ပန်ဒါများ- အတန်းတစ်ခုလျှင် ကော်လံအရေအတွက် မတူညီသော csv ကို တင်သွင်းပါ။
အတန်းတစ်ခုစီတွင် ကော်လံအရေအတွက် မတူညီသောအခါတွင် CSV ဖိုင်ကို ပန်ဒါများထဲသို့ တင်သွင်းရန် အောက်ပါအခြေခံ syntax ကို အသုံးပြုနိုင်ပါသည်။
df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))
range() လုပ်ဆောင်ချက်အတွင်းရှိ တန်ဖိုးသည် အများဆုံး ကော်လံအရေအတွက်နှင့် အတန်းရှိ ကော်လံအရေအတွက် ဖြစ်သင့်သည်။
အောက်ဖော်ပြပါ ဥပမာသည် ဤ syntax ကို လက်တွေ့တွင် မည်သို့အသုံးပြုရမည်ကို ပြသထားသည်။
ဥပမာ- အတန်းတစ်ခုလျှင် ကော်လံအရေအတွက် မတူညီသော Pandas သို့ CSV ကို ထည့်သွင်းပါ။
ကျွန်ုပ်တို့တွင် uneven_data.csv ဟုခေါ်သော အောက်ပါ CSV ဖိုင်ရှိသည် ဆိုကြပါစို့။
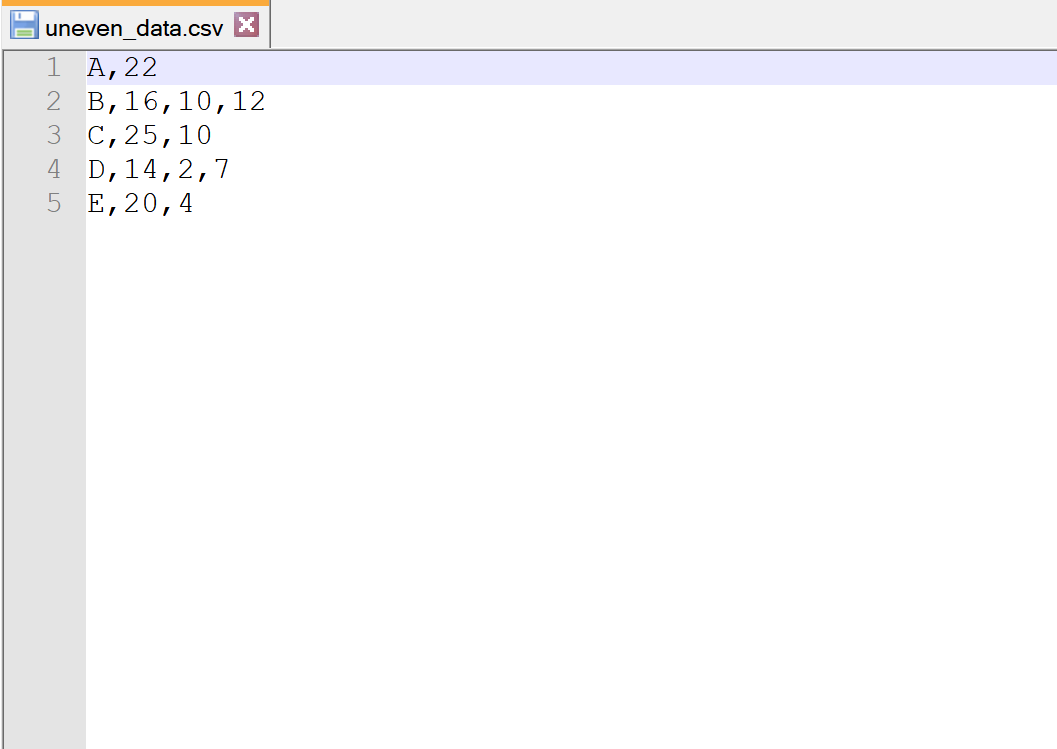
အတန်းတစ်ခုစီတွင် ကော်လံအရေအတွက် တူညီခြင်းမရှိကြောင်း သတိပြုပါ။
ကျွန်ုပ်တို့သည် ဤ CSV ဖိုင်ကို pandas DataFrame သို့တင်သွင်းရန် read_csv() လုပ်ဆောင်ချက်ကို အသုံးပြုပါက၊ ကျွန်ုပ်တို့သည် အမှားတစ်ခုကို လက်ခံရရှိလိမ့်မည်-
import pandas as pd #attempt to import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None ) ParserError: Error tokenizing data. C error: Expected 2 fields in line 2, saw 4
ပန်ဒါများသည် အကွက် 2 ကွက်ကို မျှော်လင့်ထားကြောင်း (၎င်းသည် ပထမအတန်းရှိ ကော်လံအရေအတွက်ဖြစ်သောကြောင့်) ကျွန်ုပ်တို့အား ပန်ဒါများက အကြောင်းကြားသည့် ပါဆာအမှား တစ်ခု လက်ခံရရှိသော်လည်း 4 ကို တွေ့ရပါသည်။
ဤအမှားသည် ပေးထားသောအတန်းတစ်ခုရှိ အများဆုံးကော်လံအရေအတွက်သည် 4 ကြောင်းကို ကျွန်ုပ်တို့အားပြောပြသည်။
ထို့ကြောင့်၊ ကျွန်ုပ်တို့သည် CSV ဖိုင်ကို တင်သွင်းနိုင်ပြီး အမည်များဆိုင်ရာ အငြင်းပွားမှုသို့ အပိုင်းအခြား (၄) တန်ဖိုးကို ပေးဆောင်နိုင်သည်-
import pandas as pd #import CSV file with differing number of columns per row df = pd. read_csv (' uneven_data.csv ', header= None , names=range( 4 ))) #view DataFrame print (df) 0 1 2 3 0 to 22 NaN NaN 1 B 16 10.0 12.0 2 C 25 10.0 NaN 3 D 14 2.0 7.0 4 E 20 4.0 NaN
ကျွန်ုပ်တို့သည် ကော်လံ 4 ခုကို မျှော်လင့်ရန်ပန်ဒါများကို ပြတ်သားစွာပြောထားသောကြောင့် ကျွန်ုပ်တို့သည် အမှားအယွင်းမရှိဘဲ CSV ဖိုင်ကို pandas DataFrame ထဲသို့ အောင်မြင်စွာတင်သွင်းနိုင်သည်ကို သတိပြုပါ။
ပုံမှန်အားဖြင့်၊ ပန်ဒါများသည် အတန်းတစ်ခုစီရှိ ပျောက်ဆုံးနေသောတန်ဖိုးအားလုံးကို NaN ဖြင့် ဖြည့်ပေးသည်။
ပျောက်ဆုံးနေသောတန်ဖိုးများကို သုညအဖြစ်မြင်လိုပါက၊ အောက်ပါအတိုင်း fillna() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်ပါသည်။
#fill NaN values with zeros df_new = df. fillna ( 0 ) #view new DataFrame print (df_new) 0 1 2 3 0 to 22 0.0 0.0 1 B 16 10.0 12.0 2 C 25 10.0 0.0 3 D 14 2.0 7.0 4 E 20 4.0 0.0
DataFrame ရှိ NaN တန်ဖိုးတစ်ခုစီကို သုညဖြင့် အစားထိုးလိုက်ပါပြီ။
မှတ်ချက် – pandas read_csv() လုပ်ဆောင်ချက်၏ စာရွက်စာတမ်းအပြည့်အစုံကို ဤနေရာတွင် ရှာတွေ့နိုင်ပါသည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ပါ သင်ခန်းစာများသည် Python တွင် အခြားသော အသုံးများသော အလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
ပန်ဒါများ- CSV ဖိုင်ကိုဖတ်သည့်အခါ လိုင်းများကို ကျော်သွားနည်း
Pandas- ရှိပြီးသား CSV ဖိုင်တစ်ခုသို့ ဒေတာထည့်နည်း
Pandas- CSV ဖိုင်ကိုတင်သွင်းသည့်အခါ အမျိုးအစားများကို သတ်မှတ်နည်း
Pandas- CSV ဖိုင်ကိုတင်သွင်းသည့်အခါ ကော်လံအမည်များကို သတ်မှတ်ပါ။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။