Python တွင် one-hot encoding ပြုလုပ်နည်း
One-hot encoding ကို machine learning algorithms မှ အလွယ်တကူ အသုံးပြုနိုင်သော အမျိုးအစားအဖြစ် ပြောင်းလဲနိုင်သော အမျိုးအစားအဖြစ် ပြောင်းလဲရန် အသုံးပြုပါသည်။
one-hot coding ၏ အခြေခံအယူအဆမှာ 0 နှင့် 1 တန်ဖိုးများကို မူရင်းအမျိုးအစားတန်ဖိုးများကိုကိုယ်စားပြုရန်အတွက် variable အသစ်များကိုဖန်တီးရန်ဖြစ်သည်။
ဥပမာအားဖြင့်၊ အောက်ပါပုံသည် 0 နှင့် 1 တန်ဖိုးများသာရှိသော အမျိုးအစားအသစ်များပါရှိသော အဖွဲ့အမည်များပါရှိသော အမျိုးအစားကွဲပြားသော variable တစ်ခုကို ပြောင်းလဲရန်အတွက် ကျွန်ုပ်တို့သည် one-hot ကုဒ်နံပါတ်ကို မည်သို့ပြသထားသည်ကို ပြသသည်-
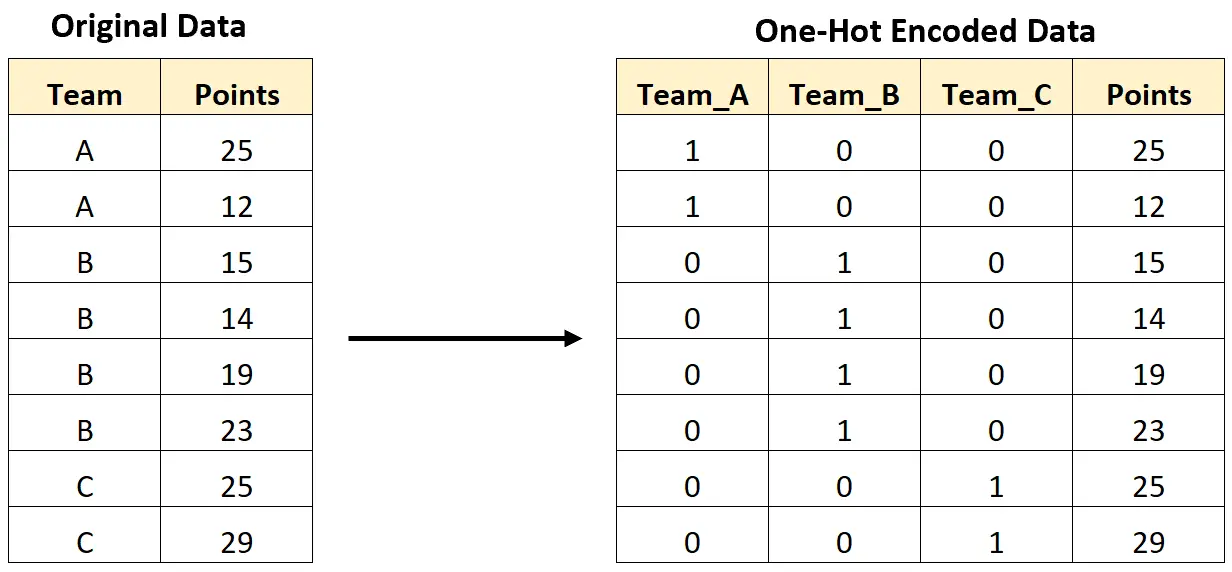
အောက်ပါ အဆင့်ဆင့် ဥပမာသည် Python ရှိ ဤအတိအကျဒေတာအတွဲအတွက် one-hot encoding လုပ်နည်းကို ပြသထားသည်။
အဆင့် 1: ဒေတာကိုဖန်တီးပါ။
ပထမဦးစွာ၊ အောက်ပါပန်ဒါ DataFrame ကိုဖန်တီးကြပါစို့။
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'], ' points ': [25, 12, 15, 14, 19, 23, 25, 29]}) #view DataFrame print (df) team points 0 to 25 1 to 12 2 B 15 3 B 14 4 B 19 5 B 23 6 C 25 7 C 29
အဆင့် 2- ပူပြင်းသော ကုဒ်နံပါတ်ကို လုပ်ဆောင်ပါ။
ထို့နောက်၊ sklearn စာကြည့်တိုက်မှ OneHotEncoder() လုပ်ဆောင်ချက်ကို တင်သွင်းပြီး pandas DataFrame ရှိ ‘team’ variable တွင် hot encoding ကိုလုပ်ဆောင်ရန် ၎င်းကိုအသုံးပြုကြပါစို့။
from sklearn. preprocessing import OneHotEncoder #creating instance of one-hot-encoder encoder = OneHotEncoder(handle_unknown=' ignore ') #perform one-hot encoding on 'team' column encoder_df = pd. DataFrame ( encoder.fit_transform (df[[' team ']]). toarray ()) #merge one-hot encoded columns back with original DataFrame final_df = df. join (encoder_df) #view final df print (final_df) team points 0 1 2 0 to 25 1.0 0.0 0.0 1 to 12 1.0 0.0 0.0 2 B 15 0.0 1.0 0.0 3 B 14 0.0 1.0 0.0 4 B 19 0.0 1.0 0.0 5 B 23 0.0 1.0 0.0 6 C 25 0.0 0.0 1.0 7 C 29 0.0 0.0 1.0
မူရင်း “ အဖွဲ့” ကော်လံတွင် ထူးခြားသောတန်ဖိုး သုံးခုပါရှိသောကြောင့် ကော်လံအသစ်သုံးခုကို DataFrame သို့ ပေါင်းထည့်ခဲ့ကြောင်း သတိပြုပါ။
မှတ်ချက် – OneHotEncoder() လုပ်ဆောင်ချက်အတွက် စာရွက်စာတမ်းအပြည့်အစုံကို ဤနေရာတွင် ရှာဖွေနိုင်ပါသည်။
အဆင့် 3- မူရင်း categorical variable ကို ဖယ်ရှားပါ။
နောက်ဆုံးတွင်၊ ကျွန်ုပ်တို့သည် ၎င်းကို မလိုအပ်တော့သောကြောင့် မူရင်း ‘အဖွဲ့’ variable ကို DataFrame မှ ဖယ်ရှားနိုင်သည်-
#drop 'team' column final_df. drop (' team ', axis= 1 , inplace= True ) #view final df print (final_df) points 0 1 2 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
ဆက်စပ်- Pandas ရှိ ကော်လံများကို ဖျက်နည်း (နည်းလမ်း 4 ခု)
၎င်းတို့ကိုဖတ်ရလွယ်ကူစေရန် နောက်ဆုံး DataFrame ၏ကော်လံများကိုလည်း အမည်ပြောင်းနိုင်သည်-
#rename columns final_df. columns = ['points', 'teamA', 'teamB', 'teamC'] #view final df print (final_df) points teamA teamB teamC 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
One-hot encoding ပြီးပါပြီ၊ ယခုကျွန်ုပ်တို့လိုချင်သော မည်သည့် machine learning algorithm တွင် ဤပန်ဒါ DataFrame ကို ထည့်သွင်းနိုင်ပါပြီ။
ထပ်လောင်းအရင်းအမြစ်များ
Python တွင် ဖြတ်တောက်ထားသော ဆိုလိုရင်းကို တွက်ချက်နည်း
Python တွင် linear regression လုပ်နည်း
Python တွင် Logistic Regression ကို မည်သို့လုပ်ဆောင်မည်နည်း။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။