ဤသင်ခန်းစာတွင်အသုံးပြုထားသော Python ကုဒ်အပြည့်အစုံကို ဤနေရာတွင် တွေ့နိုင်ပါသည်။
Python တွင် logistic regression လုပ်နည်း (တစ်ဆင့်ပြီးတစ်ဆင့်)
Logistic regression သည် response variable binary ဖြစ်သောအခါ regression model နှင့် ကိုက်ညီရန် ကျွန်ုပ်တို့သုံးနိုင်သော method တစ်ခုဖြစ်သည်။
Logistic regression သည် အောက်ပါပုံစံ၏ ညီမျှခြင်းတစ်ခုကို ရှာဖွေရန် အများဆုံးဖြစ်နိုင်ခြေ ခန့်မှန်းချက် ဟု လူသိများသော နည်းလမ်းကို အသုံးပြုသည်-
log[p(X) / ( 1 -p(X))] = β 0 + β 1 X 1 + β 2 X 2 + … + β p
ရွှေ-
- X j : j th ကြိုတင်ခန့်မှန်းနိုင်သောကိန်းရှင်
- β j : j th ကြိုတင်ခန့်မှန်းကိန်းရှင်အတွက် ကိန်းကိန်းကို ခန့်မှန်းခြင်း။
ညီမျှခြင်း၏ ညာဘက်ရှိ ဖော်မြူလာသည် တုံ့ပြန်မှုကိန်းရှင်သည် တန်ဖိုး 1 ကို ယူသည့် မှတ်တမ်းအပေါက်များကို ခန့်မှန်းပေးသည်။
ထို့ကြောင့်၊ ကျွန်ုပ်တို့သည် logistic regression model ကို အံဝင်ခွင်ကျသောအခါ၊ ပေးထားသော observation သည် value 1 ကိုယူသည့်ဖြစ်နိုင်ခြေကို တွက်ချက်ရန် အောက်ပါညီမျှခြင်းကို အသုံးပြုနိုင်သည်။
p(X) = e β 0 + β 1 X 1 + β 2 X 2 + … + β p
ထို့နောက် ရှုမြင်ချက်ကို 1 သို့မဟုတ် 0 အဖြစ် အမျိုးအစားခွဲခြားရန် အချို့သောဖြစ်နိုင်ခြေအဆင့်သတ်မှတ်ချက်ကို အသုံးပြုသည်။
ဥပမာအားဖြင့်၊ 0.5 ထက်ကြီးသော ဖြစ်နိုင်ခြေရှိသော လေ့လာတွေ့ရှိချက်များကို “ 1” အဖြစ် ခွဲခြားပြီး အခြားလေ့လာတွေ့ရှိချက်အားလုံးကို “ 0” အဖြစ် ခွဲခြားသတ်မှတ်မည်ဟု ကျွန်ုပ်တို့ပြောနိုင်သည်။
ဤသင်ခန်းစာသည် R တွင် ထောက်ပံ့ပို့ဆောင်ရေးဆုတ်ယုတ်မှုလုပ်ဆောင်ပုံအဆင့်ဆင့်ကို ဥပမာပေးထားသည်။
အဆင့် 1- လိုအပ်သော ပက်ကေ့ခ်ျများကို တင်သွင်းပါ။
ပထမဦးစွာ၊ Python တွင် ထောက်ပံ့ပို့ဆောင်ရေးဆုတ်ယုတ်မှုကို လုပ်ဆောင်ရန် လိုအပ်သော ပက်ကေ့ဂျ်များကို တင်သွင်းပါမည်။
import pandas as pd import numpy as np from sklearn. model_selection import train_test_split from sklearn. linear_model import LogisticRegression from sklearn import metrics import matplotlib. pyplot as plt
အဆင့် 2: ဒေတာကို တင်ပါ။
ဤဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် စာအုပ်နိဒါန်းမှ စာရင်းအင်းသင်ယူခြင်းမှ မူရင်း ဒေတာအတွဲကို အသုံးပြုပါမည်။ ဒေတာအတွဲ၏ အကျဉ်းချုပ်ကို တင်ရန်နှင့် ပြသရန် အောက်ပါကုဒ်ကို ကျွန်ုပ်တို့ အသုံးပြုနိုင်ပါသည်။
#import dataset from CSV file on Github url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/default.csv" data = pd. read_csv (url) #view first six rows of dataset data[0:6] default student balance income 0 0 0 729.526495 44361.625074 1 0 1 817.180407 12106.134700 2 0 0 1073.549164 31767.138947 3 0 0 529.250605 35704.493935 4 0 0 785.655883 38463.495879 5 0 1 919.588530 7491.558572 #find total observations in dataset len( data.index ) 10000
ဤဒေတာအတွဲတွင် လူ 10,000 ဦးအတွက် အောက်ပါအချက်အလက်များပါရှိသည်။
- ပုံသေ- တစ်ဦးတစ်ယောက်သည် ပုံသေသတ်မှတ်ထားခြင်း ရှိ၊ မရှိကို ဖော်ပြသည်။
- ကျောင်းသား- တစ်ဦးတစ်ယောက်သည် ကျောင်းသားဟုတ်မဟုတ် ညွှန်ပြသည်။
- လက်ကျန်- တစ်ဦးချင်းစီမှ ပျမ်းမျှလက်ကျန်ငွေ။
- ဝင်ငွေ- တစ်ဦးချင်း၏ ၀င်ငွေ။
ကျွန်ုပ်တို့သည် ကျောင်းသားအခြေအနေ၊ ဘဏ်လက်ကျန်နှင့် ဝင်ငွေတို့ကို အသုံးပြုပြီး ထောက်ပံ့ပို့ဆောင်ပေးသူတစ်ဦးသည် ပုံသေဖြစ်နိုင်ခြေကို ခန့်မှန်းပေးသည့် ထောက်ပံ့ပို့ဆောင်ရေးဆုတ်ယုတ်မှုပုံစံကို တည်ဆောက်မည်ဖြစ်သည်။
အဆင့် 3- လေ့ကျင့်ရေးနှင့် စမ်းသပ်နမူနာများ ဖန်တီးပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် dataset အား မော်ဒယ်အား လေ့ကျင့် ရန် လေ့ကျင့်ရေး အစုံနှင့် မော်ဒယ်ကို စမ်းသပ်ရန်အတွက် စမ်းသပ်မှုတစ်ခုအဖြစ် ခွဲသွားပါမည်။
#define the predictor variables and the response variable X = data[[' student ',' balance ',' income ']] y = data[' default '] #split the dataset into training (70%) and testing (30%) sets X_train,X_test,y_train,y_test = train_test_split (X,y,test_size=0.3,random_state=0)
အဆင့် 4- ထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံကို အံကိုက်လုပ်ပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် ဒေတာအစုံနှင့် ထောက်ပံ့ပို့ဆောင်ရေး ဆုတ်ယုတ်မှုပုံစံကို ကိုက်ညီစေရန် LogisticRegression() လုပ်ဆောင်ချက်ကို အသုံးပြုပါမည်။
#instantiate the model log_regression = LogisticRegression() #fit the model using the training data log_regression. fit (X_train,y_train) #use model to make predictions on test data y_pred = log_regression. predict (X_test)
အဆင့် 5- မော်ဒယ်ရောဂါရှာဖွေရေး
ကျွန်ုပ်တို့သည် ဆုတ်ယုတ်မှုပုံစံကို တပ်ဆင်ပြီးသည်နှင့် ကျွန်ုပ်တို့သည် စမ်းသပ်ဒေတာအတွဲတွင် ကျွန်ုပ်တို့၏မော်ဒယ်၏စွမ်းဆောင်ရည်ကို ပိုင်းခြားစိတ်ဖြာနိုင်ပါသည်။
ပထမဦးစွာ၊ မော်ဒယ်အတွက် ရှုပ်ထွေးမှု matrix ကို ဖန်တီးပါမည် ။
cnf_matrix = metrics. confusion_matrix (y_test, y_pred)
cnf_matrix
array([[2886, 1],
[113,0]])
ရှုပ်ထွေးသော matrix မှ ကျွန်ုပ်တို့ မြင်နိုင်သည်-
- #မှန်ကန်သော အပြုသဘောဆောင်သော ခန့်မှန်းချက်များ- 2886
- #မှန်ကန်သော အနုတ်လက္ခဏာဟောကိန်းများ- 0
- #မှားယွင်းသော အပြုသဘောဆောင်သော ခန့်မှန်းချက်များ- ၁၁၃
- #မှားယွင်းသော အနုတ်လက္ခဏာဟောကိန်းများ ၁
မော်ဒယ်မှ ပြုလုပ်သော အမှားပြင်ဆင်မှု ရာခိုင်နှုန်းများကို ပြောပြသည့် တိကျမှု မော်ဒယ်ကိုလည်း ကျွန်ုပ်တို့ ရရှိနိုင်ပါသည်။
print(" Accuracy: ", metrics.accuracy_score (y_test, y_pred))l
Accuracy: 0.962
၎င်းသည် မော်ဒယ်သည် အချိန်၏ 96.2% ကို ပုံသေဖြစ်စေမည်၊
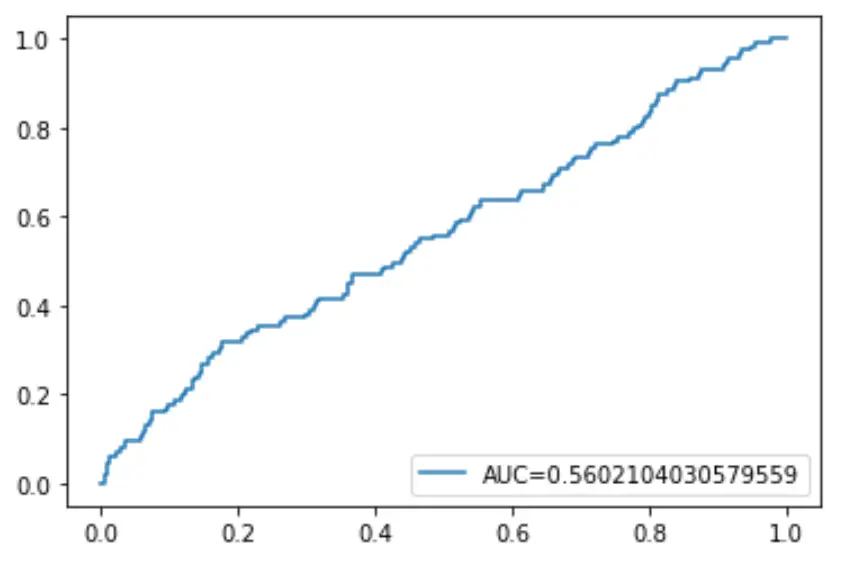
နောက်ဆုံးတွင်၊ ခန့်မှန်းမှုဖြစ်နိုင်ခြေအဆင့်ကို 1 မှ 0 မှ 0 မှ လျှော့ချသည့်အခါ မော်ဒယ်က ခန့်မှန်းထားသော စစ်မှန်သော positive ရာခိုင်နှုန်းကို ပြသသည့် Receiver Operating Characteristic (ROC) မျဉ်းကွေးကို ကျွန်ုပ်တို့ ကြံစည်နိုင်သည်။
AUC (မျဉ်းကွေးအောက်တွင် ဧရိယာ) မြင့်မားလေ၊ ကျွန်ုပ်တို့၏ မော်ဒယ်သည် ရလဒ်များကို ပိုမိုတိကျစွာ ခန့်မှန်းနိုင်လေဖြစ်သည်။
#define metrics
y_pred_proba = log_regression. predict_proba (X_test)[::,1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred_proba)
auc = metrics. roc_auc_score (y_test, y_pred_proba)
#create ROC curve
plt. plot (fpr,tpr,label=" AUC= "+str(auc))
plt. legend (loc=4)
plt. show ()
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။