Scikit-learn ကို အသုံးပြု၍ polynomial regression ကို မည်သို့လုပ်ဆောင်မည်နည်း။
Polynomial regression သည် ကြိုတင်ခန့်မှန်းကိန်းရှင်နှင့် တုံ့ပြန်မှုကိန်းရှင် သည် linear မဟုတ်သည့်အခါ ကျွန်ုပ်တို့အသုံးပြုနိုင်သည့် နည်းလမ်းတစ်ခုဖြစ်သည်။
ဤဆုတ်ယုတ်မှုအမျိုးအစားသည် ပုံစံယူသည်-
Y = β 0 + β 1 X + β 2 X 2 + … + β h
h သည် polynomial ၏ “ ဒီဂရီ” ဖြစ်သည်။
အောက်ဖော်ပြပါ အဆင့်ဆင့် ဥပမာသည် sklearn ကို အသုံးပြု၍ Python တွင် polynomial regression လုပ်ဆောင်ပုံကို ပြသထားသည်။
အဆင့် 1: ဒေတာကိုဖန်တီးပါ။
ပထမဦးစွာ၊ ခန့်မှန်းသူ၏တန်ဖိုးများနှင့် တုံ့ပြန်မှုကိန်းရှင်တစ်ခုအား ထိန်းသိမ်းရန် NumPy အခင်းအကျင်းနှစ်ခုကို ဖန်တီးကြပါစို့။
import matplotlib. pyplot as plt import numpy as np #define predictor and response variables x = np. array ([2, 3, 4, 5, 6, 7, 7, 8, 9, 11, 12]) y = np. array ([18, 16, 15, 17, 20, 23, 25, 28, 31, 30, 29]) #create scatterplot to visualize relationship between x and y plt. scatter (x,y)
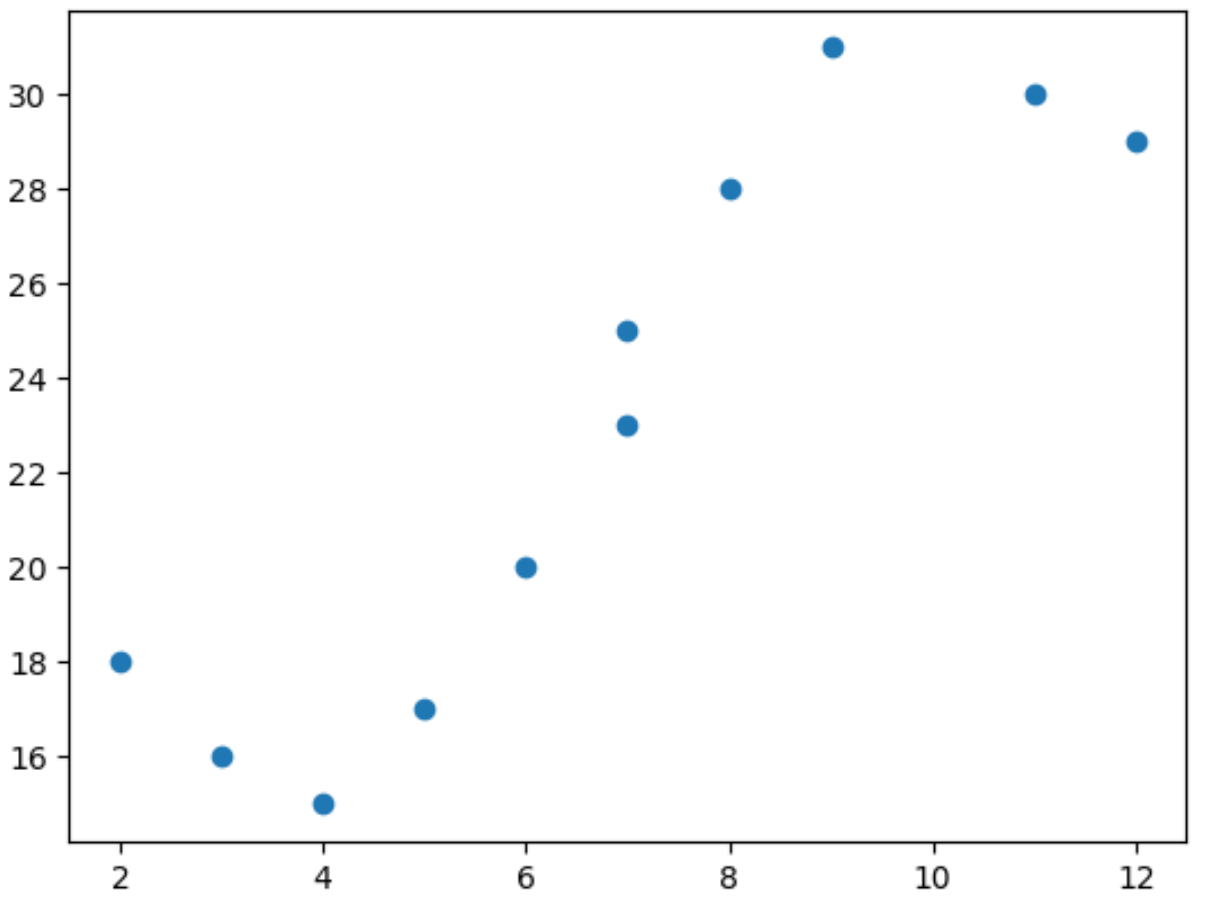
scatterplot မှ x နှင့် y အကြား ဆက်နွယ်မှုမှာ linear မဟုတ်ကြောင်း ကျွန်ုပ်တို့ သိနိုင်သည်။
ထို့ကြောင့် ကိန်းရှင်နှစ်ခုကြားတွင် မျဉ်းမညီသော ဆက်နွယ်မှုကို ဖမ်းယူရန်အတွက် ကိန်းရှင်နှစ်ခုကြားတွင် မျဉ်းဖြောင့်မဟုတ်သော ဆက်စပ်မှုကို ဖမ်းယူရန်အတွက် ကိန်းဂဏန်းများ ကိန်းဂဏန်းများ ဆုတ်ယုတ်မှုပုံစံကို ဒေတာနှင့် အံဝင်ခွင်ကျဖြစ်အောင် ပေါင်းစည်းရန် စိတ်ကူးကောင်းတစ်ခုဖြစ်သည်။
အဆင့် 2- polynomial ဆုတ်ယုတ်မှုပုံစံကို အံကိုက်လုပ်ပါ။
အောက်ဖော်ပြပါ ကုဒ်သည် ဤဒေတာအတွဲအတွက် ဒီဂရီ 3 ကိန်းဂဏန်း ဆုတ်ယုတ်မှုပုံစံကို အံဝင်ခွင်ကျဖြစ်စေရန်အတွက် sklearn လုပ်ဆောင်ချက်များကို မည်သို့အသုံးပြုရမည်ကို ပြသသည်-
from sklearn. preprocessing import PolynomialFeatures
from sklearn. linear_model import LinearRegression
#specify degree of 3 for polynomial regression model
#include bias=False means don't force y-intercept to equal zero
poly = PolynomialFeatures(degree= 3 , include_bias= False )
#reshape data to work properly with sklearn
poly_features = poly. fit_transform ( x.reshape (-1, 1))
#fit polynomial regression model
poly_reg_model = LinearRegression()
poly_reg_model. fit (poly_features,y)
#display model coefficients
print (poly_reg_model. intercept_ , poly_reg_model. coef_ )
33.62640037532282 [-11.83877127 2.25592957 -0.10889554]
နောက်ဆုံးအတန်းတွင်ပြသထားသော model coefficients များကိုအသုံးပြု၍ တပ်ဆင်ထားသော polynomial regression equation ကို အောက်ပါအတိုင်းရေးနိုင်ပါသည်-
y = -0.109x 3 + 2.256x 2 – 11.839x + 33.626
ခန့်မှန်းထားသောကိန်းရှင်၏ပေးထားသောတန်ဖိုးကိုပေးထားသောတုံ့ပြန်မှုကိန်းရှင်၏မျှော်မှန်းတန်ဖိုးကိုရှာဖွေရန် ဤညီမျှခြင်းအားအသုံးပြုနိုင်သည်။
ဥပမာ၊ x သည် 4 ဖြစ်ပါက၊ တုံ့ပြန်မှုကိန်းရှင်အတွက် မျှော်မှန်းတန်ဖိုးမှာ y သည် 15.39 ဖြစ်လိမ့်မည်။
y = -0.109(4) 3 + 2.256(4) 2 – 11.839(4) + 33.626= 15.39
မှတ်ချက် – ခြားနားသောဒီဂရီတစ်ခုနှင့် polynomial ဆုတ်ယုတ်မှုပုံစံတစ်ခုကို အံဝင်ခွင်ကျဖြစ်စေရန်၊ PolynomialFeatures() လုပ်ဆောင်ချက်ရှိ ဒီဂရီ အငြင်းအခုံ၏တန်ဖိုးကို ပြောင်းလဲပါ။
အဆင့် 3- polynomial ဆုတ်ယုတ်မှုပုံစံကို မြင်ယောင်ကြည့်ပါ။
နောက်ဆုံးတွင်၊ မူရင်းဒေတာအချက်များနှင့် ကိုက်ညီသည့် polynomial regression model ကို မြင်သာစေရန် ရိုးရှင်းသော ကြံစည်မှုကို ဖန်တီးနိုင်သည်-
#use model to make predictions on response variable
y_predicted = poly_reg_model. predict (poly_features)
#create scatterplot of x vs. y
plt. scatter (x,y)
#add line to show fitted polynomial regression model
plt. plot (x,y_predicted,color=' purple ')
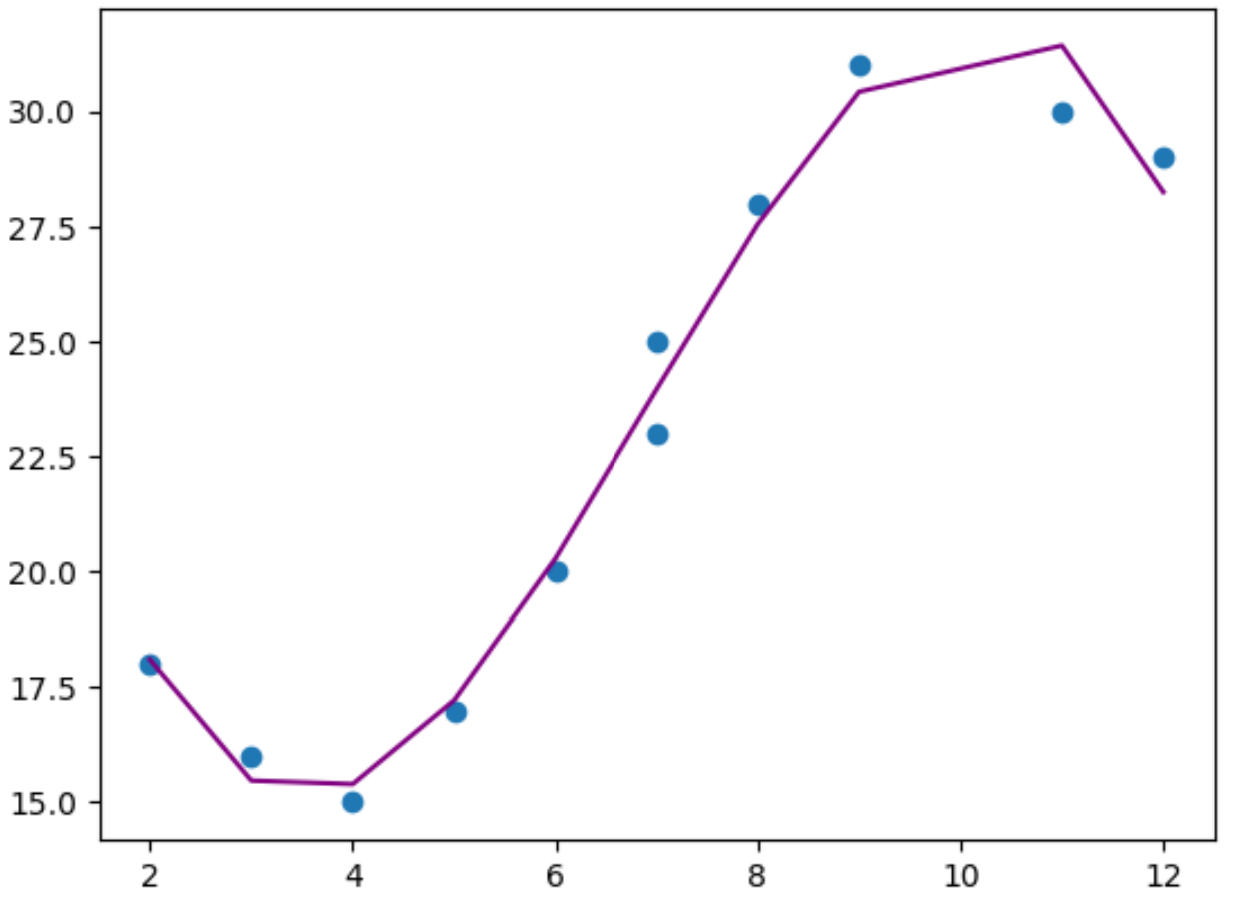
ဂရပ်မှ၊ polynomial regression model သည် overfitting မရှိဘဲ data ကို ကောင်းမွန်စွာ အံဝင်ခွင်ကျဖြစ်ပုံရသည်။
မှတ်ချက် – sklearn PolynomialFeatures() လုပ်ဆောင်ချက်အတွက် စာရွက်စာတမ်းအပြည့်အစုံကို ဤနေရာတွင် ရှာဖွေနိုင်ပါသည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် sklearn ကိုအသုံးပြု၍ အခြားဘုံအလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
sklearn မှ regression coefficients များကို မည်သို့ထုတ်ယူမည်နည်း။
sklearn ကို အသုံးပြု၍ မျှတသောတိကျမှုကို တွက်ချက်နည်း
Sklearn တွင် အမျိုးအစားခွဲခြင်းအစီရင်ခံစာကို မည်သို့အဓိပ္ပာယ်ဖွင့်ဆိုမည်နည်း။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။