R- တစ်ဆင့်ပြီးတစ်ဆင့် နမူနာတွင် အဓိကအစိတ်အပိုင်း ခွဲခြမ်းစိတ်ဖြာခြင်း။
Principal components analysis, မကြာခဏအတိုကောက် PCA, သည် ကြီးကြပ်မှုမရှိသော စက်သင်ယူမှုနည်းပညာတစ်ခုဖြစ်ပြီး ဒေတာအစုတစ်ခုအတွင်း ကွဲလွဲမှုအများအပြားကို ရှင်းပြသည့် အဓိကအစိတ်အပိုင်းများ—မူရင်းကြိုတင်ခန့်မှန်းသူများ၏မျဉ်းကြောင်းပေါင်းစပ်မှုများကိုရှာဖွေရန်ရှာဖွေသည့်- ဒေတာအစုအဝေးတစ်ခုဖြစ်သည်။
PCA ၏ပန်းတိုင်သည် မူလဒေတာသတ်မှတ်မှုထက် ကိန်းရှင်များထက်နည်းသော ကိန်းရှင်များပါသည့် ဒေတာအတွဲတစ်ခုတွင် ကွဲပြားမှုအများစုကို ရှင်းပြရန်ဖြစ်သည်။
p variables များပါသည့် ဒေတာအတွဲအတွက်၊ ကိန်းရှင်များ အတွဲလိုက် ပေါင်းစပ်မှုတစ်ခုစီ၏ ကွဲလွဲချက်များကို ကျွန်ုပ်တို့ ဆန်းစစ်နိုင်သော်လည်း ကွဲလွဲမှုအရေအတွက်သည် အလွန်လျင်မြန်စွာ ကြီးမားနိုင်ပါသည်။
p ခန့်မှန်းသူများအတွက်၊ p(p-1)/2 point cloud များရှိပါသည်။
ထို့ကြောင့် p = 15 ကြိုတင်တွက်ဆထားသော ဒေတာအတွဲတစ်ခုအတွက်၊ မတူညီသော အပိုင်းခွဲ ၁၀၅ ခု ရှိမည်ဖြစ်သည်။
ကံကောင်းထောက်မစွာ၊ PCA သည် ဒေတာကွဲလွဲမှုကို တတ်နိုင်သမျှ ဖမ်းယူနိုင်သည့် ဒေတာအစုံ၏ အနိမ့်ပိုင်း ကိုယ်စားပြုမှုကို ရှာဖွေရန် နည်းလမ်းတစ်ခု ပေးထားသည်။
အကယ်၍ ကျွန်ုပ်တို့သည် ကွဲပြားမှုအများစုကို အတိုင်းအတာနှစ်ရပ်ဖြင့် ဖမ်းယူနိုင်ပါက၊ ကျွန်ုပ်တို့သည် မူလဒေတာအတွဲမှ လေ့လာတွေ့ရှိချက်အားလုံးကို ရိုးရှင်းသော အပိုင်းအစတစ်ခုအဖြစ် ပုံဖော်နိုင်သည်။
ကျွန်ုပ်တို့၏ အဓိကအစိတ်အပိုင်းများကို ရှာဖွေနည်းမှာ အောက်ပါအတိုင်းဖြစ်သည်။
p ခန့်မှန်းချက်များ နှင့်အတူ ဒေတာ အစုံကို ပေးသည် : _
- Z m = ΣΦ jm _
- Z 1 သည် ကွဲလွဲမှုကို တတ်နိုင်သမျှ ဖမ်းယူနိုင်သော ခန့်မှန်းသူများ၏ မျဉ်းဖြောင့်ပေါင်းစပ်မှုဖြစ်သည်။
- Z 2 သည် အစီအစဥ်အတိုင်း (ဆိုလိုသည်မှာ Z 1 မှ ဆက်စပ်မှုမရှိသော) ဖြစ်နေစဉ် ကွဲလွဲမှုကို အများဆုံးဖမ်းယူမည့် ခန့်မှန်းသူများ၏နောက်ထပ်တစ်ပြေးညီပေါင်းစပ်မှုဖြစ်သည်။
- ထို့နောက် Z 3 သည် Z 2 သို့ အစီအစဥ်အတိုင်းဖြစ်နေစဉ် ကွဲလွဲမှုအရှိဆုံးကို ဖမ်းယူမည့် ခန့်မှန်းတွက်ချက်မှုများ၏နောက်ထပ်တစ်ပြေးညီပေါင်းစပ်မှုဖြစ်သည်။
- နောက် … ပြီးတော့။
လက်တွေ့တွင်၊ ကျွန်ုပ်တို့သည် မူရင်းကြိုတင်ခန့်မှန်းသူများ၏ မျဉ်းဖြောင့်ပေါင်းစပ်မှုများကို တွက်ချက်ရန် အောက်ပါအဆင့်များကို အသုံးပြုပါသည်။
1. ကိန်းရှင်တစ်ခုစီအား ပျမ်းမျှ 0 နှင့် စံသွေဖည်မှု 1 ရှိရန် စကေးချပါ။
2. အတိုင်းအတာ ကိန်းရှင်များအတွက် တူညီသော မက်ထရစ်ကို တွက်ချက်ပါ။
3. covariance matrix ၏ eigenvalues များကို တွက်ချက်ပါ။
linear အက္ခရာသင်္ချာကို အသုံးပြု၍ အကြီးဆုံး eigenvalue နှင့် ကိုက်ညီသော eigenvector သည် ပထမဆုံး အဓိက အစိတ်အပိုင်းဖြစ်ကြောင်း ပြသနိုင်ပါသည်။ တစ်နည်းအားဖြင့်၊ ဤအထူးဟောကိန်းထုတ်သူများ၏ပေါင်းစပ်မှုသည် ဒေတာတွင် အကြီးမားဆုံးကွဲလွဲမှုကို ရှင်းပြသည်။
ဒုတိယအကြီးဆုံး eigenvalue နှင့် သက်ဆိုင်သော eigenvector သည် ဒုတိယ အဓိက အစိတ်အပိုင်း ဖြစ်သည် ။
ဤသင်ခန်းစာသည် R တွင် ဤလုပ်ငန်းစဉ်ကို လုပ်ဆောင်ပုံအဆင့်ဆင့်ကို ဥပမာပေးထားသည်။
အဆင့် 1: ဒေတာကို တင်ပါ။
ဒေတာကို မြင်ယောင်ပြီး ခြယ်လှယ်ရန် အသုံးဝင်သော လုပ်ဆောင်ချက်များ များစွာပါရှိသော Tidyverse ပက်ကေ့ဂျ်ကို ဦးစွာ တင်ပေးပါမည်။
library (tidyverse)
ဤဥပမာအတွက်၊ လူသတ်မှု ၊ ချေမှုန်းမှု ၊ နှင့် မုဒိမ်းမှုများ အတွက် US ပြည်နယ်တစ်ခုစီတွင် နေထိုင်သူ 100,000 တစ်ဦးလျှင် ဖမ်းဆီးခံရမှုအရေအတွက်ပါရှိသော R တွင်တည်ဆောက်ထားသော USArrests dataset ကို အသုံးပြုပါမည်။
၎င်းတွင် မြို့ပြဒေသများတွင် နေထိုင်သော ပြည်နယ်တစ်ခုစီ၏ လူဦးရေ ရာခိုင်နှုန်း၊ UrbanPop လည်း ပါဝင်သည်။
အောက်ပါကုဒ်သည် ဒေတာအတွဲ၏ ပထမတန်းများကို မည်သို့တင်ရန်နှင့် ပြသရမည်ကို ပြသသည်-
#load data data ("USArrests") #view first six rows of data head(USArrests) Murder Assault UrbanPop Rape Alabama 13.2 236 58 21.2 Alaska 10.0 263 48 44.5 Arizona 8.1 294 80 31.0 Arkansas 8.8 190 50 19.5 California 9.0 276 91 40.6 Colorado 7.9 204 78 38.7
အဆင့် 2- အဓိကအစိတ်အပိုင်းများကို တွက်ချက်ပါ။
ဒေတာကို တင်ပြီးနောက်၊ ဒေတာအတွဲ၏ အဓိကအစိတ်အပိုင်းများကို တွက်ချက်ရန် R ၏ built-in လုပ်ဆောင်ချက် prcomp() ကို အသုံးပြုနိုင်ပါသည်။
စကေး = TRUE ကို သတ်မှတ်ရန် သေချာပါစေ။ သို့မှသာ ဒေတာအတွဲရှိ ကိန်းရှင်တစ်ခုစီကို ပျမ်းမျှ 0 နှင့် အဓိကအစိတ်အပိုင်းများကို မတွက်ချက်မီ 1 ၏ စံသွေဖည်မှုရှိစေရန် စကေးသတ်မှတ်ပါ။
R ရှိ eigenvectors များသည် ပုံသေအားဖြင့် အနုတ်လက္ခဏာဆောင်သည့် ဦးတည်ချက်တွင်ရှိကြောင်းကိုလည်း သတိပြုပါ၊ ထို့ကြောင့် အမှတ်အသားများကို ပြောင်းပြန်လှန်ရန် -1 ဖြင့် မြှောက်ပါမည်။
#calculate main components results <- prcomp(USArrests, scale = TRUE ) #reverse the signs results$rotation <- -1*results$rotation #display main components results$rotation PC1 PC2 PC3 PC4 Murder 0.5358995 -0.4181809 0.3412327 -0.64922780 Assault 0.5831836 -0.1879856 0.2681484 0.74340748 UrbanPop 0.2781909 0.8728062 0.3780158 -0.13387773 Rape 0.5434321 0.1673186 -0.8177779 -0.08902432
ပထမအဓိကအစိတ်အပိုင်း (PC1) သည် လူသတ်မှု၊ ချေမှုန်းရေးနှင့် မုဒိမ်းမှုများအတွက် တန်ဖိုးမြင့်မားကြောင်း ကျွန်ုပ်တို့တွေ့မြင်နိုင်သည်၊ ဤအဓိကအစိတ်အပိုင်းသည် ဤကိန်းရှင်များတွင် အကြီးကျယ်ဆုံးကွဲလွဲမှုကို ဖော်ပြကြောင်း ဖော်ပြသည်။
ဒုတိယအဓိကအစိတ်အပိုင်း (PC2) သည် UrbanPop အတွက် မြင့်မားသောတန်ဖိုးရှိကြောင်း၊ ဤအဓိကအစိတ်အပိုင်းသည် မြို့ပြလူဦးရေကို အလေးပေးကြောင်း ညွှန်ပြနေပါသည်။
ပြည်နယ်တစ်ခုစီအတွက် အဓိကအစိတ်အပိုင်းရမှတ်များကို ရလဒ် $x တွင် သိမ်းဆည်းထားကြောင်း သတိပြုပါ။ လက္ခဏာများကို ပြောင်းပြန်လှန်ရန် ဤရမှတ်များကို -1 ဖြင့် မြှောက်ပေးပါမည်။
#reverse the signs of the scores results$x <- -1*results$x #display the first six scores head(results$x) PC1 PC2 PC3 PC4 Alabama 0.9756604 -1.1220012 0.43980366 -0.154696581 Alaska 1.9305379 -1.0624269 -2.01950027 0.434175454 Arizona 1.7454429 0.7384595 -0.05423025 0.826264240 Arkansas -0.1399989 -1.1085423 -0.11342217 0.180973554 California 2.4986128 1.5274267 -0.59254100 0.338559240 Colorado 1.4993407 0.9776297 -1.08400162 -0.001450164
အဆင့် 3- ရလဒ်များကို biplot ဖြင့်မြင်ယောင်ကြည့်ပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် ပထမနှင့် ဒုတိယ အဓိကအစိတ်အပိုင်းများကို axes အဖြစ်အသုံးပြုသည့် ဒေတာအတွဲရှိ လေ့လာတွေ့ရှိချက်တစ်ခုစီကို အပိုင်းအစတစ်ခုစီတွင် ပုံဖော်ထားသည့် biplot တစ်ခုကို ဖန်တီးနိုင်သည်-
စကေး = 0 သည် ကွက်လပ်ရှိ မြှားများကို loadings ကိုယ်စားပြုရန် စကေးချိန်ထားကြောင်း သေချာစေပါသည်။
biplot(results, scale = 0 )
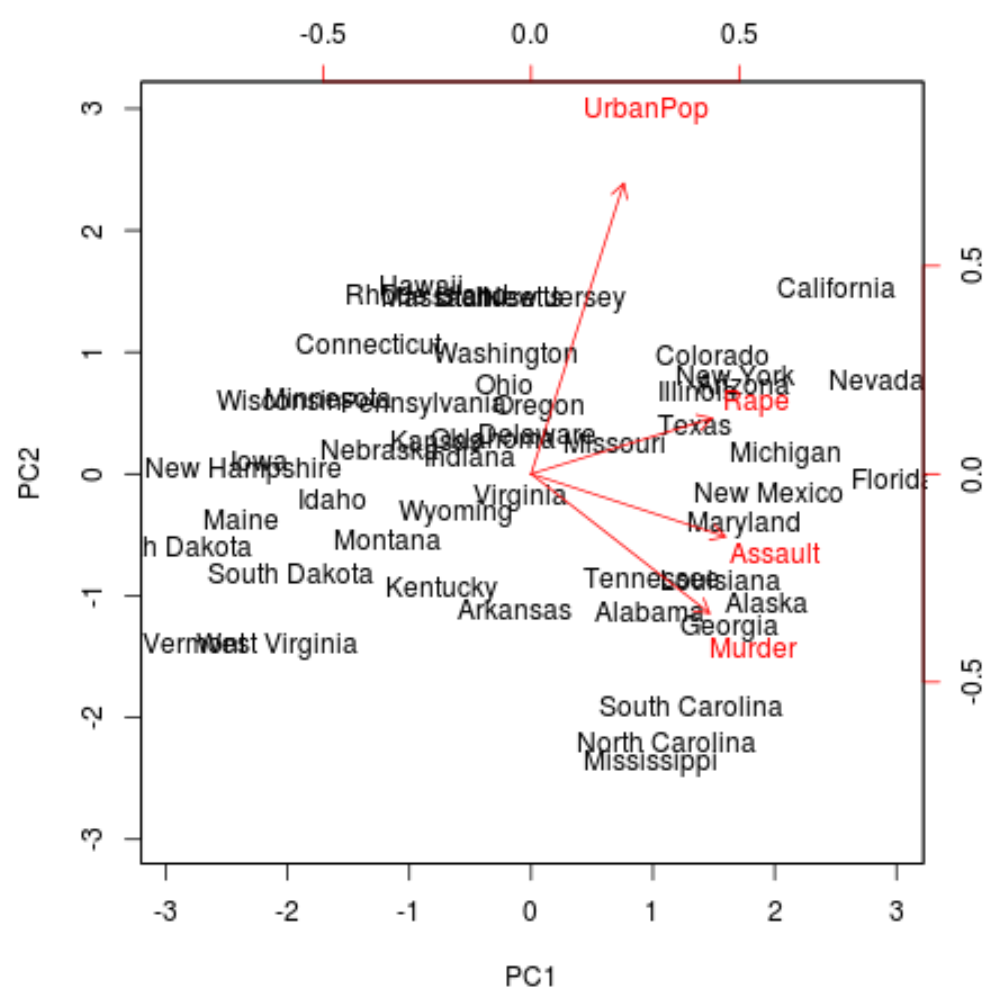
ဇာတ်ကွက်မှ ကျွန်ုပ်တို့သည် ရိုးရှင်းသော နှစ်ဘက်မြင် အာကာသအတွင်း ကိုယ်စားပြုသည့် ပြည်နယ် 50 ခုစီကို မြင်တွေ့နိုင်သည်။
ဂရပ်ပေါ်ရှိ တစ်ခုနှင့်တစ်ခု နီးကပ်နေသော ပြည်နယ်များသည် မူရင်းဒေတာအတွဲရှိ ကိန်းရှင်များနှင့် စပ်လျဉ်းသည့် အလားတူဒေတာပုံစံများရှိသည်။
အချို့သောပြည်နယ်များသည် အခြားနိုင်ငံများထက် အချို့သော ရာဇ၀တ်မှုများနှင့် ပိုမိုပြင်းထန်စွာ ဆက်နွယ်နေကြောင်းကိုလည်း ကျွန်ုပ်တို့ တွေ့မြင်နိုင်သည်။ ဥပမာအားဖြင့်၊ ဂျော်ဂျီယာသည် ဇာတ်ကွက်ရှိ လူသတ် ကိန်းရှင်နှင့် အနီးဆုံးပြည်နယ်ဖြစ်သည်။
မူရင်းဒေတာအတွဲတွင် လူသတ်မှုနှုန်းအမြင့်ဆုံးပြည်နယ်များကို ကြည့်ပါက၊ ဂျော်ဂျီယာစာရင်းတွင် အမှန်တကယ် ထိပ်ဆုံးရောက်နေသည်ကို တွေ့နိုင်သည်-
#display states with highest murder rates in original dataset head(USArrests[ order (-USArrests$Murder),]) Murder Assault UrbanPop Rape Georgia 17.4 211 60 25.8 Mississippi 16.1 259 44 17.1 Florida 15.4 335 80 31.9 Louisiana 15.4 249 66 22.2 South Carolina 14.4 279 48 22.5 Alabama 13.2 236 58 21.2
အဆင့် 4- အဓိကအစိတ်အပိုင်းတစ်ခုစီမှ ရှင်းပြထားသော ကွဲလွဲမှုကို ရှာပါ။
အဓိကအစိတ်အပိုင်းတစ်ခုစီမှ ရှင်းပြထားသော မူရင်းဒေတာအတွဲ၏ စုစုပေါင်းကွဲလွဲမှုကို တွက်ချက်ရန် အောက်ပါကုဒ်ကို အသုံးပြုနိုင်ပါသည်။
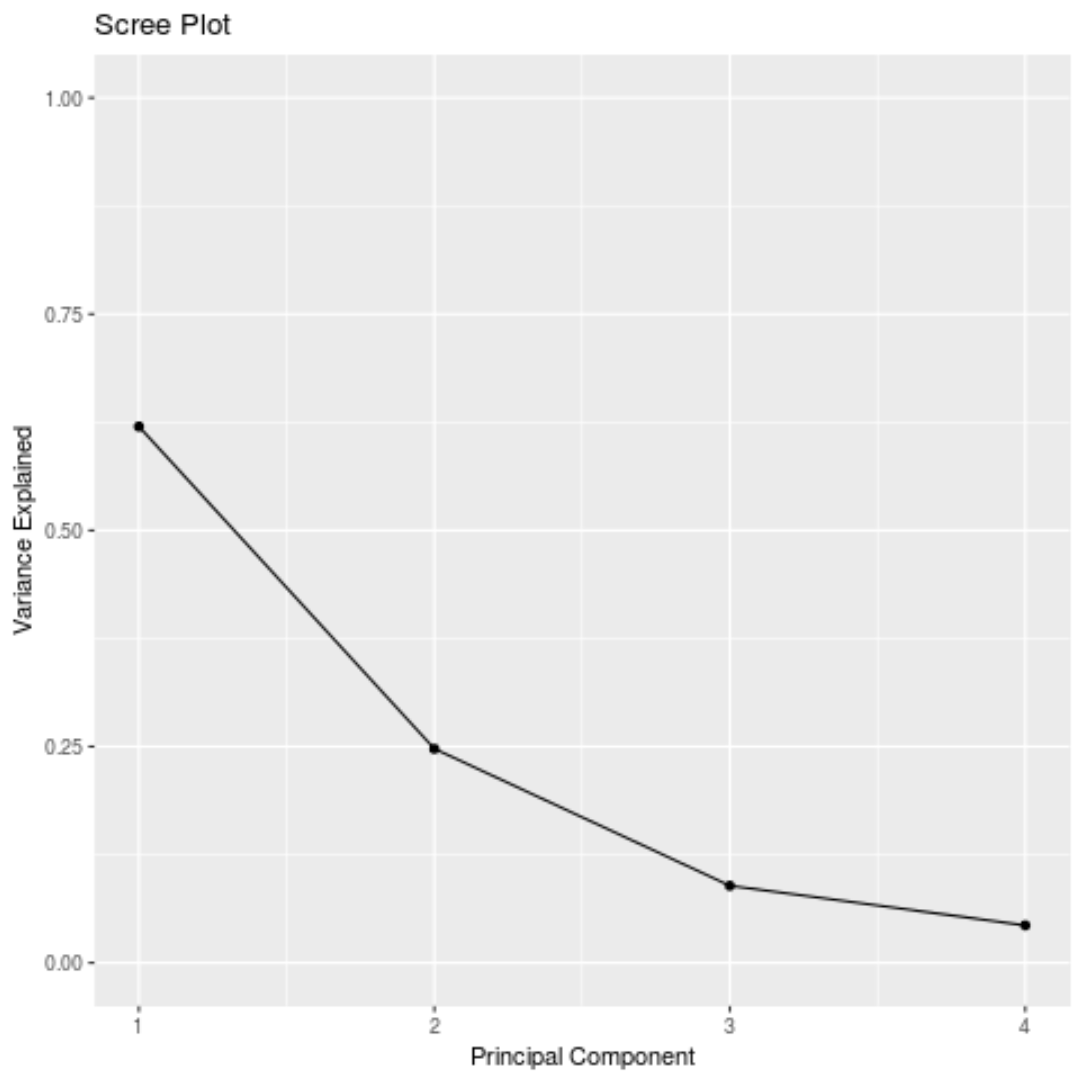
#calculate total variance explained by each principal component results$sdev^2 / sum (results$sdev^2) [1] 0.62006039 0.24744129 0.08914080 0.04335752
ရလဒ်များမှ၊ ကျွန်ုပ်တို့သည် အောက်ပါတို့ကို ကြည့်ရှုနိုင်သည်။
- ပထမအဓိကအစိတ်အပိုင်းသည် ဒေတာအတွဲရှိ စုစုပေါင်းကွဲလွဲမှု၏ 62% ကို ရှင်းပြထားသည်။
- ဒုတိယအဓိကအစိတ်အပိုင်းသည် ဒေတာအတွဲရှိ စုစုပေါင်းကွဲလွဲမှု၏ 24.7% ကို ရှင်းပြထားသည်။
- တတိယအဓိကအစိတ်အပိုင်းသည် ဒေတာအတွဲရှိ စုစုပေါင်းကွဲလွဲမှု၏ 8.9% ကို ရှင်းပြထားသည်။
- စတုတ္ထအဓိကအစိတ်အပိုင်းသည် ဒေတာအတွဲရှိ စုစုပေါင်းကွဲလွဲမှု၏ 4.3% ကို ရှင်းပြထားသည်။
ထို့ကြောင့်၊ ပထမအဓိကအစိတ်အပိုင်းနှစ်ခုသည် ဒေတာရှိ စုစုပေါင်းကွဲလွဲမှုအများစုကို ရှင်းပြသည်။
အဘယ်ကြောင့်ဆိုသော် ယခင် biplot သည် လေ့လာတွေ့ရှိချက်တစ်ခုစီကို မူလဒေတာမှ ပထမအဓိက အစိတ်အပိုင်းနှစ်ခုကိုသာ ထည့်သွင်းစဉ်းစားသည့် ခွဲခြမ်းစိတ်ဖြာမှုတစ်ခုသို့ စီစဥ်ထားသောကြောင့် ကောင်းသောလက္ခဏာဖြစ်သည်။
ထို့ကြောင့်၊ တစ်ခုနှင့်တစ်ခုတူညီသောပြည်နယ်များကိုခွဲခြားသတ်မှတ်ရန် biplot မှပုံစံများကိုစစ်ဆေးရန်တရားဝင်သည်။
PCA ရလဒ်များကိုမြင်ယောင်ရန် အဓိကအစိတ်အပိုင်းတစ်ခုစီမှ ရှင်းပြထားသော စုစုပေါင်းကွဲလွဲမှုကိုပြသသည့် ဂရပ်တစ်ခု – scree plot ကို ဖန်တီးနိုင်သည်-
#calculate total variance explained by each principal component var_explained = results$sdev^2 / sum (results$sdev^2) #create scree plot qplot(c(1:4), var_explained) + geom_line() + xlab(" Principal Component ") + ylab(" Variance Explained ") + ggtitle(" Scree Plot ") + ylim(0, 1)
လက်တွေ့တွင် အဓိကအစိတ်အပိုင်းခွဲခြမ်းစိတ်ဖြာခြင်း။
လက်တွေ့တွင်၊ PCA ကို အကြောင်းအရင်း နှစ်ခုကြောင့် အများဆုံးအသုံးပြုသည်-
1. Exploratory Data Analysis – ကျွန်ုပ်တို့သည် ဒေတာအတွဲတစ်ခုကို ဦးစွာရှာဖွေနေပြီး ဒေတာတစ်ခုနှင့်တစ်ခုအလားသဏ္ဍာန်အလားတူဆုံးဖြစ်ကြောင်း နားလည်လိုသောအခါတွင် ကျွန်ုပ်တို့သည် PCA ကိုအသုံးပြုပါသည်။
2. Principal Component Regression – ထို့နောက် Principal Component Regression တွင် အသုံးပြုနိုင်သည့် အဓိကအစိတ်အပိုင်းများကို တွက်ချက်ရန် PCA ကို အသုံးပြုနိုင်သည်။ ဒေတာအစုတစ်ခုတွင် ကြိုတင်ခန့်မှန်းသူများကြားတွင် ပေါင်းစပ်မျဥ်းညီထွေ ရှိသည့်အခါ ဤဆုတ်ယုတ်မှုအမျိုးအစားကို မကြာခဏအသုံးပြုသည်။
ဤသင်ခန်းစာတွင်အသုံးပြုသည့် R ကုဒ်အပြည့်အစုံကို ဤနေရာတွင် တွေ့နိုင်ပါသည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။