Logistic regression နိဒါန်း
တစ်ခု သို့မဟုတ် တစ်ခုထက်ပိုသော ကြိုတင်ခန့်မှန်းကိန်းရှင်များနှင့် စဉ်ဆက်မပြတ်တုံ့ပြန်မှုကိန်းရှင်ကြား ဆက်နွယ်မှုကို ကျွန်ုပ်တို့နားလည်လိုသောအခါ၊ ကျွန်ုပ်တို့သည် linear regression ကို မကြာခဏအသုံးပြုသည်။
သို့ရာတွင်၊ တုံ့ပြန်မှုကိန်းရှင်သည် အမျိုးအစားခွဲခြားသောအခါ၊ ကျွန်ုပ်တို့သည် ထောက်လှမ်းဆုတ်ယုတ်မှုကို အသုံးပြုနိုင်သည်။
Logistic regression သည် အမျိုးအစားခွဲခြင်းဆိုင်ရာ အယ်လဂိုရီသမ် အမျိုးအစားတစ်ခုဖြစ်ပြီး ၎င်းသည် ဒေတာအတွဲတစ်ခုတွင် စောင့်ကြည့်မှုများကို “ အမျိုးအစားခွဲရန်” ကြိုးပမ်းသောကြောင့် ဖြစ်သည်။
ဤသည်မှာ logistic regression ကိုအသုံးပြုခြင်း၏ဥပမာအချို့ဖြစ်သည်။
- ပေးထားသောဖောက်သည်သည် ချေးငွေတွင် ပုံသေဖြစ်မဖြစ်ကို ခန့်မှန်းရန် ခရက်ဒစ်ရမှတ် နှင့် ဘဏ်လက်ကျန်ကို အသုံးပြုလိုပါသည်။ (တုံ့ပြန်မှု variable = “ မူလ” သို့မဟုတ် “ ပုံသေမရှိ” )
- ပေးထားသော ဘတ်စကတ်ဘောကစားသမားတစ်ဦးအား NBA တွင် ရေးဆွဲမည်လား မခန့်မှန်းရန် ဂိမ်း တစ်ခုလျှင် ပျမ်းမျှ ပြန်ခုန်နှုန်းများနှင့် ဂိမ်းတစ်ခု လျှင် ပျမ်းမျှအမှတ်များကို အသုံးပြုလိုပါသည်။
- အချို့သောမြို့များတွင် အိမ်တစ်လုံးရောင်းဈေး $200,000 သို့မဟုတ် ထို့ထက်ပို၍ စာရင်းသွင်းခံရခြင်းရှိမရှိ ခန့်မှန်းရန် စတုရန်းပုံ နှင့် ရေချိုးခန်းများကို အသုံးပြုလိုပါသည်။ (တုံ့ပြန်မှုပြောင်းလဲမှု = “ Yes” သို့မဟုတ် “ No” )
ဤနမူနာတစ်ခုစီရှိ တုံ့ပြန်မှုကိန်းရှင်သည် တန်ဖိုးနှစ်ခုထဲမှ တစ်ခုကိုသာ ယူနိုင်သည်ကို သတိပြုပါ။ တုံ့ပြန်မှုကိန်းရှင်သည် စဉ်ဆက်မပြတ်တန်ဖိုးယူသည့် မျဉ်းနားဆုတ်ယုတ်မှုနှင့် နှိုင်းယှဉ်ပါ။
logistic regression ညီမျှခြင်း
Logistic regression သည် အောက်ပါပုံစံ၏ ညီမျှခြင်းတစ်ခုကို ရှာဖွေရန် အမြင့်ဆုံးဖြစ်နိုင်ခြေ ခန့်မှန်းချက် (အသေးစိတ်အချက်အလက်များကို ဤနေရာတွင် ဆွေးနွေးမည်မဟုတ်ပါ) ဟုခေါ်သော နည်းလမ်းကို အသုံးပြုသည်-
log[p(X) / ( 1 -p(X))] = β 0 + β 1 X 1 + β 2 X 2 + … + β p
ရွှေ-
- X j : j th ကြိုတင်ခန့်မှန်းနိုင်သောကိန်းရှင်
- β j : j th ကြိုတင်ခန့်မှန်းကိန်းရှင်အတွက် ကိန်းကိန်းကို ခန့်မှန်းခြင်း။
ညီမျှခြင်း၏ ညာဘက်ရှိ ဖော်မြူလာသည် တုံ့ပြန်မှုကိန်းရှင်သည် တန်ဖိုး 1 ကို ယူသည့် မှတ်တမ်းအပေါက်များကို ခန့်မှန်းပေးသည်။
ထို့ကြောင့်၊ ကျွန်ုပ်တို့သည် logistic regression model ကို အံဝင်ခွင်ကျသောအခါ၊ ပေးထားသော observation သည် value 1 ကိုယူမည့်ဖြစ်နိုင်ခြေကို တွက်ချက်ရန် အောက်ပါညီမျှခြင်းကို အသုံးပြုနိုင်သည်။
p(X) = e β 0 + β 1 X 1 + β 2 X 2 + … + β p
ထို့နောက် ရှုမြင်ချက်ကို 1 သို့မဟုတ် 0 အဖြစ် အမျိုးအစားခွဲခြားရန် အချို့သောဖြစ်နိုင်ခြေအဆင့်သတ်မှတ်ချက်ကို အသုံးပြုသည်။
ဥပမာအားဖြင့်၊ 0.5 ထက်ကြီးသော ဖြစ်နိုင်ခြေရှိသော လေ့လာတွေ့ရှိချက်များကို “ 1” အဖြစ် ခွဲခြားပြီး အခြားလေ့လာတွေ့ရှိချက်အားလုံးကို “ 0” အဖြစ် ခွဲခြားသတ်မှတ်မည်ဟု ကျွန်ုပ်တို့ပြောနိုင်သည်။
Logistic regression ၏ရလဒ်ကို မည်သို့အဓိပ္ပာယ်ဖွင့်ဆိုမည်နည်း။
ပေးထားသော ဘတ်စကက်ဘောကစားသမားတစ်ဦးသည် ဂိမ်းတစ်ခုလျှင် ပျမ်းမျှပြန်ခုန်နှုန်းနှင့် ၎င်း၏ပျမ်းမျှရမှတ်များပေါ်မူတည်၍ NBA တွင် ပေးထားသော ဘတ်စကက်ဘောကစားသမားကို ရေးဆွဲမည်လား မခန့်မှန်းရန် ထောက်ပံ့ပို့ဆောင်ရေးဆိုင်ရာ ဆုတ်ယုတ်မှုပုံစံကို အသုံးပြုသည်ဆိုပါစို့။
ဤသည်မှာ logistic regression model ၏ရလဒ်ဖြစ်သည် ။
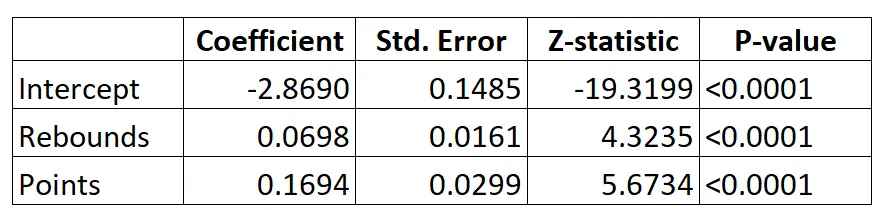
ဖော်မြူလာများကို အသုံးပြု၍ အောက်ပါဖော်မြူလာကို အသုံးပြု၍ ၎င်းတို့၏ ပျမ်းမျှပြန်ခုန်နှုန်းများနှင့် ဂိမ်းတစ်ခုလျှင် အမှတ်များပေါ်မူတည်၍ ပေးထားသော ကစားသမားတစ်ဦး၏ ဖြစ်နိုင်ခြေကို တွက်ချက်နိုင်သည်-
P(Drafted) = e -2.8690 + 0.0698*(rebs) + 0.1694*(မှတ်) / (1+e -2.8690 + 0.0698*(rebs) + 0.1694*(မှတ်) )
ဥပမာအားဖြင့်၊ ပေးထားသောကစားသမားသည် ဂိမ်းတစ်ခုလျှင် ပျမ်းမျှ 8 rebounds နှင့် တစ်ပွဲလျှင် 15 မှတ်ရသည်ဆိုပါစို့။ မော်ဒယ်အရ၊ ဤကစားသမားကို NBA သို့ ရေးဆွဲခြင်းဖြစ်နိုင်ခြေမှာ 0.557 ဖြစ်သည်။
P(Written) = e -2.8690 + 0.0698*(8) + 0.1694*(15) / (1+e -2.8690 + 0.0698*(8) + 0.1694*(15) ) = 0.557
ဤဖြစ်နိုင်ခြေသည် 0.5 ထက်များသောကြောင့်၊ ဤကစားသမားကို ရေးဆွဲမည်ဟု ကျွန်ုပ်တို့ ခန့်မှန်းပါသည်။
၎င်းကို ပျမ်းမျှ 3 ကြိမ်နှုန်းနှင့် တစ်ပွဲလျှင် 7 မှတ်သာရှိသော ကစားသမားနှင့် နှိုင်းယှဉ်ပါ။ ဤကစားသမားကို NBA သို့ ရေးဆွဲခြင်းဖြစ်နိုင်ခြေမှာ 0.186 ဖြစ်သည်။
P(Written) = e -2.8690 + 0.0698*(3) + 0.1694*(7) / (1+e -2.8690 + 0.0698*(3) + 0.1694*(7) ) = 0.186
ဤဖြစ်နိုင်ခြေသည် 0.5 ထက်နည်းသောကြောင့်၊ ဤကစားသမားကို ရေးဆွဲမည်မဟုတ်ကြောင်း ကျွန်ုပ်တို့ ခန့်မှန်းပါသည်။
Logistic Regression ယူဆချက်
Logistic regression သည် အောက်ပါ ယူဆချက်ကို အသုံးပြုသည် ။
1. တုံ့ပြန်မှု variable သည် binary ဖြစ်သည်။ တုံ့ပြန်မှုကိန်းရှင်သည် ဖြစ်နိုင်ချေရလဒ်နှစ်ခုသာ ယူနိုင်သည်ဟု ယူဆပါသည်။
2. လေ့လာတွေ့ရှိချက်များသည် သီးခြားဖြစ်သည်။ ဒေတာအတွဲရှိ လေ့လာတွေ့ရှိချက်များသည် တစ်ခုနှင့်တစ်ခု အမှီအခိုကင်းသည်ဟု ယူဆပါသည်။ ဆိုလိုသည်မှာ၊ လေ့လာတွေ့ရှိချက်များသည် တူညီသောလူတစ်ဦးချင်းစီ၏ ထပ်ခါတလဲလဲ တိုင်းတာခြင်းမှ ဆင်းသက်လာခြင်း သို့မဟုတ် တစ်ခုနှင့်တစ်ခု မည်သို့မျှ ဆက်စပ်မှုမရှိသင့်ပါ။
3. ကြိုတင်ခန့်မှန်းကိန်းရှင်များကြားတွင် ကြီးကြီးမားမား ပေါင်းစပ်ဖွဲ့စည်းမှုမျိုး မရှိပါ ။ ကြိုတင်ခန့်မှန်းကိန်းရှင်များသည် တစ်ခုနှင့်တစ်ခု အလွန်ဆက်စပ်မှု မရှိဟု ယူဆပါသည်။
4. လွန်ကဲလွန်ကဲမှု မရှိပါ။ ဒေတာအတွဲတွင် လွန်ကဲသော အစွန်းအထင်း သို့မဟုတ် သြဇာညောင်းသော အကဲခတ်မှုများ မရှိဟု ယူဆပါသည်။
5. ကြိုတင်ခန့်မှန်းကိန်းရှင်များနှင့် တုံ့ပြန်မှုကိန်းရှင်၏ လော့ဂ်စ်တို့အကြား မျဉ်းသားသော ဆက်ဆံရေးရှိသည် ။ ဤယူဆချက်ကို Box-Tidwell စမ်းသပ်မှုဖြင့် စမ်းသပ်နိုင်သည်။
6. နမူနာအရွယ်အစားသည်လုံလောက်သောကြီးမားသည်။ ပုံမှန်အားဖြင့်၊ သင့်တွင် ရှင်းပြချက်တစ်ခုစီအတွက် မကြာခဏ ရလဒ်အနည်းဆုံး 10 အမှုတစ်ခုရှိသင့်သည်။ ဥပမာအားဖြင့်၊ သင့်တွင် ရှင်းပြနိုင်သော ကိန်းရှင် 3 ခုရှိပြီး မကြာခဏ အနည်းဆုံးရလဒ်၏ ဖြစ်နိုင်ခြေမှာ 0.20 ဖြစ်ပါက သင့်တွင် အနည်းဆုံး နမူနာအရွယ်အစား (10*3) / 0.20 = 150 ရှိသင့်သည်။
ဤယူဆချက်များကို အတည်ပြုနည်းကို အသေးစိတ်ရှင်းလင်းချက်အတွက် ဤဆောင်းပါးကို ကြည့်ပါ။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။