ဆုတ်ယုတ်ခြင်း သို့မဟုတ် အမျိုးအစားခွဲခြားခြင်း- ကွာခြားချက်ကား အဘယ်နည်း။
စက်သင်ယူခြင်းဆိုင်ရာ အယ်လဂိုရီသမ်များကို သီးခြားအမျိုးအစား နှစ်မျိုးခွဲနိုင်သည်- ကြီးကြပ်ပြီး နှင့် ကြီးကြပ်မထားသော သင်ယူမှု အယ်လဂိုရီသမ်များ ။

ကြီးကြပ်သင်ကြားမှုဆိုင်ရာ အယ်လဂိုရီသမ်များကို အမျိုးအစားနှစ်မျိုး ခွဲခြားနိုင်သည်-
1. Regression- တုံ့ပြန်မှုကိန်းရှင်သည် စဉ်ဆက်မပြတ်ဖြစ်သည်။
ဥပမာအားဖြင့်၊ တုံ့ပြန်မှုကိန်း ရှင်သည်-
- အလေးချိန်
- အရပ်အမြင့်
- စျေးနှုန်း
- အချိန်
- စုစုပေါင်းယူနစ်
အခြေအနေတိုင်းတွင်၊ ဆုတ်ယုတ်မှုပုံစံတစ်ခုသည် စဉ်ဆက်မပြတ်ပမာဏကို ခန့်မှန်းရန်ရှာသည်။
ဆုတ်ယုတ်မှု ဥပမာ-
ကျွန်ုပ်တို့တွင် မတူညီသောအိမ် 100 အတွက် ကွဲလွဲချက်သုံးမျိုးပါရှိသော ဒေတာအစုံရှိသည်- စတုရန်းပေ၊ ရေချိုးခန်းအရေအတွက်နှင့် အရောင်းစျေးနှုန်း။
တုံ့ပြန်မှုကိန်းရှင်အဖြစ် ရှင်းလင်းချက်ပြောင်းနိုင်သောကိန်းရှင်များနှင့် အရောင်းစျေးနှုန်းများအဖြစ် စတုရန်းပုံနှင့် ရေချိုးခန်းအရေအတွက်တို့ကို အသုံးပြုသည့် ဆုတ်ယုတ်မှုပုံစံကို ကျွန်ုပ်တို့ အံဝင်ခွင်ကျဖြစ်စေနိုင်သည်။
ထို့နောက် ၎င်း၏စတုရန်းပုံနှင့် ရေချိုးခန်းအရေအတွက်ပေါ်မူတည်၍ အိမ်တစ်အိမ်၏ရောင်းစျေးကို ခန့်မှန်းရန် ဤပုံစံကို အသုံးပြုနိုင်သည်။
တုံ့ပြန်မှုမပြောင်းလဲနိုင်သော (အရောင်းစျေးနှုန်း) သည် အဆက်မပြတ်ဖြစ်နေသောကြောင့် ဆုတ်ယုတ်မှုပုံစံ၏ ဥပမာတစ်ခုဖြစ်သည်။
ဆုတ်ယုတ်မှုပုံစံတစ်ခု၏ တိကျမှုကို တိုင်းတာရန် အသုံးအများဆုံးနည်းလမ်းမှာ ပျမ်းမျှအားဖြင့် ကျွန်ုပ်တို့၏ခန့်မှန်းထားသောတန်ဖိုးများသည် မော်ဒယ်တစ်ခုရှိ ကျွန်ုပ်တို့၏လေ့လာတွေ့ရှိထားသည့်တန်ဖိုးများနှင့် မည်မျှကွာဝေးသည်ကို ပြောပြသည့် root mean square error (RMSE) ကို တွက်ချက်ရန်ဖြစ်သည်။ အောက်ပါအတိုင်း တွက်ချက်သည်။
RMSE = √ Σ(P i – O i ) 2 / n
ရွှေ-
- ∑ သည် “ပေါင်း” ဟု အဓိပ္ပါယ်ရသော ဖန်စီသင်္ကေတတစ်ခုဖြစ်သည်။
- P i သည် IT Observation အတွက် ခန့်မှန်းတန်ဖိုးဖြစ်သည်။
- O i သည် ith observation အတွက် မှတ်သားထားသော တန်ဖိုးဖြစ်သည်။
- n သည် နမူနာအရွယ်အစားဖြစ်သည်။
RMSE သေးငယ်လေ၊ ဆုတ်ယုတ်မှုပုံစံသည် ဒေတာကို အံဝင်ခွင်ကျဖြစ်စေနိုင်လေဖြစ်သည်။
2. အမျိုးအစားခွဲခြားခြင်း- တုံ့ပြန်မှုကိန်းရှင်သည် အမျိုးအစားခွဲခြားသည်။
ဥပမာအားဖြင့်၊ တုံ့ပြန်မှုကိန်းရှင်သည် အောက်ပါတန်ဖိုးများကို ယူနိုင်သည်။
- ကျားသို့မဟုတ်မ
- အောင်မြင်သည်ဖြစ်စေ ကျရှုံးသည်
- အနိမ့်၊ အလတ် သို့မဟုတ် အမြင့်
ကိစ္စတစ်ခုစီတွင်၊ အမျိုးအစားခွဲခြားမှုပုံစံတစ်ခုသည် အတန်းတံဆိပ်တစ်ခုကို ခန့်မှန်းရန်ရှာသည်။
အမျိုးအစားခွဲခြားခြင်း၏ဥပမာ
ကျွန်ုပ်တို့တွင် မတူညီသောကောလိပ်ဘတ်စကက်ဘောကစားသမား 100 အတွက် variable သုံးခုပါရှိသော ဒေတာအစုံရှိသည်- ဂိမ်းပျမ်းမျှနှုန်း၊ ပိုင်းခြားမှုအဆင့်နှင့် ၎င်းတို့ကို NBA သို့ ရေးဆွဲသည်ဖြစ်စေ မရေးဆွဲသည်ဖြစ်စေ။
ကျွန်ုပ်တို့သည် ဂိမ်းတစ်ခုလျှင် ပျမ်းမျှရမှတ်များနှင့် ပိုင်းခြားမှုအဆင့်အလိုက် အမျိုးအစားခွဲခြားမှုပုံစံကို ရှင်းလင်းချက်ပြောင်းနိုင်သောကိန်းရှင်များအဖြစ် ပြောင်းလဲကာ တုံ့ပြန်မှုကိန်းရှင်အဖြစ် “ ရေးဆွဲထားသည်” ကို ပြုပြင်ပြောင်းလဲနိုင်ပါသည်။
ထို့နောက် ပေးထားသောကစားသမားသည် ဂိမ်းပျမ်းမျှနှင့် ပိုင်းခြားမှုအဆင့်အလိုက် အမှတ်အလိုက် NBA သို့ ရေးဆွဲမည်လား မခန့်မှန်းရန် ဤပုံစံကို ကျွန်ုပ်တို့အသုံးပြုနိုင်ပါသည်။
တုံ့ပြန်မှုမပြောင်းလဲနိုင်သော (“ရေးထားသည်”) သည် အမျိုးအစားခွဲခြားထားသောကြောင့် အမျိုးအစားခွဲခြားမှုပုံစံ၏ ဥပမာတစ်ခုဖြစ်သည်။ တစ်နည်းဆိုရသော်၊ ၎င်းသည် မတူညီသော အမျိုးအစားနှစ်ခုတွင် တန်ဖိုးများကိုသာ ယူနိုင်သည်- “ ရေးသားထားသည်” သို့မဟုတ် “ မရေးဆွဲရသေးသော” ။
အမျိုးအစားခွဲခြားမှုပုံစံတစ်ခု၏ တိကျမှုကို တိုင်းတာရန် အသုံးအများဆုံးနည်းလမ်းမှာ မော်ဒယ်မှပြုလုပ်သော မှန်ကန်သောအမျိုးအစားခွဲခြားမှုရာခိုင်နှုန်းကို တွက်ချက်ရန်ဖြစ်သည်။
တိကျမှု = အမှားပြင်ဆင်ခြင်း အမျိုးအစားခွဲခြင်း/ အမျိုးအစားခွဲခြင်း ကြိုးစားမှု စုစုပေါင်းအရေအတွက် * 100%
ဥပမာအားဖြင့်၊ ကစားသမားတစ်ဦးသည် ဖြစ်နိုင်ချေ အကြိမ် 100 အနက် NBA 88 တွင် အကြိမ် 88 ကြိမ်ရေးဆွဲမည်၊ မဟုတ်သည်ကို မော်ဒယ်တစ်ခု မှန်ကန်စွာ ခွဲခြားသတ်မှတ်ပါက၊ မော်ဒယ်၏ တိကျမှုသည်-
တိကျမှု = (88/100) * 100% = 88%
တိကျမှုမြင့်မားလေ၊ အမျိုးအစားခွဲခြားမှုပုံစံတစ်ခုသည် ရလဒ်များကို ကြိုတင်ခန့်မှန်းနိုင်လေဖြစ်သည်။
Regression နှင့် Classification အကြား တူညီမှုများ
Regression နှင့် classification algorithms များသည် အောက်ပါနည်းလမ်းများဖြင့် ဆင်တူပါသည်။
- နှစ်ခုစလုံးသည် ကြီးကြပ်သင်ကြားမှု အယ်လဂိုရီသမ်များဖြစ်သည်၊ ဆိုလိုသည်မှာ ၎င်းတို့နှစ်ဦးစလုံးသည် တုံ့ပြန်မှုပြောင်းလဲနိုင်သော ကိန်းရှင်တစ်ခုပါရှိသည်။
- နှစ်ခုလုံးသည် တုံ့ပြန်မှုကို ခန့်မှန်းရန် မော်ဒယ်များ ဖန်တီးရန် တစ်ခု သို့မဟုတ် တစ်ခုထက်ပို သော ရှင်းပြချက်တစ်ခုကို အသုံးပြုသည်။
- နှစ်ခုလုံးသည် တုံ့ပြန်မှုကိန်းရှင်၏ တန်ဖိုးများကို မည်ကဲ့သို့ ပြောင်းလဲစေသည်ကို နားလည်ရန် အသုံးပြုနိုင်သည်။
ဆုတ်ယုတ်ခြင်းနှင့် အမျိုးအစားခွဲခြားခြင်းကြား ကွာခြားချက်များ
ဆုတ်ယုတ်ခြင်းနှင့် အမျိုးအစားခွဲခြင်းဆိုင်ရာ အယ်လဂိုရီသမ်များသည် အောက်ပါနည်းလမ်းများဖြင့် ကွဲပြားသည်-
- Regression algorithms များသည် စဉ်ဆက်မပြတ် အရေအတွက်နှင့် အမျိုးအစားခွဲခြင်းဆိုင်ရာ အယ်လဂိုရီသမ်များကို ခန့်မှန်းရန် ကြိုးပမ်းပြီး အတန်းတံဆိပ်တစ်ခုကို ခန့်မှန်းရန် ရှာဖွေသည်။
- ဆုတ်ယုတ်မှု၏ တိကျမှုနှင့် အမျိုးအစားခွဲခြားမှုပုံစံများကို ကျွန်ုပ်တို့တိုင်းတာပုံ ကွဲပြားသည်။
ဆုတ်ယုတ်မှုကို အမျိုးအစားခွဲခြားခြင်းသို့ ပြောင်းလဲခြင်း။
တုံ့ပြန်မှုကိန်းရှင်ကို အပိုင်းများအဖြစ် ပိုင်းခြားသတ်မှတ်ခြင်း ဖြင့် ဆုတ်ယုတ်မှုပြဿနာကို အမျိုးအစားခွဲခြားခြင်းပြဿနာအဖြစ်သို့ ပြောင်းလဲနိုင်သည်ကို သတိပြုသင့်သည်။
ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့တွင် စတုရန်းပုံ၊ ရေချိုးခန်းအရေအတွက်နှင့် အရောင်းစျေးနှုန်းဟူ၍ ကွဲလွဲချက် သုံးခုပါဝင်သည့် ဒေတာအစုံရှိသည် ဆိုကြပါစို့။
အရောင်းစျေးနှုန်းများကို ခန့်မှန်းရန် စတုရန်းပုံနှင့် ရေချိုးခန်းအရေအတွက်တို့ကို အသုံးပြု၍ ဆုတ်ယုတ်မှုပုံစံကို တည်ဆောက်နိုင်သည်။
သို့သော်၊ ကျွန်ုပ်တို့သည် အရောင်းစျေးနှုန်းကို အမျိုးအစားသုံးမျိုးဖြင့် ခွဲခြားနိုင်သည်-
- $80,000 မှ $160,000 – “ရောင်းစျေးလျော့”
- $161,000 – $240,000: “ပျမ်းမျှရောင်းဈေး”
- $241,000 – $320,000: “ရောင်းဈေးမြင့်”
ထို့နောက် ပေးထားသောအိမ်၏ရောင်းစျေးသည် မည်သည့်အတန်း (အနိမ့်၊ အလတ်၊ သို့မဟုတ် အမြင့်) သို့ ကျမည်ကို ခန့်မှန်းရန် လေးထောင့်ပုံနှင့် ရေချိုးခန်း အရေအတွက်ကို ရှင်းလင်းချက်ပြောင်းနိုင်သော ကိန်းရှင်များအဖြစ် အသုံးပြုနိုင်သည်။
အိမ်တစ်အိမ်စီကို အတန်းတစ်ခုအဖြစ် သတ်မှတ်ရန် ကြိုးစားနေသောကြောင့် အမျိုးအစားခွဲခြားမှုပုံစံ၏ ဥပမာတစ်ခုဖြစ်သည်။
အကျဉ်းချုပ်
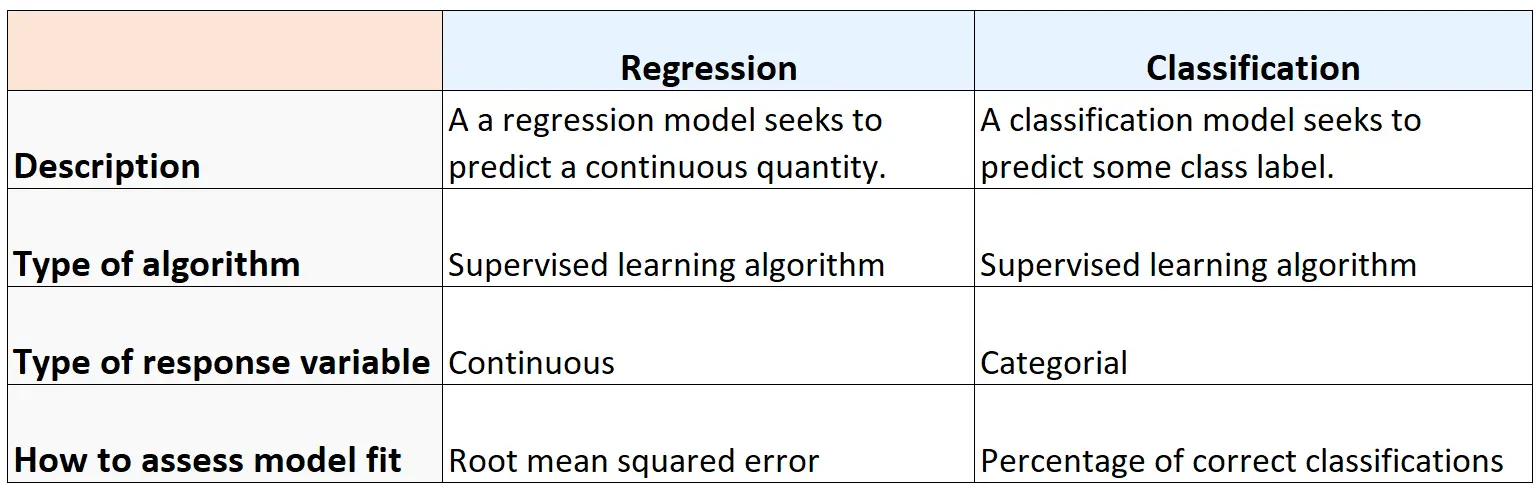
အောက်ဖော်ပြပါဇယားသည် ဆုတ်ယုတ်ခြင်းနှင့် အမျိုးအစားခွဲခြင်းဆိုင်ရာ အယ်လဂိုရီသမ်များကြားရှိ ဆင်တူမှုများနှင့် ကွာခြားချက်များကို အကျဉ်းချုပ်ဖော်ပြသည်-
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။