Python တွင် precision recall curve တစ်ခုကို ဖန်တီးနည်း
စက်သင်ယူမှုတွင် အမျိုးအစားခွဲခြင်းပုံစံများကို အသုံးပြုသည့်အခါ၊ မော်ဒယ်အရည်အသွေးကို အကဲဖြတ်ရန် ကျွန်ုပ်တို့အသုံးပြုလေ့ရှိသည့် မက်ထရစ်နှစ်ခုမှာ တိကျမှုနှင့် ပြန်လည်သိမ်းဆည်းခြင်းပင်ဖြစ်သည်။
တိကျမှု – စုစုပေါင်း အပြုသဘောဆောင်သော ခန့်မှန်းချက်များနှင့် ဆက်စပ်သော အပြုသဘောဆောင်သော ခန့်မှန်းချက်များကို မှန်ကန်စွာ ပြင်ပါ။
၎င်းကို အောက်ပါအတိုင်း တွက်ချက်သည်။
- တိကျမှု = True Positives / (True Positives + False Positives)
သတိပေးချက် – စုစုပေါင်းအမှန်တကယ် အပြုသဘောဆောင်သည့် အပြုသဘောဆောင်သော ခန့်မှန်းချက်များကို ပြုပြင်ခြင်း။
၎င်းကို အောက်ပါအတိုင်း တွက်ချက်သည်။
- သတိပေးချက် = စစ်မှန်သော အပြုသဘောဆောင်မှုများ / (စစ်မှန်သော အပြုသဘောဆောင်မှုများ + မှားယွင်းသော အနုတ်လက္ခဏာများ)
မော်ဒယ်တစ်ခု၏ တိကျမှုနှင့် ပြန်လည်သိမ်းဆည်းမှုကို မြင်သာစေရန်၊ ကျွန်ုပ်တို့သည် တိကျစွာ ပြန်လည်သိမ်းဆည်းမှုမျဉ်းကို ဖန်တီးနိုင်သည်။ ဤမျဉ်းကွေးသည် မတူညီသော အဆင့်များအတွက် တိကျမှုနှင့် ပြန်လည်သိမ်းဆည်းမှုကြား အပေးအယူကို ပြသသည်။
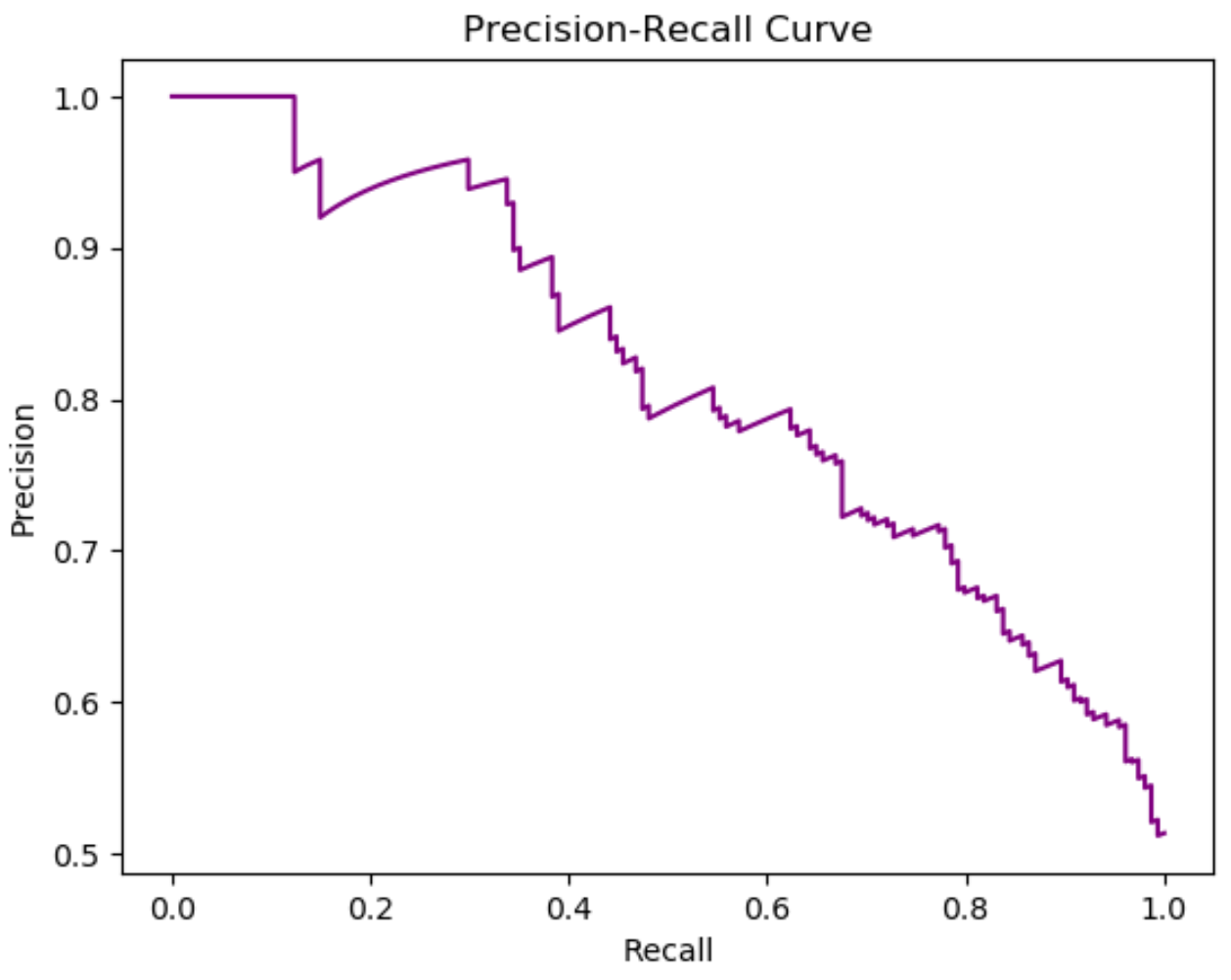
အောက်ဖော်ပြပါ အဆင့်ဆင့် ဥပမာသည် Python ရှိ ထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံအတွက် တိကျသော ပြန်လည်သိမ်းဆည်းမှုမျဉ်းကို မည်သို့ဖန်တီးရမည်ကို ပြသထားသည်။
အဆင့် 1- ပက်ကေ့ဂျ်များကို တင်သွင်းပါ။
ပထမဦးစွာ လိုအပ်သော ပက်ကေ့ဂျ်များကို တင်သွင်းပါမည်။
from sklearn import datasets from sklearn. model_selection import train_test_split from sklearn. linear_model import LogisticRegression from sklearn. metrics import precision_recall_curve import matplotlib. pyplot as plt
အဆင့် 2- ထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံကို အံကိုက်လုပ်ပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် ဒေတာအတွဲတစ်ခုကို ဖန်တီးပြီး ၎င်းနှင့် ထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံကို အံကိုက်လုပ်ပါမည်။
#create dataset with 5 predictor variables
X, y = datasets. make_classification (n_samples= 1000 ,
n_features= 4 ,
n_informative= 3 ,
n_redundant= 1 ,
random_state= 0 )
#split dataset into training and testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size= .3 , random_state= 0 )
#fit logistic regression model to dataset
classifier = LogisticRegression()
classify. fit (X_train, y_train)
#use logistic regression model to make predictions
y_score = classify. predict_proba (X_test)[:, 1 ]
အဆင့် 3- တိကျစွာပြန်ခေါ်သည့်မျဉ်းကွေးကို ဖန်တီးပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် မော်ဒယ်၏ တိကျမှုနှင့် ပြန်လည်သိမ်းဆည်းမှုကို တွက်ချက်ပြီး တိကျစွာ ပြန်လည်ခေါ်ယူမှုမျဉ်းကို ဖန်တီးမည်-
#calculate precision and recall
precision, recall, thresholds = precision_recall_curve(y_test, y_score)
#create precision recall curve
fig, ax = plt. subplots ()
ax. plot (recall, precision, color=' purple ')
#add axis labels to plot
ax. set_title (' Precision-Recall Curve ')
ax. set_ylabel (' Precision ')
ax. set_xlabel (' Recall ')
#displayplot
plt. show ()
x-axis သည် recall ကိုပြသပြီး y-axis သည် မတူညီသော thresholds အတွက် တိကျမှုကိုပြသသည်။
ပြန်လည်သိမ်းဆည်းမှု တိုးလာသည်နှင့်အမျှ တိကျမှု လျော့နည်းလာသည်ကို သတိပြုပါ။
၎င်းသည် မက်ထရစ်နှစ်ခုကြား ညှိနှိုင်းမှုကို ကိုယ်စားပြုသည်။ ကျွန်ုပ်တို့၏ မော်ဒယ်ကို ပြန်လည်သိမ်းဆည်းမှု တိုးမြှင့်ရန်၊ တိကျမှု လျော့နည်းလာပြီး အပြန်အလှန်အားဖြင့် လိုအပ်သည်။
ထပ်လောင်းအရင်းအမြစ်များ
Python တွင် Logistic Regression ကို မည်သို့လုပ်ဆောင်မည်နည်း။
Python တွင် Confusion Matrix ဖန်တီးနည်း
ROC Curve (ဥပမာများနှင့်အတူ) အဓိပါယ်ဖွင့်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။