Python တွင် ols regression ကို မည်သို့လုပ်ဆောင်ရမည် (ဥပမာနှင့်အတူ)
သာမန်အနည်းဆုံးစတုရန်းများ (OLS) ဆုတ်ယုတ်မှုသည် ကျွန်ုပ်တို့အား ကြိုတင်ခန့်မှန်းကိန်းရှင်တစ်ခု သို့မဟုတ် တစ်ခုထက်ပိုသော ကိန်းရှင်များနှင့် တုံ့ပြန်မှုကိန်းရှင် ကြားရှိ ဆက်နွယ်မှုကို အကောင်းဆုံးဖော်ပြသည့် မျဉ်းတစ်ကြောင်းကို ရှာဖွေနိုင်စေသည့် နည်းလမ်းတစ်ခုဖြစ်သည်။
ဤနည်းလမ်းသည် ကျွန်ုပ်တို့အား အောက်ပါညီမျှခြင်းအား ရှာဖွေနိုင်စေသည်-
ŷ = b 0 + b 1 x
ရွှေ-
- ŷ : ခန့်မှန်းတုံ့ပြန်မှုတန်ဖိုး
- b 0 : ဆုတ်ယုတ်မှုမျဉ်း၏ မူလအစ
- b 1 : ဆုတ်ယုတ်မှုမျဉ်း၏ လျှောစောက်
ဤညီမျှခြင်းသည် ခန့်မှန်းသူနှင့် တုံ့ပြန်မှုကိန်းရှင်ကြား ဆက်နွယ်မှုကို နားလည်ရန် ကူညီပေးနိုင်ပြီး ခန့်မှန်းသူကိန်းရှင်၏တန်ဖိုးကို ပေးထားသည့် တုံ့ပြန်မှုကိန်းရှင်၏တန်ဖိုးကို ခန့်မှန်းရန် ၎င်းကို အသုံးပြုနိုင်သည်။
အောက်ဖော်ပြပါ အဆင့်ဆင့် ဥပမာသည် Python ရှိ OLS ဆုတ်ယုတ်မှုကို မည်သို့လုပ်ဆောင်ရမည်ကို ပြသထားသည်။
အဆင့် 1: ဒေတာကိုဖန်တီးပါ။
ဤဥပမာအတွက်၊ ကျွန်ုပ်တို့သည် ကျောင်းသား 15 ဦးအတွက် အောက်ပါ variable နှစ်ခုပါရှိသော ဒေတာအတွဲတစ်ခုကို ဖန်တီးပါမည်။
- စုစုပေါင်းလေ့လာခဲ့သည့် နာရီအရေအတွက်
- စာမေးပွဲရလဒ်
ကျွန်ုပ်တို့သည် တုံ့ပြန်မှုကိန်းရှင်အဖြစ် နာရီများကို ခန့်မှန်းပေးသည့်ကိန်းရှင်နှင့် စာမေးပွဲရမှတ်ကို အသုံးပြု၍ OLS ဆုတ်ယုတ်မှုကို လုပ်ဆောင်ပါမည်။
အောက်ပါကုဒ်သည် ပန်ဒါများတွင် ဤဒေတာအတွဲအတုကို ဖန်တီးနည်းကို ပြသသည်-
import pandas as pd #createDataFrame df = pd. DataFrame ({' hours ': [1, 2, 4, 5, 5, 6, 6, 7, 8, 10, 11, 11, 12, 12, 14], ' score ': [64, 66, 76, 73, 74, 81, 83, 82, 80, 88, 84, 82, 91, 93, 89]}) #view DataFrame print (df) hours score 0 1 64 1 2 66 2 4 76 3 5 73 4 5 74 5 6 81 6 6 83 7 7 82 8 8 80 9 10 88 10 11 84 11 11 82 12 12 91 13 12 93 14 14 89
အဆင့် 2- OLS ဆုတ်ယုတ်မှုကို လုပ်ဆောင်ပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် statsmodels module အတွင်းရှိလုပ်ဆောင်ချက်များကို OLS ဆုတ်ယုတ်မှုလုပ်ဆောင်ရန်၊ ကြိုတင်ခန့်မှန်းကိန်းရှင်ကိန်းရှင်အဖြစ် နာရီများ နှင့် တုံ့ပြန်မှု ကိန်းရှင်အဖြစ် ရမှတ်တို့ကို အသုံးပြု၍ OLS ဆုတ်ယုတ်မှုကို လုပ်ဆောင်နိုင်သည်-
import statsmodels.api as sm
#define predictor and response variables
y = df[' score ']
x = df[' hours ']
#add constant to predictor variables
x = sm. add_constant (x)
#fit linear regression model
model = sm. OLS (y,x). fit ()
#view model summary
print ( model.summary ())
OLS Regression Results
==================================================== ============================
Dept. Variable: R-squared score: 0.831
Model: OLS Adj. R-squared: 0.818
Method: Least Squares F-statistic: 63.91
Date: Fri, 26 Aug 2022 Prob (F-statistic): 2.25e-06
Time: 10:42:24 Log-Likelihood: -39,594
No. Observations: 15 AIC: 83.19
Df Residuals: 13 BIC: 84.60
Model: 1
Covariance Type: non-robust
==================================================== ============================
coef std err t P>|t| [0.025 0.975]
-------------------------------------------------- ----------------------------
const 65.3340 2.106 31.023 0.000 60.784 69.884
hours 1.9824 0.248 7.995 0.000 1.447 2.518
==================================================== ============================
Omnibus: 4,351 Durbin-Watson: 1,677
Prob(Omnibus): 0.114 Jarque-Bera (JB): 1.329
Skew: 0.092 Prob(JB): 0.515
Kurtosis: 1.554 Cond. No. 19.2
==================================================== ============================
coef ကော်လံမှ၊ ကျွန်ုပ်တို့သည် regression coefficients ကိုတွေ့နိုင်ပြီး အောက်ပါအတိုင်း တပ်ဆင်ထားသော regression equation ကို ရေးနိုင်သည်-
ရမှတ် = 65.334 + 1.9824*(နာရီ)
ဆိုလိုသည်မှာ ထပ်လောင်းလေ့လာထားသော နာရီတိုင်းသည် ပျမ်းမျှ စာမေးပွဲရမှတ် 1.9824 မှတ် တိုးလာခြင်းနှင့် ဆက်စပ်နေသည်။
65,334 ၏မူရင်းတန်ဖိုးသည် သုညနာရီစာလေ့လာနေသည့် ကျောင်းသားအတွက် ပျမ်းမျှမျှော်မှန်းထားသော စာမေးပွဲရမှတ်ကို ပြောပြသည်။
ကျောင်းသားတစ်ဦး၏လေ့လာမှုနာရီအရေအတွက်အပေါ်အခြေခံ၍မျှော်လင့်ထားသောစာမေးပွဲရမှတ်ကိုရှာဖွေရန်ဤညီမျှခြင်းကိုလည်းအသုံးပြုနိုင်သည်။
ဥပမာအားဖြင့်၊ 10 နာရီကြာလေ့လာသော ကျောင်းသားသည် စာမေးပွဲရမှတ် 85.158 ရရှိသင့်သည် ။
ရမှတ် = 65.334 + 1.9824*(10) = 85.158
ကျန်မော်ဒယ်အကျဉ်းချုပ်ကို ဤအရာက မည်သို့အဓိပ္ပာယ်ဖွင့်ဆိုနိုင်သည်-
- P(>|t|) : ၎င်းသည် မော်ဒယ်ဖော်ကိန်းများနှင့် ဆက်စပ်နေသည့် p တန်ဖိုးဖြစ်သည်။ နာရီ များအတွက် p-value (0.000) သည် 0.05 ထက်နည်းသောကြောင့်၊ နာရီ နှင့် ရမှတ် ကြားတွင် စာရင်းအင်းအရ သိသာထင်ရှားသော ဆက်စပ်မှုရှိသည်ဟု ကျွန်ုပ်တို့ပြောနိုင်သည်။
- R-squared- စာမေးပွဲရမှတ်များတွင် ကွဲလွဲမှုရာခိုင်နှုန်းကို လေ့လာသည့်နာရီအရေအတွက်ဖြင့် ရှင်းပြနိုင်သည်ဟု ၎င်းကဆိုသည်။ ဤကိစ္စတွင်၊ ရမှတ်များကွဲလွဲမှု၏ 83.1% ကို နာရီများဖြင့် ရှင်းပြနိုင်သည်။
- F-statistic နှင့် p-value- F-statistic ( 63.91 ) နှင့် သက်ဆိုင်သော p-value ( 2.25e-06 ) သည် ဆုတ်ယုတ်မှုပုံစံ၏ ယေဘုယျအဓိပ္ပာယ်ကို ပြောပြသည်၊ ဆိုလိုသည်မှာ မော်ဒယ်ရှိ ကြိုတင်ခန့်မှန်းကိန်းရှင်များသည် ကွဲလွဲမှုကို ရှင်းပြရာတွင် အသုံးဝင်သလား။ တုံ့ပြန်မှု variable တွင်။ ဤဥပမာရှိ p-value သည် 0.05 ထက်နည်းသောကြောင့်၊ ကျွန်ုပ်တို့၏မော်ဒယ်သည် ကိန်းဂဏန်းအရ သိသာထင်ရှားပြီး ရမှတ် ကွဲလွဲမှုကို ရှင်းပြရာတွင် နာရီများကို အသုံးဝင်သည်ဟု ယူဆပါသည်။
အဆင့် 3- အသင့်တော်ဆုံးလိုင်းကို မြင်ယောင်ကြည့်ပါ။
နောက်ဆုံးတွင်၊ ကျွန်ုပ်တို့သည် အမှန်တကယ် ဒေတာအချက်များနှင့် ကိုက်ညီသော ဆုတ်ယုတ်မှုမျဉ်းအား မြင်သာစေရန် matplotlib data visualization package ကို အသုံးပြုနိုင်ပါသည်။
import matplotlib. pyplot as plt
#find line of best fit
a, b = np. polyfit (df[' hours '], df[' score '], 1 )
#add points to plot
plt. scatter (df[' hours '], df[' score '], color=' purple ')
#add line of best fit to plot
plt. plot (df[' hours '], a*df[' hours ']+b)
#add fitted regression equation to plot
plt. text ( 1 , 90 , 'y = ' + '{:.3f}'.format(b) + ' + {:.3f}'.format(a) + 'x', size= 12 )
#add axis labels
plt. xlabel (' Hours Studied ')
plt. ylabel (' Exam Score ')
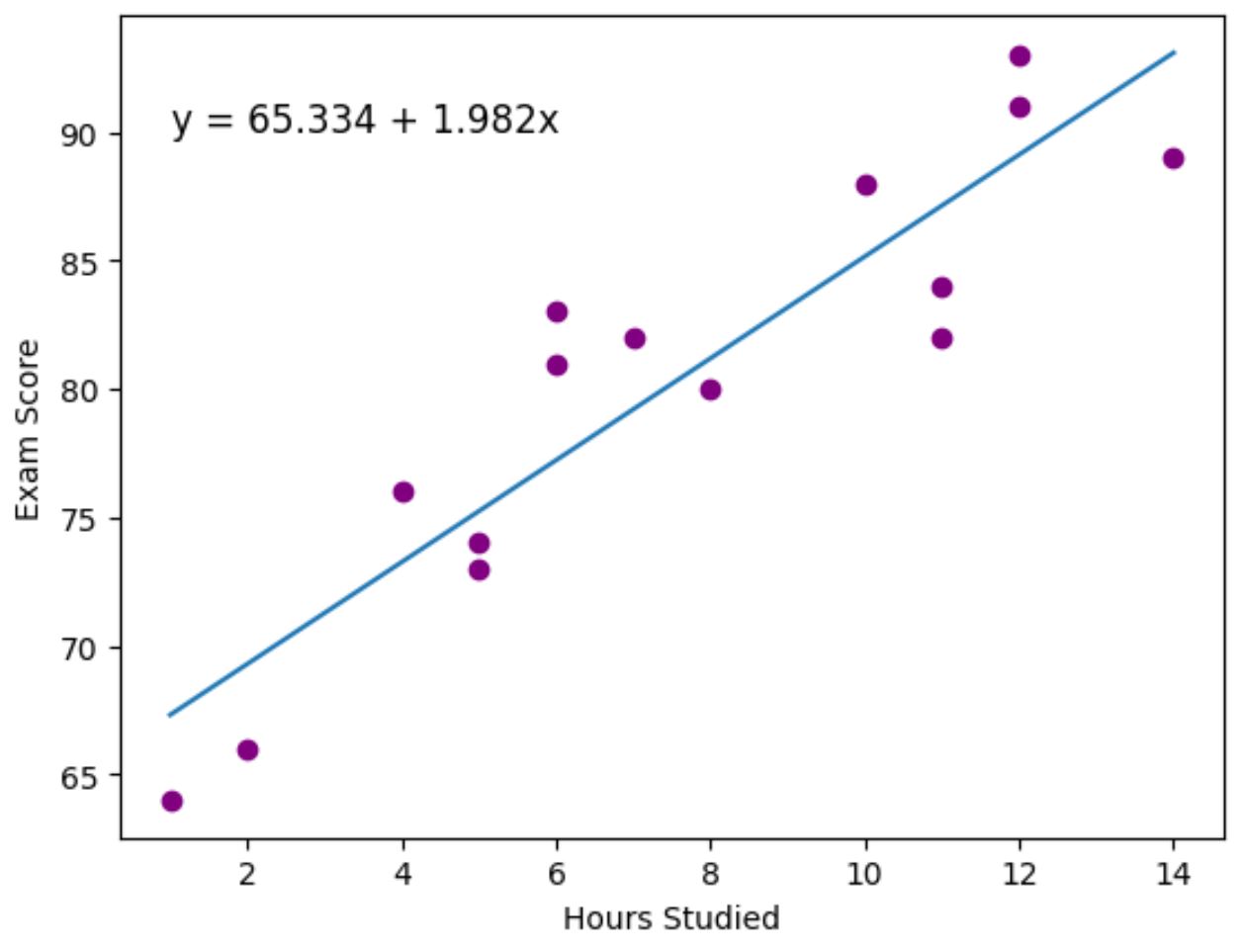
ခရမ်းရောင်အစက်များသည် တကယ့်ဒေတာအမှတ်များကို ကိုယ်စားပြုပြီး အပြာလိုင်းသည် တပ်ဆင်ထားသော ဆုတ်ယုတ်မှုမျဉ်းကို ကိုယ်စားပြုသည်။
ကွက်ကွက်၏ ဘယ်ဘက်အပေါ်ထောင့်တွင် တပ်ဆင်ထားသော ဆုတ်ယုတ်မှုညီမျှခြင်းကို ထည့်ရန် plt.text() လုပ်ဆောင်ချက်ကိုလည်း အသုံးပြုခဲ့သည်။
ဂရပ်ကိုကြည့်လျှင် တပ်ဆင်ထားသော ဆုတ်ယုတ်မှုမျဉ်းသည် နာရီ variable နှင့် ရမှတ် variable အကြား ဆက်နွယ်မှုကို ကောင်းစွာဖမ်းယူထားပုံရသည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် Python တွင် အခြားသော အသုံးများသော အလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
Python တွင် Logistic Regression ကို မည်သို့လုပ်ဆောင်မည်နည်း။
Python တွင် Exponential Regression လုပ်ဆောင်နည်း
Python ရှိ regression မော်ဒယ်များ၏ AIC တွက်ချက်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။