Leave-one-out cross-validation (loocv) အမြန်နိဒါန်း
ဒေတာအတွဲတစ်ခုပေါ်ရှိ မော်ဒယ်တစ်ခု၏စွမ်းဆောင်ရည်ကို အကဲဖြတ်ရန်၊ ကျွန်ုပ်တို့သည် မော်ဒယ်မှပြုလုပ်သော ခန့်မှန်းချက်များသည် စောင့်ကြည့်လေ့လာထားသောဒေတာနှင့် မည်မျှကိုက်ညီကြောင်း တိုင်းတာရန် လိုအပ်ပါသည်။
၎င်းကိုတိုင်းတာရန်အသုံးအများဆုံးနည်းလမ်းမှာ အောက်ပါအတိုင်းတွက်ချက်ထားသည့် mean square error (MSE) ကိုအသုံးပြုခြင်းဖြစ်သည်။
MSE = (1/n)*Σ(y i – f(x i )) ၂
ရွှေ-
- n- လေ့လာတွေ့ရှိချက်စုစုပေါင်း
- y i : IT Observation ၏ တုံ့ပြန်မှုတန်ဖိုး
- f(x i ): i th observation ၏ ခန့်မှန်းထားသော တုံ့ပြန်မှုတန်ဖိုး
မော်ဒယ်ခန့်မှန်းချက်များသည် စောင့်ကြည့်မှုများနှင့် နီးကပ်လေ၊ MSE သည် နိမ့်လေဖြစ်သည်။
လက်တွေ့တွင်၊ ကျွန်ုပ်တို့သည် သတ်မှတ်ပုံစံတစ်ခု၏ MSE ကို တွက်ချက်ရန် အောက်ပါလုပ်ငန်းစဉ်ကို အသုံးပြုသည်-
1. ဒေတာအစုံကို လေ့ကျင့်ရေးအစုံနှင့် စမ်းသပ်မှုအစုံသို့ ခွဲပါ။
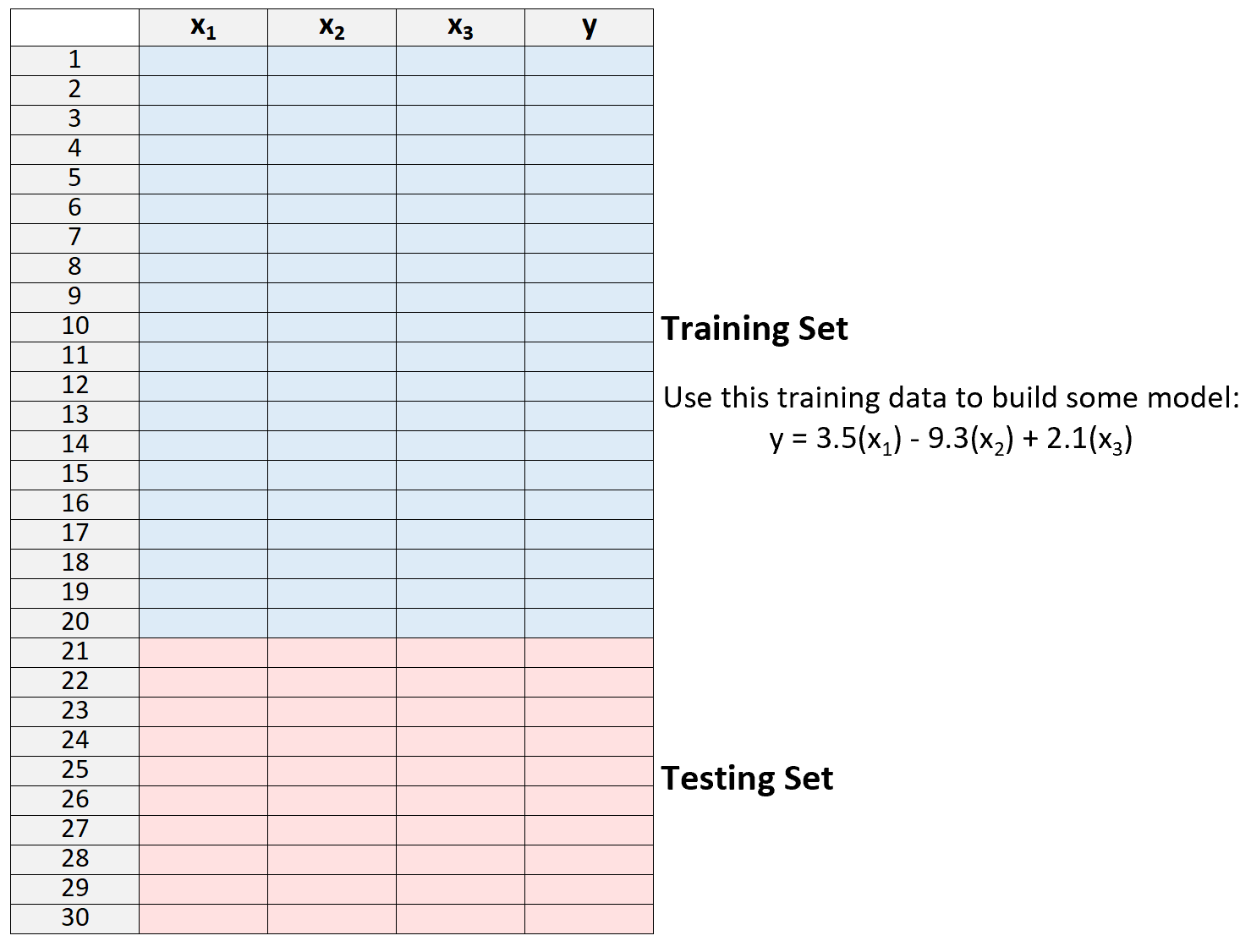
2. လေ့ကျင့်မှုအစုံမှ အချက်အလက်များကိုသာ အသုံးပြု၍ မော်ဒယ်ကို ဖန်တီးပါ။
3. စမ်းသပ်မှုအစုံနှင့် MSE တိုင်းတာမှုနှင့်ပတ်သက်၍ ခန့်မှန်းမှုများပြုလုပ်ရန် မော်ဒယ်ကိုအသုံးပြုပါ – ၎င်းကို စမ်းသပ်မှု MSE ဟုခေါ်သည်။ 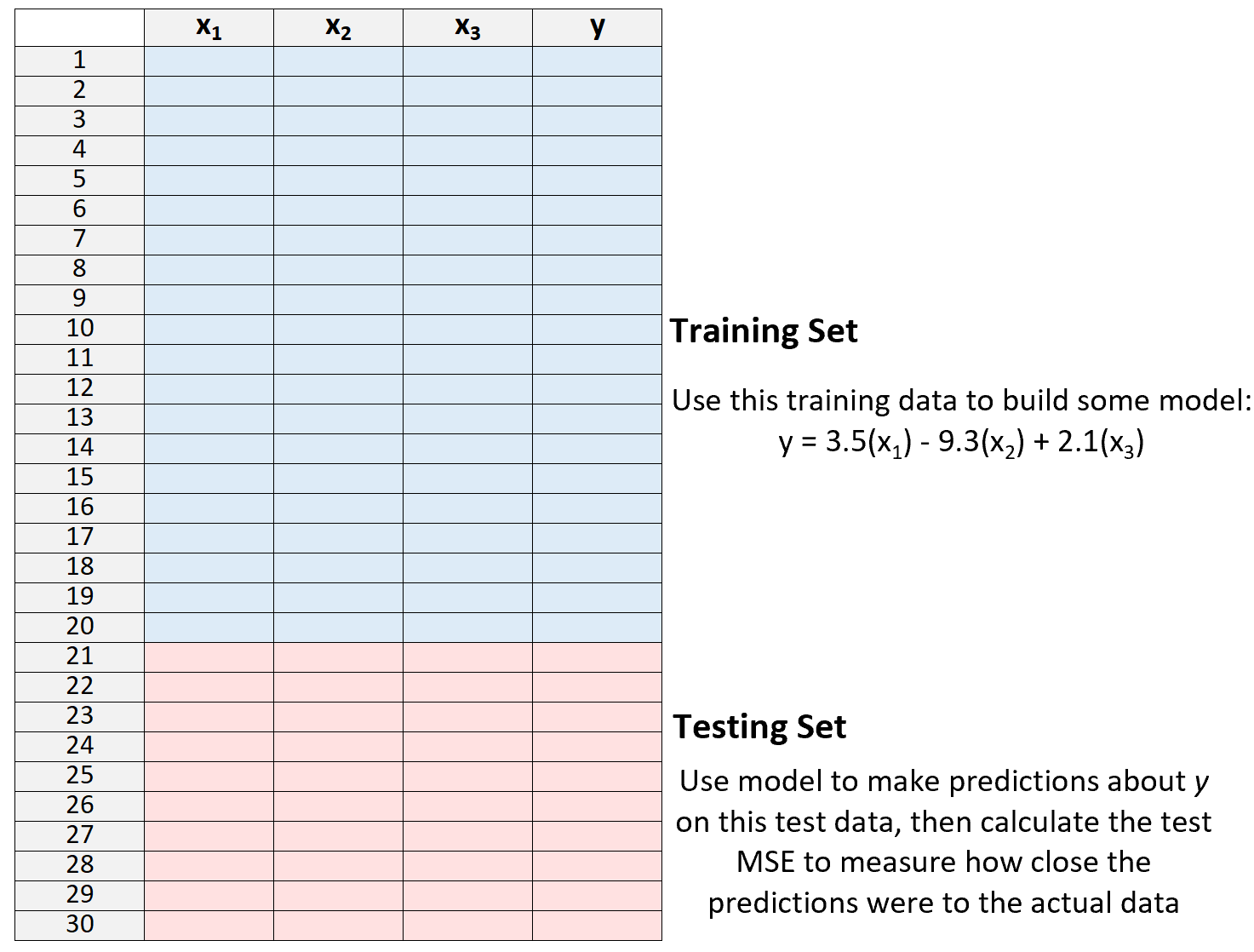
MSE စမ်းသပ်ခြင်းသည် မော်ဒယ်တစ်ခုသည် ယခင်က မမြင်ဖူးသော ဒေတာများပေါ်တွင် မည်မျှ ကောင်းမွန်စွာ စွမ်းဆောင်နိုင်သနည်း၊ ဆိုလိုသည်မှာ မော်ဒယ်ကို “ လေ့ကျင့်ရန်” အတွက် အသုံးမပြုရသေးသည့် ဒေတာကို ပေးပါသည်။
သို့သော်၊ တစ်ခုတည်းသောစမ်းသပ်မှုအစုံကိုအသုံးပြုခြင်း၏အားနည်းချက်မှာ MSE စာမေးပွဲသည်လေ့ကျင့်ရေးနှင့်စမ်းသပ်မှုအစုံတွင်အသုံးပြုသောလေ့လာတွေ့ရှိချက်များပေါ်မူတည်ပြီးသိသိသာသာကွဲပြားနိုင်သည်။
ကျွန်ုပ်တို့သည် လေ့ကျင့်ရေးအစုံနှင့် စမ်းသပ်မှုအစုံအတွက် မတူညီသော စောင့်ကြည့်လေ့လာမှုအစုံကို အသုံးပြုပါက ကျွန်ုပ်တို့၏စမ်းသပ်မှု MSE သည် များစွာပိုကြီးသည် သို့မဟုတ် သေးငယ်သွားနိုင်သည်။
ဤပြဿနာကိုရှောင်ရှားရန်နည်းလမ်းတစ်ခုမှာ မတူညီသောလေ့ကျင့်သင်ကြားမှုနှင့်စမ်းသပ်မှုတစ်ခုစီကိုအသုံးပြု၍ မော်ဒယ်တစ်ခုကိုအကြိမ်ကြိမ်ပြုလုပ်ရန်ဖြစ်ပြီး၊ ထို့နောက်စမ်းသပ်မှု MSE ကိုစမ်းသပ်မှု MSE အားလုံး၏ပျမ်းမျှအဖြစ်တွက်ချက်ပါ။
ဤယေဘူယျနည်းလမ်းကို cross-validation ဟုခေါ်ပြီး ၎င်း၏ သီးခြားပုံစံကို Leave-One-Out cross-validation ဟုခေါ်သည်။
တစ်ခုတည်း-အထွက် Cross-Validation ချန်ထားပါ။
တစ်ခုမှ တစ်ခုမဟုတ်တစ်ခု ဖြတ်ကျော်အတည်ပြုခြင်းသည် မော်ဒယ်တစ်ခုကို အကဲဖြတ်ရန် အောက်ပါချဉ်းကပ်နည်းကို အသုံးပြုသည်-
1. လေ့ကျင့်ရေးအစုံ၏တစ်စိတ်တစ်ပိုင်းအဖြစ် မှတ်သားမှုအားလုံးကို အသုံးပြု၍ ဒေတာအစုံကို လေ့ကျင့်ရေးအစုံနှင့် စမ်းသပ်မှုအစုံသို့ ခွဲလိုက်ပါ-
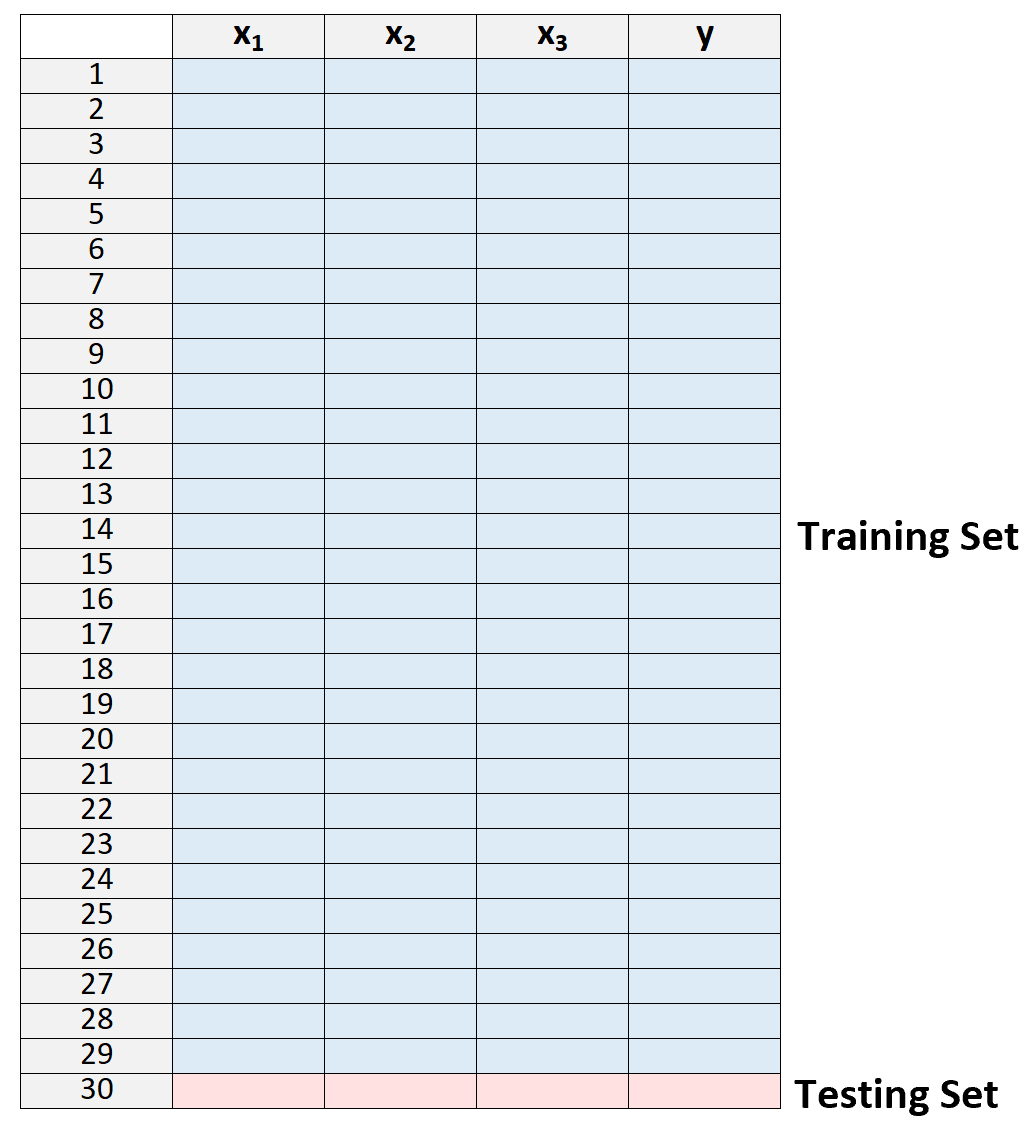
ကျွန်ုပ်တို့သည် လေ့ကျင့်ရေးအစီအစဉ်၏ အပြင်ဘက်တွင် ရှုမြင်မှုတစ်ခုသာ ကျန်ရှိတော့ကြောင်း သတိပြုပါ။ ဤနေရာတွင် နည်းလမ်းသည် “ leave-one-out” cross-validation အမည်ကို ရရှိသည်။
2. လေ့ကျင့်မှုအစုံမှ အချက်အလက်များကိုသာ အသုံးပြု၍ မော်ဒယ်ကို ဖန်တီးပါ။
3. မော်ဒယ်မှ ဖယ်ထုတ်ထားသော တစ်ခုတည်းသော စောင့်ကြည့်မှုတန်ဖိုးကို ခန့်မှန်းရန်နှင့် MSE ကို တွက်ချက်ရန် မော်ဒယ်ကို အသုံးပြုပါ။
4. လုပ်ငန်းစဉ် n အကြိမ်များကို ပြန်လုပ်ပါ။
နောက်ဆုံးတွင်၊ ကျွန်ုပ်တို့သည် ဤလုပ်ငန်းစဉ် n အကြိမ်များ ( n သည် ဒေတာအတွဲရှိ စုစုပေါင်းကြည့်ရှုမှုအရေအတွက်ဖြစ်သည်)၊ အကြိမ်တိုင်းတွင် သတ်မှတ်ထားသော လေ့ကျင့်မှုမှ မတူညီသော ရှုမြင်ချက်ကို ချန်ထားပါ။
ထို့နောက် ကျွန်ုပ်တို့သည် စမ်းသပ်မှု MSE ကို စမ်းသပ်မှု MSE အားလုံး၏ ပျမ်းမျှအဖြစ် တွက်ချက်သည်-
MSE စာမေးပွဲ = (1/n)*ΣMSE i
ရွှေ-
- n- ဒေတာအတွဲတွင် ကြည့်ရှုမှုစုစုပေါင်း
- MSEi- ith မော်ဒယ် အံဝင်ခွင်ကျ ကာလ အတွင်း MSE စမ်းသပ်မှု။
LOOCV ၏ အားသာချက်များနှင့် အားနည်းချက်များ
တစ်ကြိမ်မှ ထွက်ခွာခြင်း အပြန်အလှန်စစ်ဆေးခြင်းသည် အောက်ပါ အကျိုးကျေးဇူးများကို ပေးဆောင်သည်-
- ကျွန်ုပ်တို့သည် မော်ဒယ်တစ်ခုအား n-1 လေ့လာတွေ့ရှိချက်များပါရှိသော ဒေတာအတွဲတစ်ခုနှင့် ထပ်ခါထပ်ခါ ဖြည့်ဆည်းပေးသောကြောင့် တစ်ခုတည်းသော စမ်းသပ်မှုအစုံကို အသုံးပြုခြင်းနှင့် နှိုင်းယှဉ်ပါက MSE စစ်ဆေးမှု၏ ဘက်လိုက်မှု နည်းပါးပါသည်။
- တစ်ခုတည်းသောစမ်းသပ်မှုအစုကိုအသုံးပြုခြင်းနှင့်နှိုင်းယှဉ်ပါက စစ်ဆေးမှု၏ MSE ကို လွန်ကဲစွာမခန့်မှန်းတတ်ပါ။
သို့သော် လက်ဝါးကပ်တိုင် ဖြတ်ကျော်ခြင်းတွင် အောက်ပါ အားနည်းချက်များ ရှိသည်။
- n သည် ကြီးမားသောအခါ ဤလုပ်ငန်းစဉ်ကို အသုံးပြုခြင်းသည် အချိန်ကြာမြင့်နိုင်သည်။
- မော်ဒယ်တစ်ခုသည် အထူးရှုပ်ထွေးပြီး ဒေတာအတွဲတစ်ခုနှင့် အံဝင်ခွင်ကျဖြစ်ရန် အချိန်ကြာမြင့်ပါက ၎င်းသည်လည်း အချိန်ကုန်နိုင်သည်။
- ဒါက တွက်ချက်မှုအရ ဈေးကြီးနိုင်တယ်။
ကံကောင်းထောက်မစွာ၊ ခေတ်မီကွန်ပြူတာသည် နယ်ပယ်အများစုတွင် အလွန်ထိရောက်လာသောကြောင့် LOOCV သည် လွန်ခဲ့သောနှစ်ပေါင်းများစွာကထက် အသုံးပြုရန်ပိုမိုသင့်လျော်သောနည်းလမ်းတစ်ခုဖြစ်သည်။
LOOCV ကို regression နှင့် classification context များတွင်လည်း သုံးနိုင်သည်ကို သတိပြုပါ။ ဆုတ်ယုတ်မှုပြဿနာများအတွက်၊ ၎င်းသည် ခန့်မှန်းချက်များနှင့် အကဲခတ်မှုများကြားရှိ အရင်းပျမ်းမျှစတုရန်းကွာဟချက်အဖြစ် MSE စမ်းသပ်မှုကို တွက်ချက်ပြီး အမျိုးအစားခွဲခြားမှုပြဿနာများတွင် ၎င်းသည် မော်ဒယ်၏ n ထပ်ခါတလဲလဲ ချိန်ညှိမှုများအပေါ် မှန်ကန်စွာ ခွဲခြားထားသော စောင့်ကြည့်မှုရာခိုင်နှုန်းအဖြစ် MSE စမ်းသပ်မှုကို တွက်ချက်သည်။
R & Python တွင် LOOCV ကိုမည်သို့လုပ်ဆောင်ရမည်နည်း။
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် R နှင့် Python တွင် ပေးထားသည့် ပုံစံအတွက် LOOCV ကို မည်သို့ run ရမည်ကို အဆင့်ဆင့် ဥပမာပေးထားပါသည်။
R တွင် တစ်ကြိမ်-အထွက် Cross-Validation ကို ချန်ထားပါ။
Python တွင် One-Out Cross-Validation ကို ချန်ထားပါ။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။