Lasso regression နိဒါန်း
သာမာန် မျဉ်းကြောင်းမျိုးစုံဆုတ်ယုတ်မှု တွင်၊ ကျွန်ုပ်တို့သည် ပုံစံတစ်ခု၏မော်ဒယ်နှင့်ကိုက်ညီရန် p ကြိုတင်ခန့်မှန်းကိန်းရှင် ကိန်းရှင်များနှင့် တုံ့ပြန်မှုကိန်းရှင် တစ်ခုကို အသုံးပြုသည်-
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
ရွှေ-
- Y : တုံ့ပြန်မှု ကိန်းရှင်
- X j : j th ကြိုတင်ခန့်မှန်းနိုင်သောကိန်းရှင်
- β j : X j တွင် တစ်ယူနစ်တိုးလာမှု၏ Y ပေါ်ရှိ ပျမ်းမျှအကျိုးသက်ရောက်မှုသည် အခြားကြိုတင်ခန့်မှန်းသူအားလုံးကို ပုံသေသတ်မှတ်ထားသည်
- ε : အမှားအယွင်း ကိန်း
β 0 , β 1 , B 2 , …, β p ၏ တန်ဖိုးများကို အကြွင်းအကျန်များ (RSS) ၏ နှစ်ထပ်ကိန်းများကို အနည်းဆုံးဖြစ်စေသည့် အနည်းဆုံး စတုရန်းပုံနည်းလမ်းကို အသုံးပြု၍ ရွေးချယ်ထားသည်။
RSS = Σ(y i – ŷ i ) ၂
ရွှေ-
- ∑ : ပေါင်းလဒ် ဟု အဓိပ္ပာယ်ရသော ဂရိသင်္ကေတ
- y i : အိုင်တီ လေ့လာခြင်းအတွက် အမှန်တကယ် တုံ့ပြန်မှုတန်ဖိုး
- ŷ i : Multiple linear regression model ကို အခြေခံ၍ ခန့်မှန်းထားသော တုံ့ပြန်မှုတန်ဖိုး
သို့ရာတွင်၊ ကြိုတင်ခန့်မှန်းနိုင်သောကိန်းရှင်များသည် အလွန်ဆက်စပ်နေသောအခါတွင်၊ ကော်လိုင်းပေါင်းစုံသည် ပြဿနာဖြစ်လာနိုင်သည်။ ၎င်းသည် မော်ဒယ်ဖော်ကိန်း ခန့်မှန်းချက်များကို ယုံကြည်စိတ်ချမှုမရှိစေဘဲ ကွဲပြားမှုမြင့်မားမှုကို ပြသနိုင်သည်။ ဆိုလိုသည်မှာ၊ မော်ဒယ်ကို ယခင်က တစ်ခါမှမမြင်ဖူးသော ဒေတာအစုအသစ်တစ်ခုသို့ အသုံးချသောအခါ၊ ၎င်းသည် ညံ့ဖျင်းစွာ လုပ်ဆောင်နိုင်ဖွယ်ရှိသည်။
ဤပြဿနာကို ဖြေရှင်းရန် နည်းလမ်းတစ်ခုမှာ အောက်ပါတို့ကို လျှော့ချရန် အစား lasso regression ဟုခေါ်သော နည်းလမ်းကို အသုံးပြုခြင်းဖြစ်သည်၊
RSS + λΣ|β j |
j သည် 1 မှ p နှင့် λ ≥ 0 ရှိရာ။
ညီမျှခြင်းတွင် ဤဒုတိယအခေါ်အဝေါ်ကို ရုပ်သိမ်းပြစ်ဒဏ် ဟု ခေါ်သည်။
λ = 0 ဖြစ်သောအခါ၊ ဤပြစ်ဒဏ်အသုံးအနှုန်းသည် သက်ရောက်မှုမရှိပါ၊ lasso ဆုတ်ယုတ်မှုသည် တူညီသောကိန်းဂဏန်းခန့်မှန်းချက်ကို အနည်းဆုံးစတုရန်းအဖြစ်ထုတ်ပေးသည်။
သို့သော်လည်း λ အနန္တသို့ ချဉ်းကပ်လာသည်နှင့်အမျှ၊ ဖယ်ရှားခြင်းပြစ်ဒဏ်သည် ပိုမိုသြဇာကြီးမားလာပြီး မော်ဒယ်သို့ တင်သွင်း၍မရသော ကြိုတင်ခန့်မှန်းနိုင်သောကိန်းရှင်များကို သုညအထိ လျှော့ချလိုက်ပြီး အချို့ကို မော်ဒယ်မှပင် ဖယ်ရှားလိုက်ပါသည်။
Lasso regression ကို ဘာကြောင့် သုံးတာလဲ။
အနည်းဆုံး စတုရန်းများ ဆုတ်ယုတ်ခြင်းထက် lasso ဆုတ်ယုတ်ခြင်း၏ အားသာချက်မှာ ဘက်လိုက်-ကွဲလွဲမှု ဖလှယ်မှု ဖြစ်သည်။
Mean Square Error (MSE) သည် ပေးထားသော မော်ဒယ်တစ်ခု၏ တိကျမှုကို တိုင်းတာရန် အသုံးပြုနိုင်သည့် မက်ထရစ်တစ်ခုဖြစ်ပြီး ၎င်းကို အောက်ပါအတိုင်း တွက်ချက်ထားသည်-
MSE = Var( f̂( x 0 )) + [Bias( f̂( x 0 ))] 2 + Var(ε)
MSE = Variance + Bias 2 + Irreducible အမှား
lasso regression ၏ အခြေခံအယူအဆမှာ ကွဲလွဲမှုကို သိသာထင်ရှားစွာ လျှော့ချနိုင်ပြီး MSE တစ်ခုလုံးကို နိမ့်ကျစေရန်အတွက် သေးငယ်သောဘက်လိုက်မှုကို မိတ်ဆက်ရန်ဖြစ်သည်။
ယင်းကို သရုပ်ဖော်ရန် အောက်ပါဂရပ်ကို သုံးသပ်ပါ။

λ တိုးလာသည်နှင့်အမျှ ဘက်လိုက်မှု အနည်းငယ်တိုးလာသဖြင့် ကွဲလွဲမှု သိသိသာသာ လျော့ကျသွားသည်ကို သတိပြုပါ။ သို့ရာတွင်၊ အချို့သောအချက်ကိုကျော်လွန်ပါက၊ ကွဲလွဲမှုသည် လျင်မြန်စွာလျော့နည်းသွားပြီး ကိန်းဂဏန်းများ ကျဆင်းခြင်းသည် ၎င်းတို့ကို သိသိသာသာလျှော့တွက်ခြင်းဆီသို့ ဦးတည်စေပြီး ဘက်လိုက်မှုတွင် သိသိသာသာတိုးလာစေသည်။
ဘက်လိုက်မှု နှင့် ကွဲပြားမှုကြား အကောင်းမွန်ဆုံးသော အပေးအယူကို ထုတ်ပေးသည့် λ တန်ဖိုးကို ရွေးချယ်သောအခါ စမ်းသပ်မှု၏ MSE သည် အနိမ့်ဆုံးဖြစ်ကြောင်း ဂရပ်မှ မြင်တွေ့နိုင်သည်။
λ = 0 ဖြစ်သောအခါ၊ lasso ဆုတ်ယုတ်မှုတွင် ပြစ်ဒဏ်အသုံးအနှုန်းသည် အကျိုးသက်ရောက်မှုမရှိသောကြောင့် တူညီသောကိန်းဂဏန်းခန့်မှန်းချက်ကို အနည်းဆုံးစတုရန်းအဖြစ်ထုတ်ပေးသည်။ သို့သော်၊ အချို့သောအချက်တစ်ခုသို့ λ ကိုတိုးမြှင့်ခြင်းဖြင့်၊ ကျွန်ုပ်တို့သည် စမ်းသပ်မှု၏ MSE တစ်ခုလုံးကို လျှော့ချနိုင်သည်။
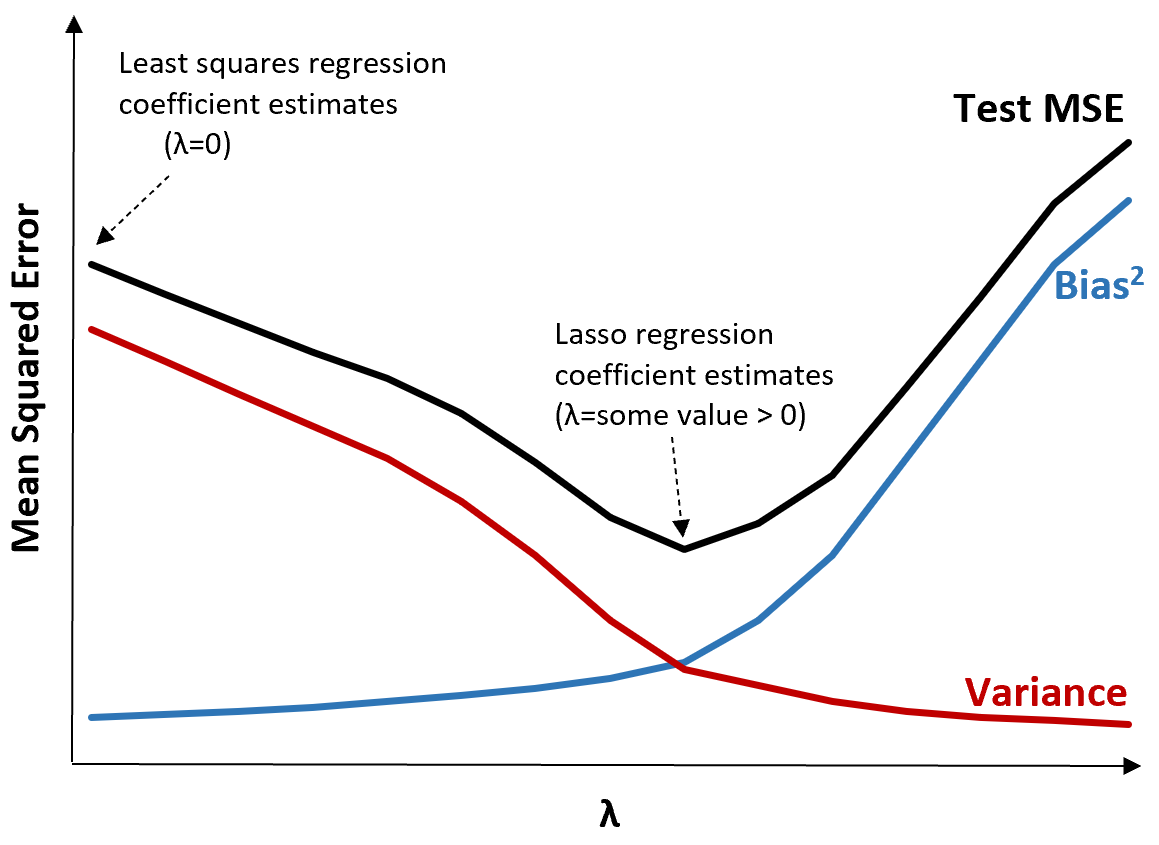
ဆိုလိုသည်မှာ lasso regression ဖြင့် အံဝင်ခွင်ကျဖြစ်သော model သည် အနိမ့်ဆုံး squares regression ဖြင့် ကိုက်ညီသော model ထက် သေးငယ်သော test error များကို ထုတ်ပေးလိမ့်မည်ဖြစ်သည်။
Lasso ဆုတ်ယုတ်မှု vs Ridge ဆုတ်ယုတ်မှု
Lasso regression နှင့် Ridge regression တို့ကို ပုံမှန်ပြုလုပ်ခြင်းနည်းလမ်းများ အဖြစ် လူသိများပြီး ၎င်းတို့နှစ်ဦးစလုံးသည် ကျန်ရှိသော စတုရန်းများ (RSS) နှင့် အချို့သော ပြစ်ဒဏ်သက်တမ်းကို လျှော့ချရန် ကြိုးပမ်းသောကြောင့် ဖြစ်သည်။
တစ်နည်းဆိုရသော်၊ ၎င်းတို့သည် မော်ဒယ်ကိန်းဂဏန်းများ၏ ခန့်မှန်းချက်များကို ကန့်သတ်ခြင်း သို့မဟုတ် ပုံမှန်ပြုလုပ်ခြင်း ဖြစ်သည် ။
သို့ရာတွင်၊ ၎င်းတို့အသုံးပြုသော ပြစ်ဒဏ်သတ်မှတ်ချက်များမှာ အနည်းငယ်ကွဲပြားသည်-
- Lasso ဆုတ်ယုတ်မှုသည် RSS + λΣ|β j | ကို လျှော့ချရန် ကြိုးပမ်းသည်။
- Ridge regression သည် RSS + λΣβ j 2 ကို လျှော့ချရန် ကြိုးပမ်းသည်။
ကျွန်ုပ်တို့သည် ခေါင်ဆုတ်ယုတ်မှုကို အသုံးပြုသောအခါ၊ ခန့်မှန်းသူတိုင်း၏ ကိန်းဂဏန်းများကို သုညသို့ လျှော့ချသော်လည်း ၎င်းတို့အနက်မှ သုညသို့ လုံးလုံးလျားလျား မသွားနိုင်ပါ။
အပြန်အလှန်အားဖြင့်၊ ကျွန်ုပ်တို့သည် lasso regression ကိုအသုံးပြုသောအခါ၊ အချို့သော coefficients များသည် λ လုံလောက်စွာကြီးလာသောအခါ လုံးဝသုည ဖြစ်သွားနိုင်သည်။
နည်းပညာပိုင်းဆိုင်ရာအရ၊ lasso regression သည် ကြိုတင်ခန့်မှန်းကိန်းရှင်များ အစုခွဲတစ်ခုသာပါဝင်သည့် မော်ဒယ်များဖြစ်သည့် “ sparse” မော်ဒယ်များကို ထုတ်လုပ်နိုင်စွမ်းရှိသည်။
ဤသည်မှာ မေးစရာဖြစ်လာသည်- တောင်ကြောဆုတ်ယုတ်မှု သို့မဟုတ် လက်စတိုဆုတ်ယုတ်မှု ပိုကောင်းသလား။
အဖြေ- အဲဒါမူတည်တယ်။
ခန့်မှန်းသူကိန်းရှင်အနည်းငယ်သာ သိသာထင်ရှားသည့်ကိစ္စများတွင်၊ lasso ဆုတ်ယုတ်မှုမှာ အရေးမပါသောကိန်းရှင်များကို သုညအထိ လုံးလုံးလျှော့ချနိုင်ပြီး ၎င်းတို့ကို မော်ဒယ်မှဖယ်ရှားနိုင်သောကြောင့် ပိုကောင်းပါသည်။
သို့သော်၊ မော်ဒယ်တွင် ခန့်မှန်းသူကိန်းရှင်များစွာသည် သိသာထင်ရှားပြီး ၎င်းတို့၏ coefficients သည် ခန့်မှန်းခြေအားဖြင့် တူညီသောအခါ၊ ခေါင်ဆုတ်ဆုတ်ခြင်းသည် မော်ဒယ်တွင် ကြိုတင်ခန့်မှန်းသူအားလုံးကို ထိန်းသိမ်းထားသောကြောင့် ပိုကောင်းပါသည်။
ကြိုတင်ခန့်မှန်းမှုများပြုလုပ်ရာတွင် မည်သည့်မော်ဒယ်က အထိရောက်ဆုံးဖြစ်ကြောင်း ဆုံးဖြတ်ရန်၊ ကျွန်ုပ်တို့သည် k-fold cross-validation ကို လုပ်ဆောင်ပါသည်။ မည်သည့်မော်ဒယ်မဆို အနိမ့်ဆုံး mean square error (MSE) ကို ထုတ်ပေးခြင်းသည် အသုံးပြုရန် အကောင်းဆုံး မော်ဒယ်ဖြစ်သည်။
လက်တွေ့တွင် lasso regression လုပ်ဆောင်ရန် အဆင့်များ
lasso regression လုပ်ဆောင်ရန် အောက်ပါအဆင့်များကို အသုံးပြုနိုင်ပါသည်။
အဆင့် 1- ခန့်မှန်းသူကိန်းရှင်များအတွက် ဆက်စပ်မက်ထရစ်နှင့် VIF တန်ဖိုးများကို တွက်ချက်ပါ။
ပထမဦးစွာ၊ ကျွန်ုပ်တို့သည် ဆက်စပ်မက်ထရစ် တစ်ခုကို ထုတ်လုပ်ရန်နှင့် ခန့်မှန်းသူကိန်းရှင်တစ်ခုစီအတွက် VIF (variance inflation factor) တန်ဖိုးများကို တွက်ချက်ရန် လိုအပ်သည်။
ကြိုတင်ခန့်မှန်းကိန်းရှင်များနှင့် မြင့်မားသော VIF တန်ဖိုးများအကြား ခိုင်မာသောဆက်စပ်မှုကို ကျွန်ုပ်တို့တွေ့ရှိပါက (အချို့စာများတွင် “ မြင့်မားသော” VIF တန်ဖိုးကို 5 အဖြစ်သတ်မှတ်ထားသော်လည်း အချို့က 10 ကိုအသုံးပြုသည်)၊ ထို့နောက် lasso ဆုတ်ယုတ်မှုသည် သင့်လျော်ပါသည်။
သို့သော်၊ ဒေတာတွင် multicollinearity မရှိပါက၊ ပထမနေရာတွင် lasso regression လုပ်ဆောင်ရန် မလိုအပ်ပါ။ ယင်းအစား၊ ကျွန်ုပ်တို့သည် သာမန်အနည်းဆုံး လေးထောင့်ဆုတ်ယုတ်မှုကို လုပ်ဆောင်နိုင်သည်။
အဆင့် 2- lasso ဆုတ်ယုတ်မှုပုံစံကို ကိုက်ညီပြီး λ အတွက် တန်ဖိုးတစ်ခုကို ရွေးပါ။
lasso regression သည် သင့်လျော်ကြောင်း ကျွန်ုပ်တို့ ဆုံးဖြတ်ပြီးသည်နှင့်၊ ကျွန်ုပ်တို့သည် λ အတွက် အကောင်းဆုံးတန်ဖိုးကို အသုံးပြု၍ (လူကြိုက်များသော ပရိုဂရမ်းမင်းဘာသာစကားများကဲ့သို့ R သို့မဟုတ် Python ကဲ့သို့) မော်ဒယ်ကို အံကိုက်လုပ်နိုင်ပါသည်။
λ အတွက် အကောင်းဆုံးတန်ဖိုးကို ဆုံးဖြတ်ရန်၊ ကျွန်ုပ်တို့သည် λ အတွက် မတူညီသောတန်ဖိုးများကို အသုံးပြုကာ မော်ဒယ်များစွာကို ဖြည့်သွင်းနိုင်ပြီး အနိမ့်ဆုံး MSE စမ်းသပ်မှုထုတ်ပေးသည့် တန်ဖိုးအဖြစ် λ ကို ရွေးချယ်နိုင်သည်။
အဆင့် 3- lasso ဆုတ်ယုတ်မှုအား ခေါင်ဆုတ်ဆုတ်ယုတ်မှုနှင့် သာမန်အနိမ့်ဆုံးစတုရန်းဆုတ်ယုတ်မှုကို နှိုင်းယှဉ်ပါ။
နောက်ဆုံးတွင်၊ ကျွန်ုပ်တို့သည် ကျွန်ုပ်တို့၏ lasso ဆုတ်ယုတ်မှုပုံစံကို k-fold cross-validation ကိုအသုံးပြု၍ မည်သည့်မော်ဒယ်က အနိမ့်ဆုံး MSE ကိုထုတ်ပေးသည်ကို ဆုံးဖြတ်ရန် ခေါင်ဆုတ်ယုတ်မာမှုပုံစံနှင့် အနည်းဆုံးစတုရန်းဆုတ်ယုတ်မှုပုံစံနှင့် နှိုင်းယှဉ်နိုင်သည်။
ကြိုတင်ခန့်မှန်းကိန်းရှင်များနှင့် တုံ့ပြန်မှုကိန်းရှင်တို့ကြား ဆက်နွယ်မှုအပေါ်မူတည်၍ ဤပုံစံသုံးမျိုးထဲမှ တစ်ခုသည် မတူညီသောအခြေအနေများတွင် အခြားသူများထက် စွမ်းဆောင်ရည်ပိုကောင်းလာမည်မှာ လုံးဝဖြစ်နိုင်သည်။
R & Python တွင် Lasso Regression
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် R နှင့် Python တွင် lasso regression လုပ်ဆောင်ပုံကို ရှင်းပြသည် ။
R in Lasso Regression (တစ်ဆင့်ပြီးတစ်ဆင့်)
Python ရှိ Lasso ဆုတ်ယုတ်မှု (အဆင့်ဆင့်)
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။