R in the iris dataset အတွက် လမ်းညွှန်ချက်အပြည့်အစုံ
iris dataset သည် မတူညီသောမျိုးစိတ် 3 ခုမှ ပန်း 50 အတွက် မတူညီသော attribute 4 ခု (စင်တီမီတာအတွင်း) တွင် တိုင်းတာမှုများပါရှိသော R တွင် ပေါင်းစပ်ထားသော dataset တစ်ခုဖြစ်သည်။
ဤသင်ခန်းစာတွင် iris ဒေတာအတွဲကို နမူနာအဖြစ် အသုံးပြု၍ R တွင် ဒေတာအတွဲတစ်ခုကို စူးစမ်းပြီး အကျဉ်းချုပ်ပုံကို ရှင်းပြထားသည်။
ဆက်စပ်- R ရှိ mtcars Dataset အတွက် ပြီးပြည့်စုံသော လမ်းညွှန်
Iris ဒေတာအတွဲကို တင်ပါ။
iris dataset သည် R တွင် built-in dataset တစ်ခုဖြစ်သောကြောင့်၊ အောက်ပါ command ကိုအသုံးပြု၍ ၎င်းကို load လုပ်နိုင်ပါသည်။
data(iris)
head() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ dataset ၏ ပထမခြောက်တန်းကို ကြည့်နိုင်သည်-
#view first six rows of iris dataset
head(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1 5.1 3.5 1.4 0.2 setosa
2 4.9 3.0 1.4 0.2 setosa
3 4.7 3.2 1.3 0.2 setosa
4 4.6 3.1 1.5 0.2 setosa
5 5.0 3.6 1.4 0.2 setosa
6 5.4 3.9 1.7 0.4 setosa
Iris ဒေတာအတွဲကို အကျဉ်းချုပ်ပါ။
dataset အတွင်းရှိ variable တစ်ခုစီကို လျင်မြန်စွာ အကျဉ်းချုပ်ရန် summary() function ကို အသုံးပြုနိုင်ပါသည်။
#summarize iris dataset
summary(iris)
Sepal.Length Sepal.Width Petal.Length Petal.Width
Min. :4,300 Min. :2,000 Min. :1,000 Min. :0.100
1st Qu.:5.100 1st Qu.:2.800 1st Qu.:1.600 1st Qu.:0.300
Median: 5,800 Median: 3,000 Median: 4,350 Median: 1,300
Mean:5.843 Mean:3.057 Mean:3.758 Mean:1.199
3rd Qu.:6,400 3rd Qu.:3,300 3rd Qu.:5,100 3rd Qu.:1,800
Max. :7,900 Max. :4,400 Max. :6,900 Max. :2,500
Species
setosa:50
versicolor:50
virginica :50
ကိန်းဂဏန်းကိန်းရှင်တစ်ခုစီအတွက် အောက်ပါအချက်အလက်များကို ကျွန်ုပ်တို့ကြည့်ရှုနိုင်သည်-
- အနည်းဆုံး : အနိမ့်ဆုံးတန်ဖိုး။
- 1st Qu : ပထမ quartile ၏တန်ဖိုး (25th ရာခိုင်နှုန်း)။
- Median : ပျမ်းမျှတန်ဖိုး။
- ပျမ်းမျှ : ပျမ်းမျှတန်ဖိုး။
- 3rd Qu : တတိယ quartile (75th ရာခိုင်နှုန်း) ၏တန်ဖိုး။
- Max : အများဆုံးတန်ဖိုး။
ဒေတာအတွဲ (အမျိုးအစားများ) ရှိ တစ်ခုတည်းသော အမျိုးအစားခွဲကွဲပြားသော ကိန်းရှင်အတွက်၊ တန်ဖိုးတစ်ခုစီ၏ ကြိမ်နှုန်းအရေအတွက်ကို ကျွန်ုပ်တို့ တွေ့ရသည်-
- setosa : ဤမျိုးစိတ်သည် အကြိမ် ၅၀ ရှိသည်။
- versicolor : ဤမျိုးစိတ်သည် အကြိမ် 50 ဖြစ်ပွားသည်။
- virginica : ဤမျိုးစိတ်သည် အကြိမ် ၅၀ ရှိသည်။
အတန်းများနှင့် ကော်လံအရေအတွက်အရ ဒေတာအတွဲ၏အတိုင်းအတာများကို ရယူရန် dim() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်သည်။
#display rows and columns
dim(iris)
[1] 150 5
ဒေတာအတွဲတွင် အတန်း 150 နှင့် ကော်လံ 5 ခုပါရှိသည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။
ဒေတာဘောင်၏ကော်လံအမည်များကိုပြသရန် names() လုပ်ဆောင်ချက်ကိုလည်း အသုံးပြုနိုင်ပါသည်။
#display column names
names(iris)
[1] "Sepal.Length" "Sepal.Width" "Petal.Length" "Petal.Width" "Species"
Iris ဒေတာအတွဲကို မြင်ယောင်ကြည့်ပါ။
ဒေတာအတွဲ၏ တန်ဖိုးများကို မြင်ယောင်နိုင်ရန် ကွက်ကွက်များ ဖန်တီးနိုင်သည်။
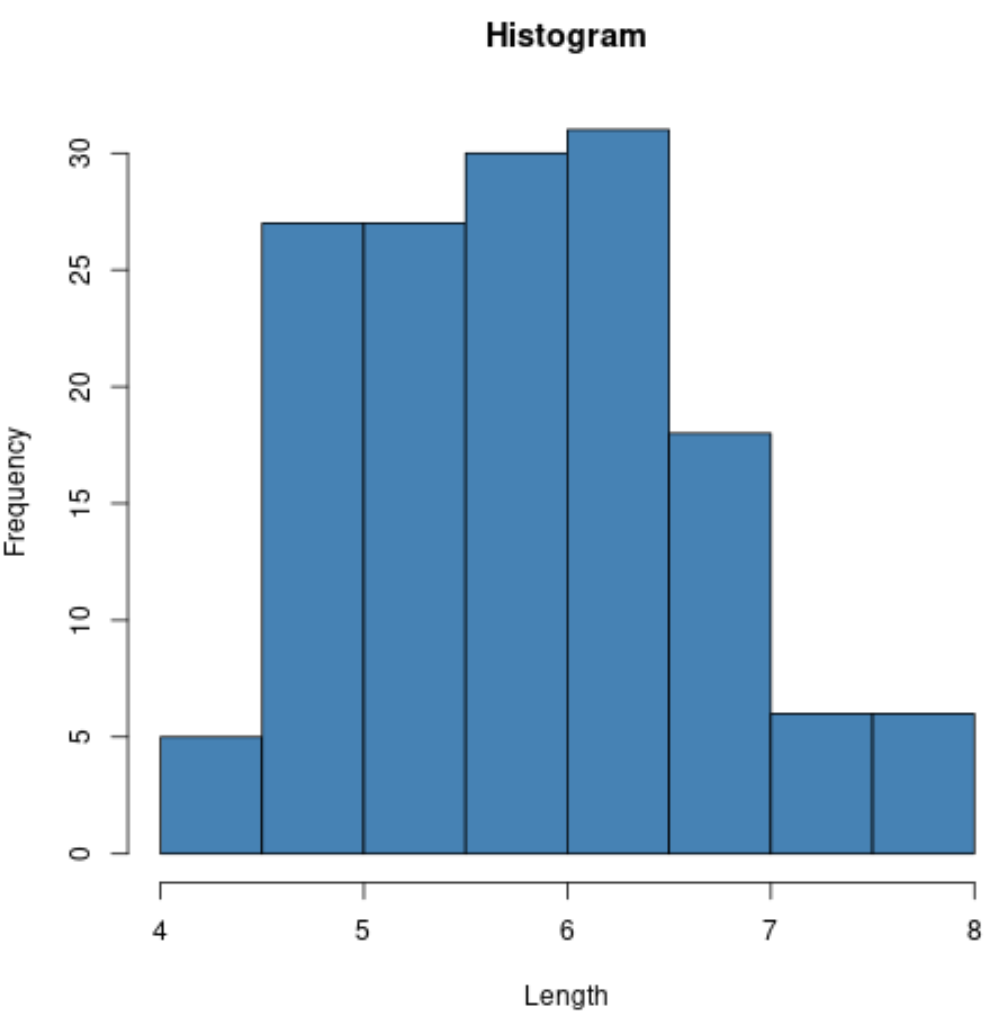
ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့သည် အချို့သော variable များ၏ တန်ဖိုးများကို histogram ဖန်တီးရန် hist() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်သည်။
#create histogram of values for sepal length
hist(iris$Sepal.Length,
col=' steelblue ',
main=' Histogram ',
xlab=' Length ',
ylab=' Frequency ')
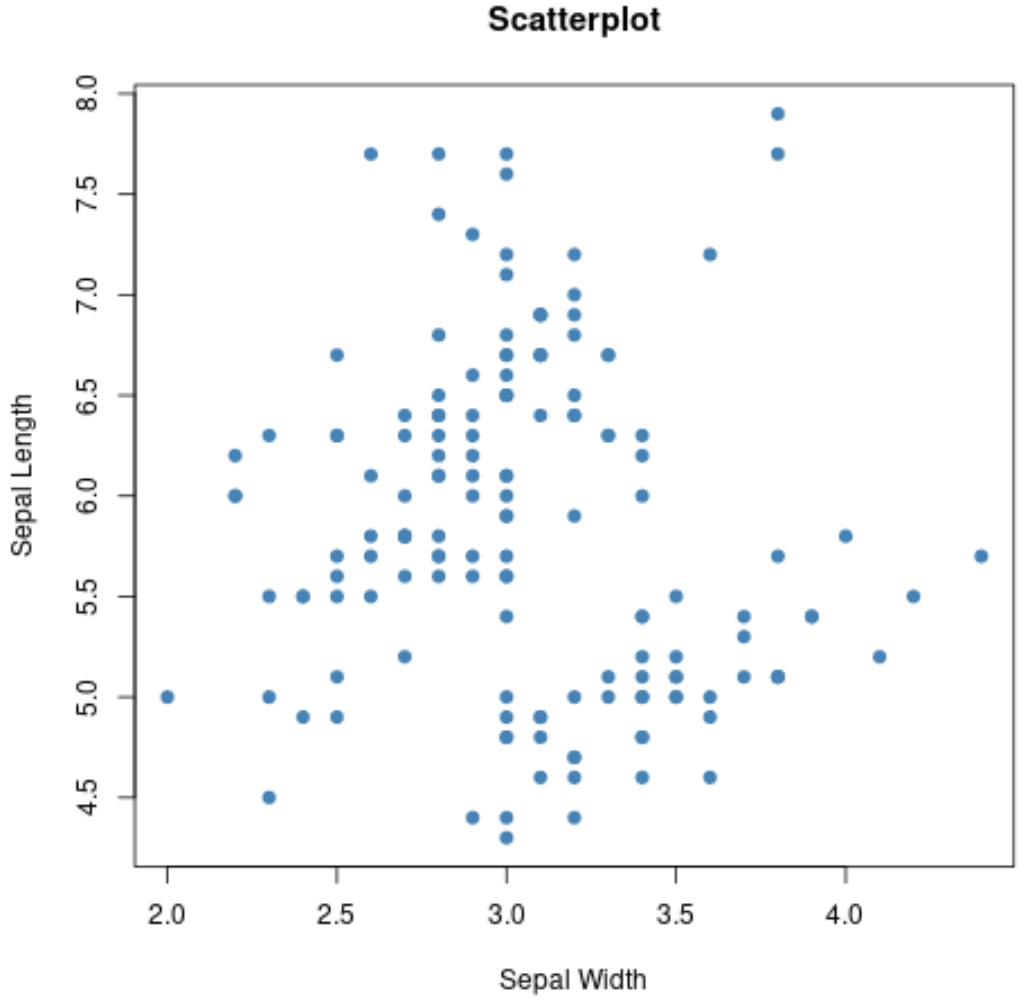
ကိန်းရှင်များ၏ အတွဲလိုက် ပေါင်းစပ်မှုတစ်ခုဖန်တီးရန် plot() လုပ်ဆောင်ချက်ကိုလည်း အသုံးပြုနိုင်သည်။
#create scatterplot of sepal width vs. sepal length
plot(iris$Sepal.Width, iris$Sepal.Length,
col=' steelblue ',
main=' Scatterplot ',
xlab=' Sepal Width ',
ylab=' Sepal Length ',
pch= 19 )
အုပ်စုတစ်ခုစီအတွက် boxplot တစ်ခုဖန်တီးရန် boxplot() လုပ်ဆောင်ချက်ကိုလည်း အသုံးပြုနိုင်သည်။
#create scatterplot of sepal width vs. sepal length
boxplot(Sepal.Length~Species,
data=iris,
main=' Sepal Length by Species ',
xlab=' Species ',
ylab=' Sepal Length ',
col=' steelblue ',
border=' black ')
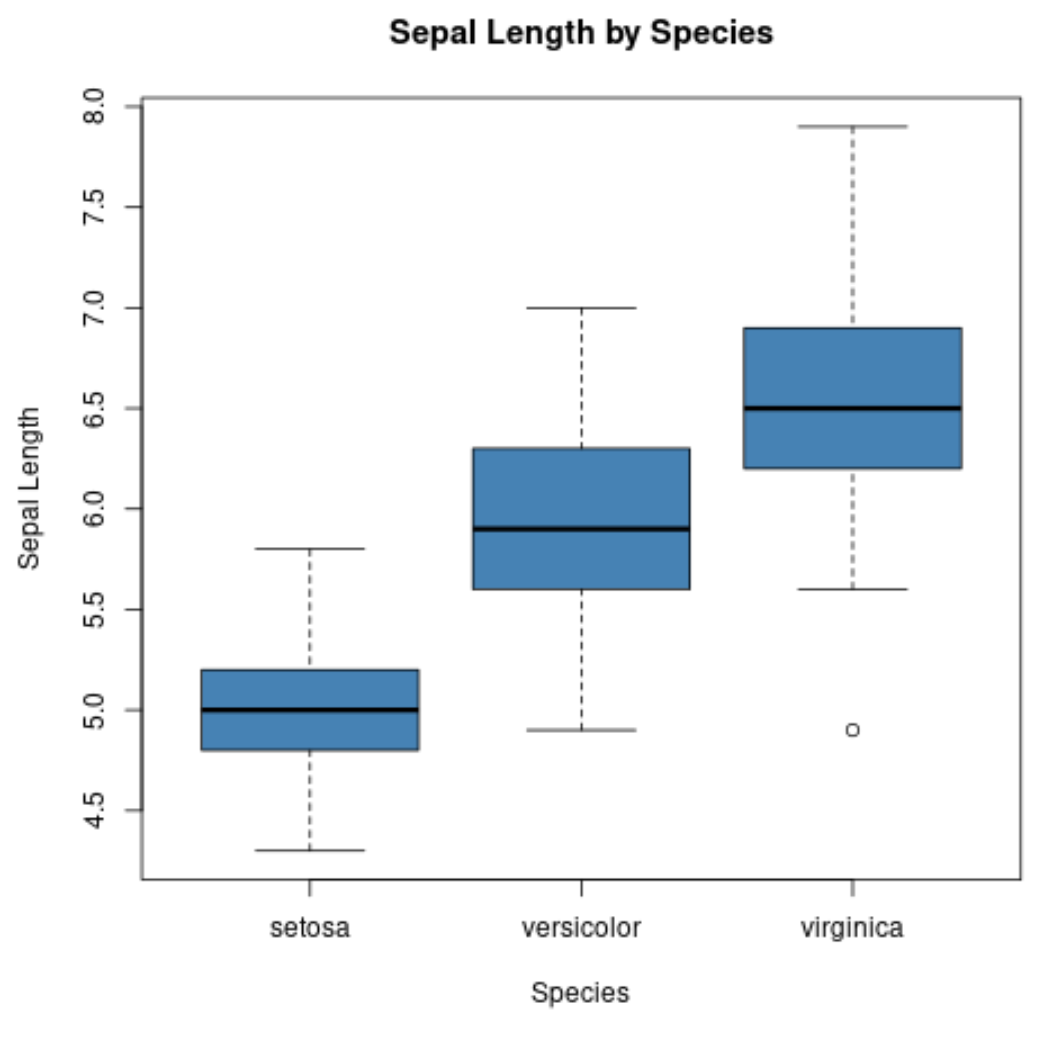
x-axis သည် မျိုးစိတ်သုံးခုကိုပြသပြီး y-axis သည် မျိုးစိတ်တစ်ခုစီအတွက် sepal အရှည်တန်ဖိုးများ ခွဲဝေမှုကိုပြသသည်။
ဤဇာတ်ကွက်အမျိုးအစားသည် အမြှေးပါးများ၏အရှည်သည် အပျိုစင်မျိုးစိတ်များအတွက် အကြီးကျယ်ဆုံးဖြစ်ပြီး setosa မျိုးစိတ်အတွက် အသေးငယ်ဆုံးဖြစ်တတ်သည်ကို လျင်မြန်စွာသိမြင်နိုင်စေပါသည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် R တွင် ဒေတာအတွဲများကို အကျဉ်းချုပ်နည်းကို အသေးစိတ်ရှင်းပြထားပါသည်။
R တွင် အကျဉ်းချုပ်ဇယားများ ဖန်တီးရန် အလွယ်ဆုံးနည်းလမ်း
R တွင် ဂဏန်းငါးလုံး၏ အကျဉ်းချုပ်ကို တွက်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။