Polynomial regression နိဒါန်း
ကျွန်ုပ်တို့တွင် ကိန်းရှင်ကိန်းရှင်တစ်ခုနှင့် တုံ့ပြန်မှုကိန်းရှင်တစ်ခု ပါသည့် ဒေတာအတွဲတစ်ခုရှိသောအခါ၊ ကိန်းရှင်နှစ်ခုကြားရှိ ဆက်နွယ်မှုကို တွက်ချက်ရန် ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှုကို မကြာခဏအသုံးပြုသည်။
သို့သော်၊ ရိုးရှင်းသောမျဉ်းကြောင်းဆုတ်ယုတ်မှု (SLR) သည် ကြိုတင်ခန့်မှန်းသူနှင့် တုံ့ပြန်မှုကိန်းရှင်ကြား ဆက်နွယ်မှုမှာ မျဉ်းကြောင်းညီသည်ဟု ယူဆသည်။ သင်္ချာအမှတ်အသားဖြင့် ရေးထားသော SLR သည် ဆက်ဆံရေးပုံစံကို ယူဆောင်သည်ဟု ယူဆသည်-
Y = β 0 + β 1 X + ε
သို့သော် လက်တွေ့တွင်၊ variable နှစ်ခုကြားရှိ ဆက်စပ်မှုသည် အမှန်တကယ် linear မဟုတ်သဖြင့် linear regression ကိုအသုံးပြုရန်ကြိုးစားခြင်းသည် ညံ့ဖျင်းသော model ကိုဖြစ်ပေါ်စေပါသည်။
ကြိုတင်ခန့်မှန်းသူနှင့် တုံ့ပြန်မှု variable အကြား လိုင်းမဟုတ်သော ဆက်နွယ်မှုကို တွက်ချက်ရန် နည်းလမ်းတစ်ခုမှာ ပုံစံယူထားသည့် polynomial regression ကို အသုံးပြုခြင်းဖြစ်သည်-
Y = β 0 + β 1 X + β 2 X 2 + … + β h
ဤညီမျှခြင်းတွင် h ကို polynomial ၏ ဒီဂရီ ဟုခေါ်သည်။
h ၏တန်ဖိုးကို တိုးလာသည်နှင့်အမျှ၊ မော်ဒယ်သည် လိုင်းမဟုတ်သော ဆက်ဆံရေးများကို ပိုမိုကောင်းမွန်စွာ လိုက်လျောညီထွေဖြစ်စေနိုင်သော်လည်း လက်တွေ့တွင် h ကို 3 သို့မဟုတ် 4 ထက်ကြီးစေရန် ရွေးချယ်ခဲပါသည်။ ဤအချက်ကိုကျော်လွန်၍ မော်ဒယ်သည် ပျော့ပြောင်းလွန်းပြီး ဒေတာကို ပိုပြည့်စေပါသည် ။
နည်းပညာမှတ်စုများ
- polynomial regression သည် nonlinear data နှင့် အံဝင်ခွင်ကျဖြစ်နိုင်သော်လည်း၊ coefficients β1 , β2 , …, βh တွင် linear ဖြစ်နေသောကြောင့် linear regression ၏ပုံစံဟု ယူဆဆဲဖြစ်သည်။
- Polynomial regression ကို ကြိုတင်ခန့်မှန်းကိန်းရှင်များစွာအတွက်လည်း သုံးနိုင်သည်၊ သို့သော် ၎င်းသည် မော်ဒယ်ရှိ အပြန်အလှန်အသုံးအနှုန်းများကို ဖန်တီးပေးကာ ခန့်မှန်းသူကိန်းရှင်များစွာကို အသုံးပြုပါက မော်ဒယ်ကို အလွန်ရှုပ်ထွေးသွားစေနိုင်သည်။
ဘယ်အချိန်မှာ polynomial regression ကိုသုံးမလဲ။
ကြိုတင်ခန့်မှန်းသူနှင့် တုံ့ပြန်မှုကိန်းရှင်ကြား ဆက်နွယ်မှုမှာ လိုင်းမဟုတ်သည့်အခါ ပေါလီအမည်ဆုတ်ယုတ်ခြင်းကို ကျွန်ုပ်တို့အသုံးပြုသည်။
လိုင်းမဟုတ်သော ဆက်ဆံရေးကို ရှာဖွေရန် ဘုံနည်းလမ်းသုံးမျိုးရှိသည်။
1. အပိုင်းအစတစ်ခု ဖန်တီးပါ။
လိုင်းမဟုတ်သော ဆက်နွယ်မှုကို ရှာဖွေရန် အရိုးရှင်းဆုံးနည်းလမ်းမှာ ကြိုတင်ခန့်မှန်းကိန်းရှင်နှင့် တုံ့ပြန်မှုကိန်းရှင်၏ အပိုင်းအစတစ်ခုကို ဖန်တီးရန်ဖြစ်သည်။
ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့သည် အောက်ပါ scatterplot ကိုဖန်တီးပါက၊ variable နှစ်ခုကြားရှိ ဆက်နွှယ်မှုသည် ခန့်မှန်းခြေအားဖြင့် linear ဖြစ်သည်၊ ထို့ကြောင့် ရိုးရှင်းသော linear regression သည် ဤ data တွင် ကောင်းမွန်စွာအလုပ်လုပ်နိုင်မည်ဖြစ်သည်။
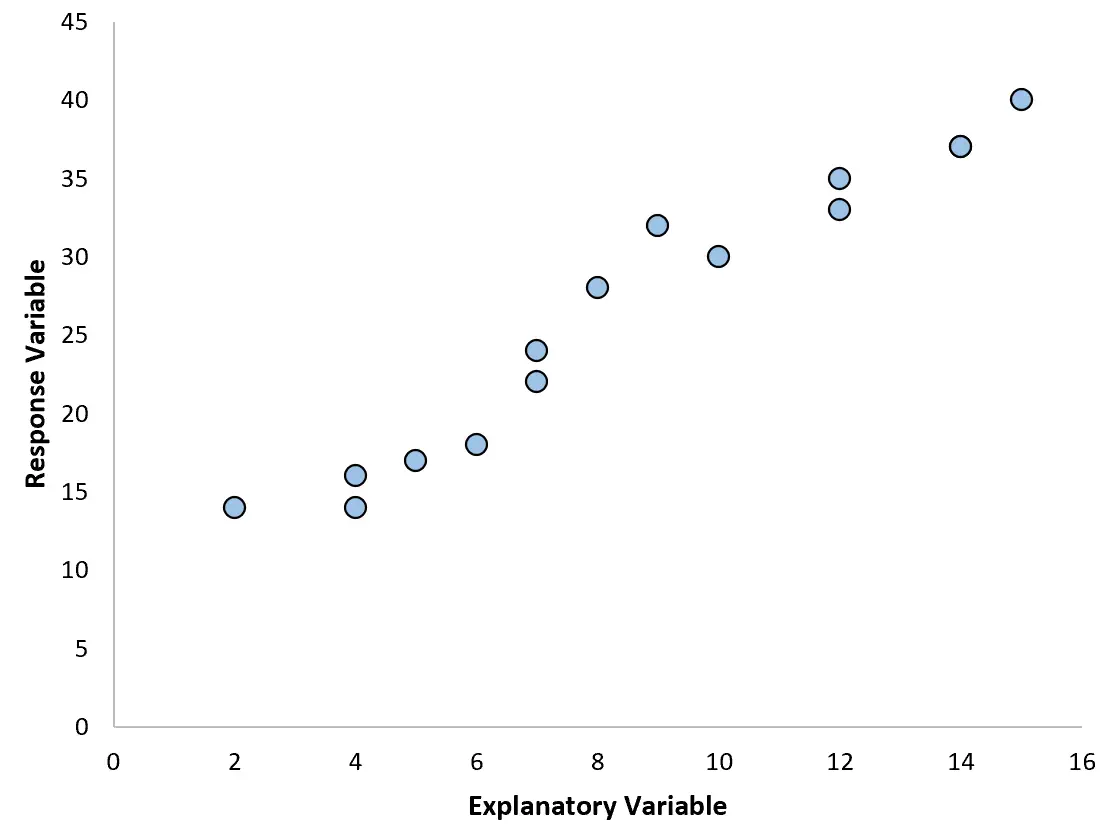
သို့သော်၊ ကျွန်ုပ်တို့၏ ခွဲခြမ်းစိတ်ဖြာမှုသည် အောက်ပါဂရပ်များထဲမှ တစ်ခုနှင့်တူပါက၊ ဆက်ဆံရေးသည် အလိုင်းနားမဟုတ်သည့်အတွက်ကြောင့် များစွာသော ဆုတ်ယုတ်မှုဖြစ်မည်မှာ ကောင်းမွန်သော အကြံဥာဏ်တစ်ခုဖြစ်သည်-
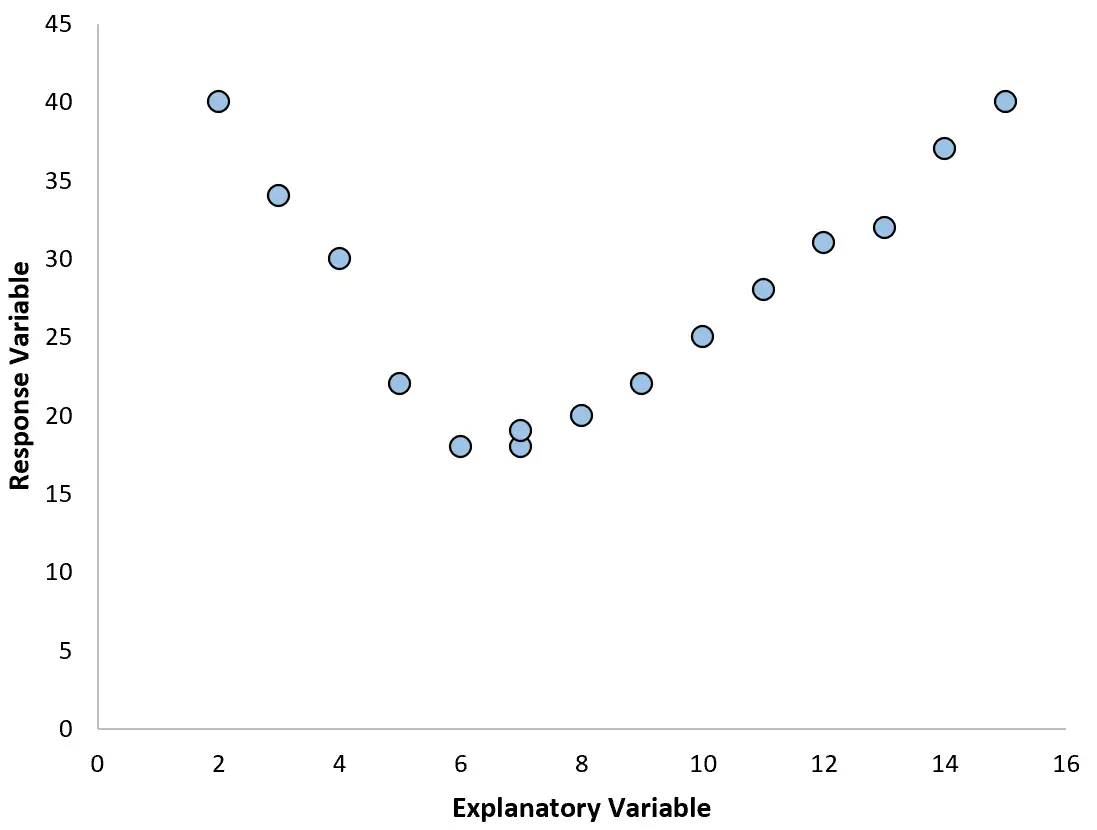
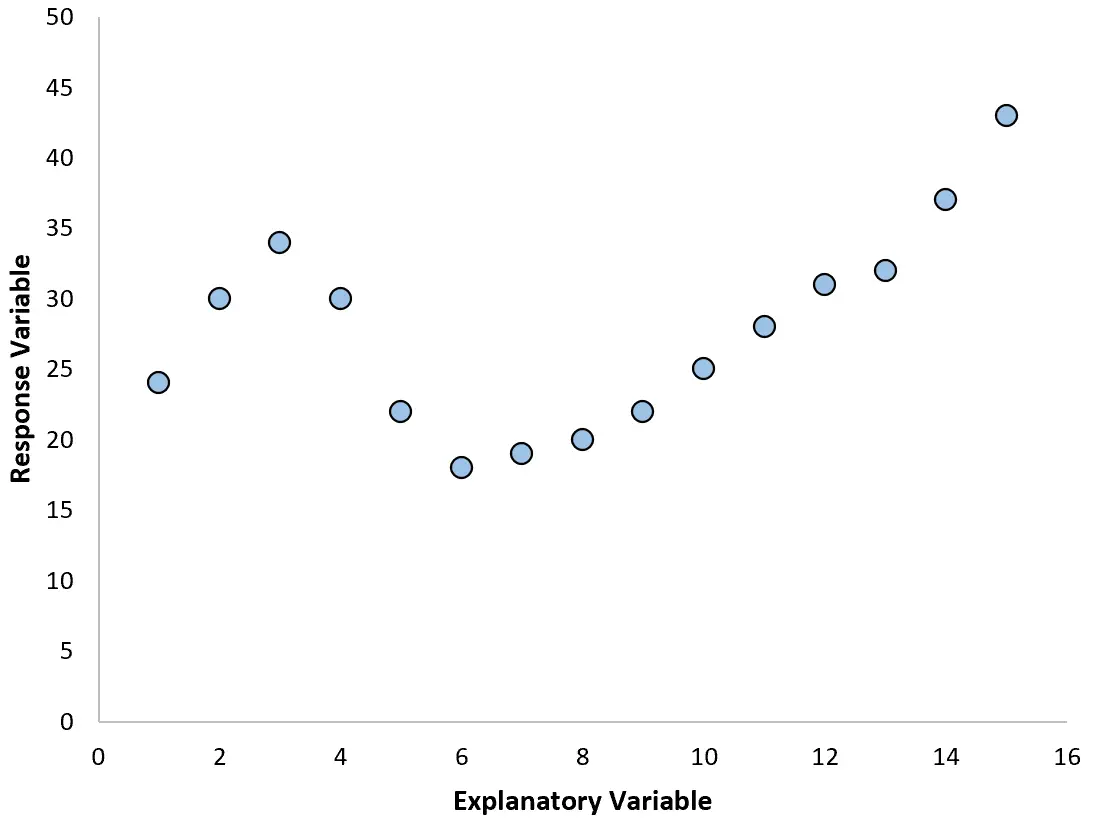
2. တပ်ဆင်ထားသော ကွက်ကွက်နှင့် ဆန့်ကျင်ဘက် အကြွင်းအကျန်များကို တစ်ကွက်ဖန်တီးပါ။
လိုင်းမညီခြင်းကို ရှာဖွေရန် အခြားနည်းလမ်းမှာ ဒေတာနှင့် ရိုးရှင်းသော linear regression မော်ဒယ်ကို ဖြည့်သွင်းပြီး တပ်ဆင်ထားသော တန်ဖိုးများနှင့် အကြွင်းအကျန်များကို တစ်ကွက်စီ ထုတ်လုပ်ရန်ဖြစ်သည်။
အကြွင်းအကျန်များကို ရှင်းလင်းပြတ်သားသောလမ်းကြောင်းမရှိသော သုညဝန်းကျင်ခန့် အညီအမျှ ဖြန့်ဝေပါက၊ ရိုးရှင်းသော မျဉ်းကြောင်းဆုတ်ယုတ်မှုမှာ လုံလောက်ပါသည်။
သို့သော်၊ အကြွင်းအကျန်များသည် ဂရပ်တွင် လိုင်းမညီသောလမ်းကြောင်းကို ပြသပါက၊ ခန့်မှန်းသူနှင့် တုံ့ပြန်မှုကြား ဆက်နွှယ်မှုသည် လိုင်းမဆန်ဖွယ်ရှိကြောင်း ညွှန်ပြနေသည်။
3. မော်ဒယ်၏ R 2 ကို တွက်ချက်ပါ။
ဆုတ်ယုတ်မှုပုံစံတစ်ခု၏ R 2 တန်ဖိုးသည် ခန့်မှန်းသူကိန်းရှင်(များ) မှ ရှင်းပြနိုင်သည့် တုံ့ပြန်မှုကိန်းရှင်၏ ကွဲလွဲမှုရာခိုင်နှုန်းကို ပြောပြသည်။
အကယ်၍ သင်သည် ရိုးရှင်းသော linear regression model ကို data set တစ်ခုနှင့် အံဝင်ခွင်ကျဖြစ်ပြီး model ၏ R 2 value သည် အလွန်နိမ့်ပါက၊ ခန့်မှန်းသူနှင့် response variable အကြား ဆက်ဆံရေးသည် ရိုးရှင်းသော linear ဆက်ဆံရေးထက် ပိုမိုရှုပ်ထွေးကြောင်း ညွှန်ပြနိုင်သည်။
၎င်းသည် သင်အစား polynomial regression ကို စမ်းကြည့်ရန် လိုအပ်နိုင်သည်ဟူသော လက္ခဏာတစ်ခု ဖြစ်နိုင်သည်။
ဆက်စပ်မှု- ကောင်းသော R-squared တန်ဖိုးဆိုသည်မှာ အဘယ်နည်း။
polynomial ၏ ဒီဂရီကို မည်သို့ရွေးချယ်ရမည်နည်း။
polynomial regression model သည် အောက်ပါပုံစံကို ယူပါသည်။
Y = β 0 + β 1 X + β 2 X 2 + … + β h
ဤညီမျှခြင်းတွင် h သည် polynomial ၏ဒီဂရီဖြစ်သည်။
ဒါပေမယ့် h ရဲ့တန်ဖိုးကို ဘယ်လိုရွေးမလဲ။
လက်တွေ့တွင်၊ ကျွန်ုပ်တို့သည် h ၏တန်ဖိုးအမျိုးမျိုးဖြင့် မတူညီသောမော်ဒယ်များစွာကို တပ်ဆင်ပြီး မည်သည့်မော်ဒယ်က အနိမ့်ဆုံးစမ်းသပ်မှုဆိုလိုသည့် နှစ်ထပ်အမှား (MSE) ကိုထုတ်ပေးသည်ကို ဆုံးဖြတ်ရန် k-fold cross-validation လုပ်ဆောင်ပါသည်။
ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့သည် အောက်ပါ မော်ဒယ်များကို ပေးထားသည့် ဒေတာအတွဲတစ်ခုနှင့် ကိုက်ညီနိုင်သည်-
- Y = β 0 + β 1
- Y = β 0 + β 1 X + β 2 X 2
- Y = β0 + β1X + β2X2 + β3X3
- Y = β 0 + β 1 X + β 2 X 2 + β 3 X 3 + β 4 X 4
ထို့နောက် မော်ဒယ်တစ်ခုစီအတွက် MSE စမ်းသပ်မှုကို တွက်ချက်ရန် k-fold cross-validation ကို အသုံးပြုနိုင်ပြီး၊ ၎င်းသည် မော်ဒယ်တစ်ခုစီသည် ယခင်ကမမြင်ဖူးသော data များအပေါ် မည်မျှ ကောင်းမွန်စွာ လုပ်ဆောင်သည်ကို ကျွန်ုပ်တို့အား ပြောပြမည်ဖြစ်သည်။
polynomial regression ၏ ဘက်လိုက်-ကွဲလွဲမှု ဖလှယ်မှု
polynomial regression ကိုအသုံးပြုသောအခါတွင် ဘက်လိုက်မှုကွဲလွဲမှု အပေးအယူ ရှိပါသည်။ polynomial ၏ဒီဂရီကို တိုးလာသည်နှင့်အမျှ၊ ဘက်လိုက်မှု လျော့နည်းသွားသည် (မော်ဒယ်သည် ပိုမိုပြောင်းလွယ်ပြင်လွယ်ဖြစ်လာသည်) သို့သော် ကွဲလွဲမှု တိုးလာသည်။
စက်သင်ယူမှုမော်ဒယ်များအားလုံးကဲ့သို့ပင်၊ ကျွန်ုပ်တို့သည် ဘက်လိုက်မှုနှင့် ကွဲပြားမှုအကြား အကောင်းဆုံးသော ဖလှယ်မှုကို ရှာဖွေရန် လိုအပ်ပါသည်။
အခြေအနေအများစုတွင်၊ ၎င်းသည် polynomial ၏ဒီဂရီကို အတိုင်းအတာတစ်ခုအထိ တိုးမြှင့်ခွင့်ပြုသော်လည်း အချို့သောတန်ဖိုးထက်ကျော်လွန်၍ မော်ဒယ်သည် ဒေတာရှိဆူညံသံနှင့် လိုက်လျောညီထွေဖြစ်အောင်စပြုပြီး စမ်းသပ်မှု၏ MSE သည် လျော့နည်းလာသည်။
ကျွန်ုပ်တို့သည် လိုက်လျောညီထွေရှိသော်လည်း လိုက်လျောညီထွေမဖြစ်နိုင်သော မော်ဒယ်တစ်ခုနှင့် အံဝင်ခွင်ကျ မဖြစ်စေရန် သေချာစေရန်၊ အနိမ့်ဆုံး MSE စမ်းသပ်မှုကို ထုတ်လုပ်သည့် မော်ဒယ်ကိုရှာဖွေရန် k-fold cross-validation ကို အသုံးပြုပါသည်။
polynomial regression ကို ဘယ်လိုလုပ်ဆောင်မလဲ။
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် မတူညီသောဆော့ဖ်ဝဲလ်တွင် ပေါလီအမည်ဆုတ်ယုတ်ခြင်းကို လုပ်ဆောင်ပုံဥပမာများကို ပေးဆောင်သည်-
Excel တွင် Polynomial Regression ကို မည်သို့လုပ်ဆောင်မည်နည်း။
R တွင် polynomial regression ကို မည်သို့လုပ်ဆောင်ရမည်နည်း
Python တွင် polynomial regression လုပ်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။