R တွင် အနိမ့်ဆုံး စတုရန်းပုံနည်းလမ်းကို အသုံးပြုနည်း
အနည်းဆုံး စတုရန်းပုံနည်းလမ်း သည် ပေးထားသော ဒေတာအစုအဝေးနှင့် အကိုက်ညီဆုံး ဆုတ်ယုတ်မှုမျဉ်းကို ရှာဖွေရန် ကျွန်ုပ်တို့ အသုံးပြုနိုင်သည့် နည်းလမ်းဖြစ်သည်။
R တွင် ဆုတ်ယုတ်မှုမျဉ်းနှင့် ကိုက်ညီရန် အနည်းဆုံး စတုရန်းပုံနည်းလမ်းကို အသုံးပြုရန်၊ ကျွန်ုပ်တို့သည် lm() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်သည်။
ဤလုပ်ဆောင်ချက်သည် အောက်ပါအခြေခံ syntax ကိုအသုံးပြုသည်-
model <- lm(response ~ predictor, data=df)
အောက်ဖော်ပြပါ ဥပမာသည် ဤလုပ်ဆောင်ချက်ကို R တွင်အသုံးပြုပုံကို ပြသထားသည်။
ဥပမာ- R တွင် အနည်းဆုံး နှစ်ထပ်နည်းလမ်း
အတန်းတစ်ခန်းရှိ ကျောင်းသား ၁၅ ဦးအတွက် သင်ကြားသည့် နာရီအရေအတွက်နှင့် သက်ဆိုင်ရာ စာမေးပွဲရမှတ်ကို ပြသသည့် R တွင် အောက်ပါဒေတာဘောင်တစ်ခုရှိသည် ဆိုပါစို့။
#create data frame df <- data. frame (hours=c(1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14), score=c(64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89)) #view first six rows of data frame head(df) hours score 1 1 64 2 2 66 3 4 76 4 5 73 5 5 74 6 6 81
ဤဒေတာနှင့် ဆုတ်ယုတ်မှုမျဉ်းကို အံဝင်ခွင်ကျဖြစ်စေရန်အတွက် အနည်းဆုံး စတုရန်းပုံနည်းလမ်းကို အသုံးပြုရန် lm() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်ပါသည်။
#use method of least squares to fit regression line model <- lm(score ~ hours, data=df) #view regression model summary summary(model) Call: lm(formula = score ~ hours, data = df) Residuals: Min 1Q Median 3Q Max -5,140 -3,219 -1,193 2,816 5,772 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 65,334 2,106 31,023 1.41e-13 *** hours 1.982 0.248 7.995 2.25e-06 *** --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.641 on 13 degrees of freedom Multiple R-squared: 0.831, Adjusted R-squared: 0.818 F-statistic: 63.91 on 1 and 13 DF, p-value: 2.253e-06
ခန့်မှန်း ရလဒ်ကော်လံရှိ တန်ဖိုးများမှ၊ အောက်ပါ တပ်ဆင်ထားသော ဆုတ်ယုတ်မှုမျဉ်းကို ကျွန်ုပ်တို့ ရေးသားနိုင်သည်-
စာမေးပွဲရမှတ် = 65.334 + 1.982 (နာရီ)၊
ဤသည်မှာ မော်ဒယ်ရှိ ကိန်းဂဏန်းတစ်ခုစီကို မည်သို့အဓိပ္ပာယ်ဖွင့်ဆိုနိုင်သည်-
- ကြားဖြတ် : 0 နာရီ စာသင်သော ကျောင်းသားအတွက် မျှော်မှန်း စာမေးပွဲ ရမှတ်မှာ 65.334 ဖြစ်သည်။
- နာရီများ : လေ့လာမှုနောက်ထပ်နာရီတိုင်းအတွက် မျှော်မှန်းထားသော စာမေးပွဲရမှတ်သည် 1,982 တိုးလာသည်။
ကျောင်းသားတစ်ဦး၏ ဖြေဆိုချိန်ပေါ်မူတည်၍ ရရှိမည့် စာမေးပွဲအဆင့်ကို ခန့်မှန်းရန် ဤညီမျှခြင်းအား ကျွန်ုပ်တို့ အသုံးပြုနိုင်ပါသည်။
ဥပမာအားဖြင့်၊ ကျောင်းသားတစ်ဦးသည် 5 နာရီကြာလေ့လာပါက၊ ၎င်းတို့၏စာမေးပွဲရမှတ်မှာ 75.244 ဖြစ်မည်ဟု ကျွန်ုပ်တို့ခန့်မှန်းထားပါမည်။
စာမေးပွဲရမှတ် = 65.334 + 1.982(5) = 75.244
နောက်ဆုံးတွင်၊ ကျွန်ုပ်တို့သည် ကွက်ကွက်ပေါ်တွင် တပ်ဆင်ထားသော ဆုတ်ယုတ်မှုမျဉ်းဖြင့် မူရင်းဒေတာ၏ ခွဲခြမ်းစိပ်ဖြာမှုကို ဖန်တီးနိုင်သည်-
#create scatter plot of data plot(df$hours, df$score, pch=16, col=' steelblue ') #add fitted regression line to scatter plot abline(model)
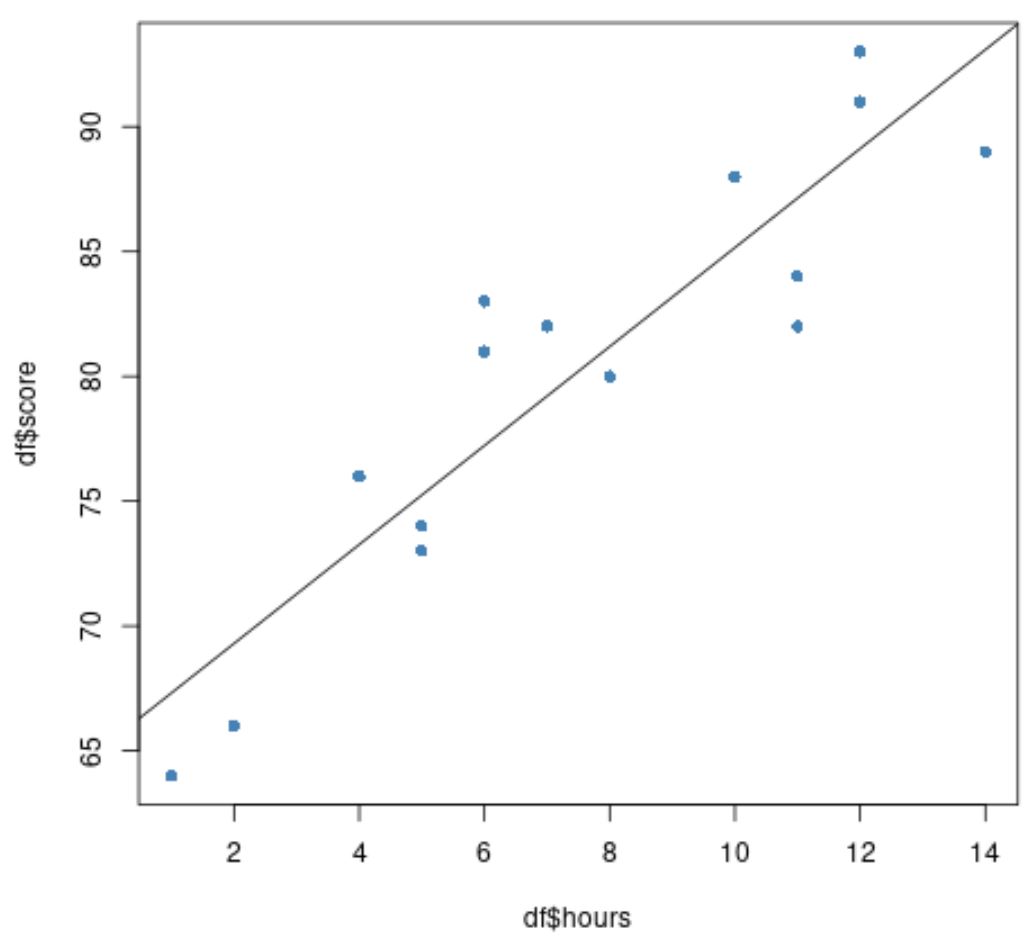
အပြာရောင် စက်ဝိုင်းများသည် ဒေတာကို ကိုယ်စားပြုပြီး အနက်ရောင်မျဉ်းသည် တပ်ဆင်ထားသော ဆုတ်ယုတ်မှုမျဉ်းကို ကိုယ်စားပြုသည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် R တွင် အခြားဘုံအလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
R တွင်ကျန်ရှိသောကွက်ကွက်ဖန်တီးနည်း
R တွင် multicollinearity ကိုစမ်းသပ်နည်း
R တွင် မျဉ်းကွေး အံဝင်ခွင်ကျ ပြုလုပ်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။