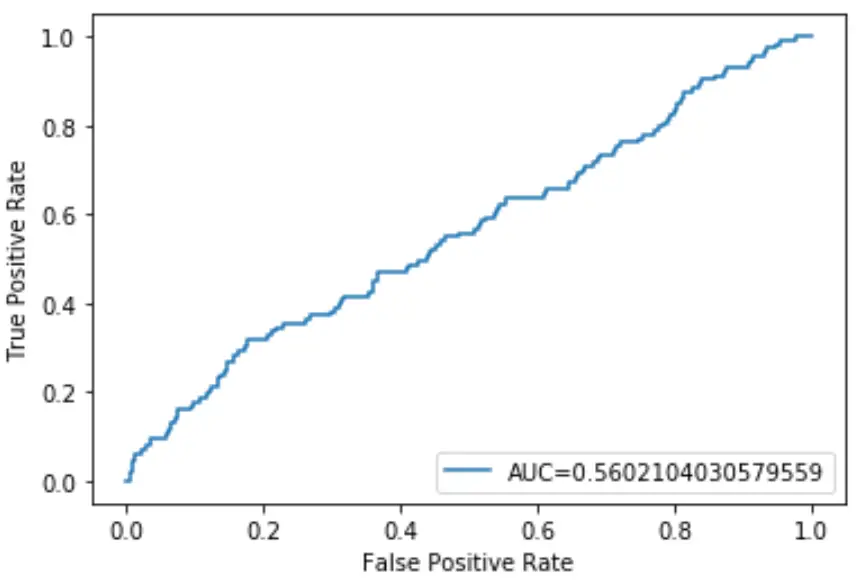
ဤ logistic regression model ၏ AUC သည် 0.5602 ဖြစ်သည် ။ ဤကိန်းဂဏန်းကို 0.5 ဖြင့် ပိတ်ထားသောကြောင့်၊ မော်ဒယ်သည် ဒေတာကို အမျိုးအစားခွဲရာတွင် ညံ့ဖျင်းသောအလုပ်ဖြစ်ကြောင်း အတည်ပြုသည်။
ဆက်စပ်- Python တွင် ROC မျဉ်းကြောင်းများစွာကို ဘယ်လိုဆွဲမလဲ။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။