Stata တွင် fit test ၏ chi-square ကောင်းမွန်မှုကို မည်သို့လုပ်ဆောင်ရမည်နည်း။
Chi-square goodness-of-fit test ကို categorical variable သည် hypothetical distribution ကို လိုက်နာခြင်း ရှိ၊ မရှိ ဆုံးဖြတ်ရန် အသုံးပြုပါသည်။
ဤသင်ခန်းစာသည် Stata ရှိ chi-square goodness-of-fit test ကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြထားသည်။
ဥပမာ- Stata ရှိ Chi-square goodness-of-fit test
ဤစစ်ဆေးမှုကို မည်သို့လုပ်ဆောင်ရမည်ကို သရုပ်ဖော်ရန်၊ ကျွန်ုပ်တို့သည် 1988 ခုနှစ် အမေရိကန်ပြည်ထောင်စုရှိ အမျိုးသမီးအလုပ်စာရင်းဇယားဆိုင်ရာ အချက်အလက်များပါရှိသော nlsw88 ဟုခေါ်သော ဒေတာအတွဲကို အသုံးပြုပါမည်။
ဤဒေတာအစုံရှိ လူမျိုးများ၏ စစ်မှန်သော ဖြန့်ကျက်မှုသည် 70% အဖြူရောင်၊ 20% အနက်ရောင်၊ 10% အခြား၊ အခြား 10% ရှိမရှိ ဆုံးဖြတ်ရန် Chi-square good-of-fit စမ်းသပ်မှုပြုလုပ်ရန် အောက်ပါအဆင့်များကို လိုက်နာပါ။
အဆင့် 1- ဒေတာအကြမ်းကို တင်ပြီး ပြသပါ။
ပထမဦးစွာ၊ အောက်ပါ command ကိုရိုက်ခြင်းဖြင့် data ကို load လုပ်ပါမည်။
nlsw88 စနစ်
အောက်ပါ command ကိုရိုက်ခြင်းဖြင့် ကျွန်ုပ်တို့သည် ဒေတာအကြမ်းကို ကြည့်ရှုနိုင်သည်-
br
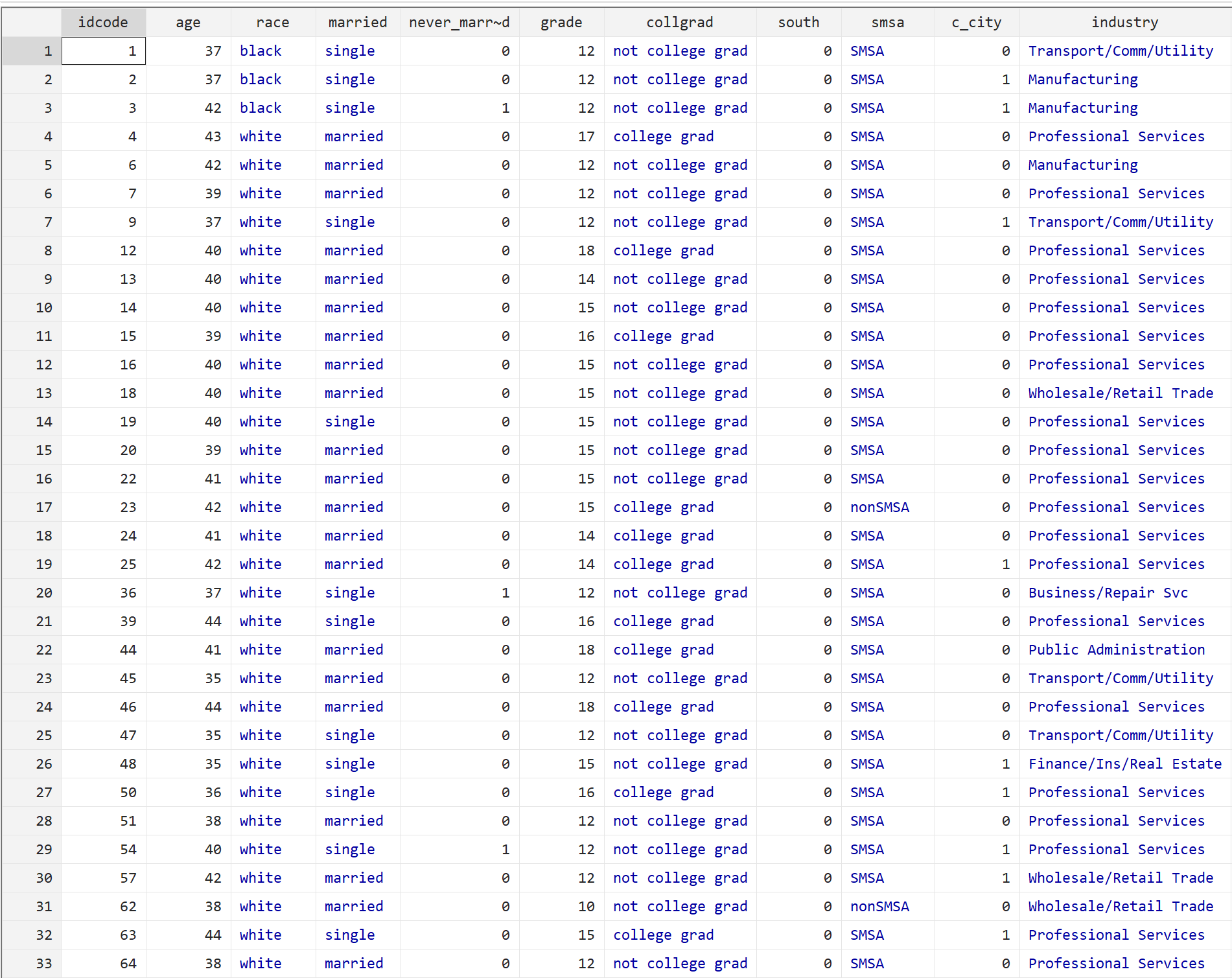
အတန်းတစ်ခုစီသည် ၎င်းတို့၏အသက်၊ လူမျိုး၊ အိမ်ထောင်ရေးအခြေအနေ၊ ပညာရေးအဆင့်နှင့် အခြားအချက်များအပါအဝင် လူတစ်ဦးချင်းစီ၏ အချက်အလက်များကို ပြသသည်။
အဆင့် 2- ချိန်ညှိမှုအထုပ်ကို တင်ပါ။
သင့်လျော်မှုစမ်းသပ်မှုတစ်ခုလုပ်ဆောင်ရန်၊ ကျွန်ုပ်တို့သည် csgof ပက်ကေ့ခ်ျကို ထည့်သွင်းရန် လိုအပ်ပါသည်။ အောက်ပါ command ကို ရိုက်ထည့်ခြင်းဖြင့် ၎င်းကို ကျွန်ုပ်တို့ လုပ်ဆောင်နိုင်သည်-
csgof ကိုရှာပါ။
ဝင်းဒိုးအသစ်တစ်ခုပေါ်လာလိမ့်မည်။ https://stats.idre.ucla.edu/stat/stata/ado/analysis မှ csgof ဟူသော လင့်ခ်ကို နှိပ်ပါ။
နောက်ထပ်ဝင်းဒိုးတစ်ခုပေါ်လာလိမ့်မည်။ ထည့်သွင်းရန် ဤနေရာကိုနှိပ်ပါ ဟူသော လင့်ခ်ကို နှိပ်ပါ။
ပက်ကေ့ဂျ်ကို ထည့်သွင်းခြင်းသည် စက္ကန့်အနည်းငယ်သာ ကြာသင့်သည်။
အဆင့် 3: အံဝင်ခွင်ကျစမ်းသပ်မှုပြုလုပ်ပါ။
ပက်ကေ့ဂျ်ကို ထည့်သွင်းပြီးသည်နှင့်၊ ကျွန်ုပ်တို့သည် စစ်မှန်သော ပြိုင်ပွဲခွဲခြမ်းစိတ်ဖြာမှု ဟုတ်မဟုတ် ဆုံးဖြတ်ရန် ဒေတာပေါ်တွင် ကောင်းမွန်မှု-အံဝင်ခွင်ကျ စမ်းသပ်မှုကို လုပ်ဆောင်နိုင်သည်- 70% အဖြူရောင်၊ 20% အနက်ရောင်၊ 10% အခြား။
စမ်းသပ်မှုကို လုပ်ဆောင်ရန် အောက်ပါ syntax ကို အသုံးပြုပါမည်။
csgof variable_of_interest၊ expperc(list_of_expected_percentages)
ဤသည်မှာ ကျွန်ုပ်တို့ကိစ္စတွင် ကျွန်ုပ်တို့အသုံးပြုမည့် တိကျသော syntax ဖြစ်သည်။
csgof၊ expperc(70၊ 20၊ 10) ကို run

ဤသည်မှာ ရလဒ်ကို မည်သို့အဓိပ္ပာယ်ဖွင့်ဆိုနိုင်သည်-
အနှစ်ချုပ်အကွက်- ဤအကွက်သည် ပြိုင်ပွဲတစ်ခုစီအတွက် မျှော်မှန်းထားသော ရာခိုင်နှုန်း၊ မျှော်မှန်းထားသော အကြိမ်ရေနှင့် အကဲဖြတ်သည့် အကြိမ်ရေကို ပြသပေးပါသည်။ ဥပမာအားဖြင့်:
- လူဖြူလူဖြူများ၏ မျှော်မှန်းရာခိုင်နှုန်းမှာ ၇၀ ရာခိုင်နှုန်းဖြစ်သည်။ ဒါက ကျွန်တော်တို့ သတ်မှတ်ထားတဲ့ ရာခိုင်နှုန်းပါ။
- လူဖြူတစ်ဦးချင်းစီ၏ မျှော်မှန်းထားသော အကြိမ်ရေမှာ 1,572.2 ဖြစ်သည်။ ဒေတာအတွဲတွင် တစ်ဦးချင်းစီ 2,246 ဦးရှိသောကြောင့် ၎င်းနံပါတ်၏ 70% သည် 1,572.2 ဖြစ်သည်။
- လူဖြူတစ်ဦးချင်းစီ၏ ကြိမ်နှုန်းမှာ 1,637 ဖြစ်သည်။ ၎င်းသည် ဒေတာအတွဲတွင် အမှန်တကယ် လူဖြူအရေအတွက်ဖြစ်သည်။
Chisq(2)- ဤသည်မှာ အံဝင်ခွင်ကျ ကောင်းသော စစ်ဆေးမှုအတွက် Chi-square စမ်းသပ်မှု ကိန်းဂဏန်း ဖြစ်ပါသည်။ 218.13 ဖြစ်သွားပါတယ်။
p- ဤသည်မှာ Chi-square စမ်းသပ်မှုကိန်းဂဏန်းနှင့်ဆက်စပ်နေသည့် p-တန်ဖိုးဖြစ်သည်။ ၎င်းသည် 0 ဖြစ်သည် ။ ၎င်းသည် 0.05 ထက်နည်းသောကြောင့်၊ စစ်မှန်သောလူမျိုးရေးဖြန့်ဝေမှုသည် 70% အဖြူရောင်၊ 20% အနက်ရောင်နှင့် အခြား 10% ဖြစ်သည်ဟူသော null hypothesis ကို ကျွန်ုပ်တို့ ငြင်းပယ်ရန်ပျက်ကွက်ပါသည်။ စစ်မှန်သော လူမျိုးရေး ဖြန့်ဝေမှုသည် ဤယူဆချက် ဖြန့်ဖြူးမှုနှင့် ကွဲပြားကြောင်း ကောက်ချက်ချရန် လုံလောက်သော အထောက်အထားများရှိသည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။