R ဖြင့် multidimensional scaling လုပ်နည်း (ဥပမာဖြင့်)
စာရင်းဇယားများတွင်၊ ဘက်စုံစကေးချဲ့ခြင်းသည် စိတ္တဇ Cartesian space (များသောအားဖြင့် 2D အာကာသ) ရှိ ဒေတာအတွဲတစ်ခုရှိ စူးစမ်းလေ့လာမှုများ၏ တူညီမှုကို မြင်သာစေရန် နည်းလမ်းတစ်ခုဖြစ်သည်။
R တွင် multidimensional scaling ကိုလုပ်ဆောင်ရန် အလွယ်ဆုံးနည်းလမ်းမှာ အောက်ပါအခြေခံ syntax ကိုအသုံးပြုထားသည့် built-in cmdscale() လုပ်ဆောင်ချက်ကို အသုံးပြုရန်ဖြစ်သည်။
cmdscale(d၊ eig = FALSE၊ k = 2၊ …)
ရွှေ-
- d : dist() လုပ်ဆောင်ချက်ဖြင့် ယေဘုယျအားဖြင့် တွက်ချက်ထားသော အကွာအဝေး မက်ထရစ်။
- eig : eigenvalues ပြန်ပေးသည်ဖြစ်စေ မပြန်သည်ဖြစ်စေ။
- k : ဒေတာကြည့်ရှုရန် အတိုင်းအတာ အရေအတွက်။ မူရင်းက 2 ပါ။
အောက်ဖော်ပြပါ ဥပမာသည် ဤလုပ်ဆောင်ချက်ကို လက်တွေ့အသုံးချနည်းကို ပြသထားသည်။
ဥပမာ- R in Multidimensional Scaling
R တွင် ဘတ်စကက်ဘောကစားသမားများအကြောင်း အချက်အလက်များစွာပါရှိသော အောက်ပါဒေတာဘောင်ရှိသည်ဆိုပါစို့။
#create data frame df <- data. frame (points=c(4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28), assists=c(3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11), blocks=c(7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1), rebounds=c(4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2)) #add row names row. names (df) <- LETTERS[1:11] #view data frame df points assists blocks rebounds A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
cmdscale() လုပ်ဆောင်ချက်ဖြင့် ဘက်စုံစကေးချဲ့ရန်အတွက် အောက်ပါကုဒ်ကို သုံးနိုင်ပြီး ရလဒ်များကို 2D space တွင် မြင်ယောင်နိုင်သည်-
#calculate distance matrix
d <- dist(df)
#perform multidimensional scaling
fit <- cmdscale(d, eig= TRUE , k= 2 )
#extract (x, y) coordinates of multidimensional scaling
x <- fit$points[,1]
y <- fit$points[,2]
#create scatterplot
plot(x, y, xlab=" Coordinate 1 ", ylab=" Coordinate 2 ",
main=" Multidimensional Scaling Results ", type=" n ")
#add row names of data frame as labels
text(x, y, labels=row. names (df))
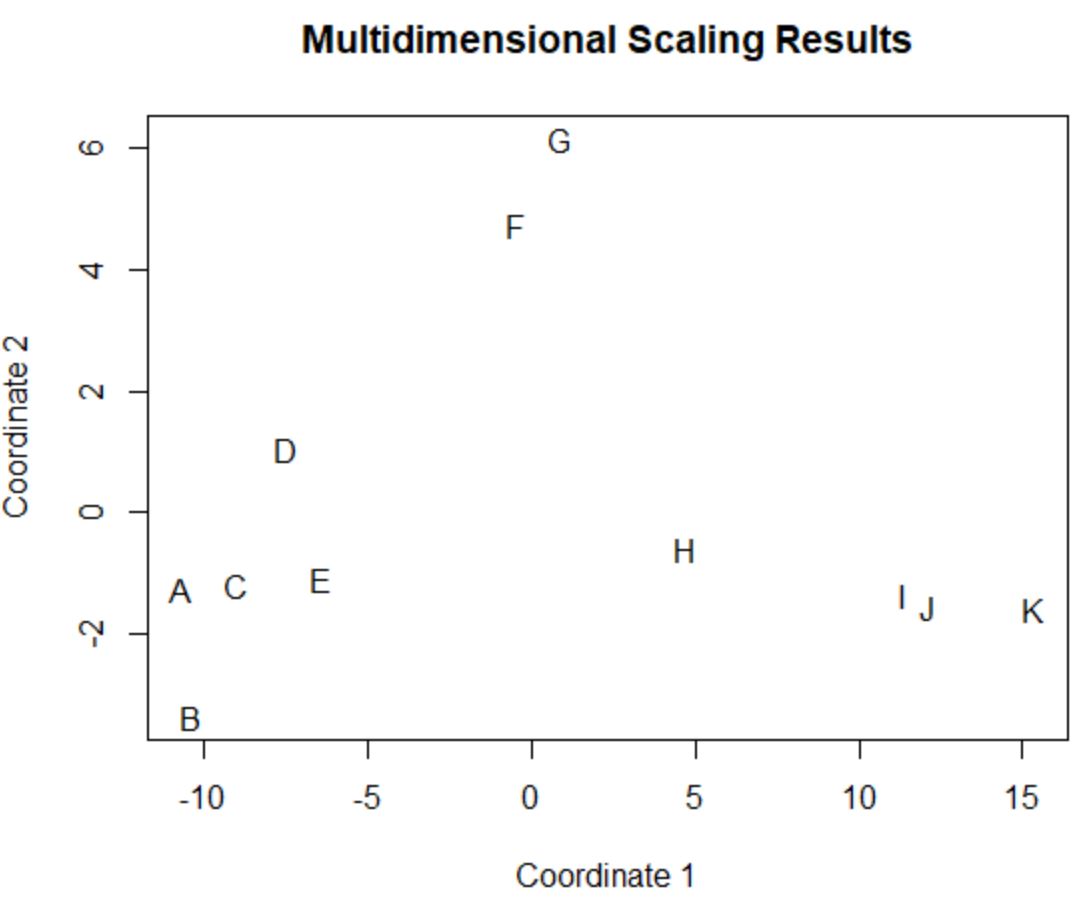
မူရင်းကော်လံလေးခုတွင် အလားတူတန်ဖိုးများရှိသည့် မူရင်းဒေတာဘောင်ရှိ ကစားသမားများ (points, assists, blocks, and rebounds) တို့သည် ဇာတ်ကွက်ထဲတွင် တစ်ခုနှင့်တစ်ခု နီးကပ်နေပါသည်။
ဥပမာအားဖြင့် ကစားသမား A နှင့် C သည် တစ်ခုနှင့်တစ်ခု ပိတ်ထားသည်။ ဤသည်မှာ မူရင်းဒေတာဘောင်မှ ၎င်းတို့၏တန်ဖိုးများဖြစ်သည်-
#view data frame values for players A and C df[rownames(df) %in% c(' A ', ' C '), ] points assists blocks rebounds A 4 3 7 4 C 6 2 6 5
အမှတ်များ၊ အကူအညီများ၊ လုပ်ကွက်များနှင့် ပြန်လှန်ခြင်းများအတွက် ၎င်းတို့၏တန်ဖိုးများသည် 2D ဇာတ်ကွက်တွင် အဘယ်ကြောင့် အလွန်နီးကပ်နေကြသည်ကို ရှင်းပြသည်။
ဆန့်ကျင်ဘက်အနေနှင့်၊ ဇာတ်ကွက်ထဲတွင် ဝေးကွာနေသော ကစားသမား B နှင့် K ကို ထည့်သွင်းစဉ်းစားပါ။
မူရင်းဒေတာတွင် ၎င်းတို့၏တန်ဖိုးများကို ကိုးကားပါက၊ ၎င်းတို့သည် အလွန်ကွဲပြားသည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်သည်-
#view data frame values for players B and K df[rownames(df) %in% c(' B ', ' K '), ] points assists blocks rebounds B 4 2 3 5 K 28 11 1 2
ထို့ကြောင့် 2D ဇာတ်ကွက်သည် ဒေတာဘောင်ရှိ ကိန်းရှင်အားလုံးတွင် ကစားသမားတစ်ဦးစီနှင့် မည်ကဲ့သို့ဆင်တူသည်ကို မြင်ယောင်ရန် နည်းလမ်းကောင်းတစ်ခုဖြစ်သည်။
တူညီသောကိန်းဂဏန်းများရှိသည့် ကစားသမားများကို ဇာတ်ကွက်ထဲတွင် ကွဲပြားသောကိန်းဂဏန်းများရှိသည့် ကစားသမားများသည် တစ်ဦးနှင့်တစ်ဦး ဝေးကွာနေချိန်တွင် အတူတကွ အုပ်စုဖွဲ့ထားသည်။
cmdscale() လုပ်ဆောင်ချက်၏ ရလဒ်များကို ကျွန်ုပ်တို့သိမ်းဆည်းထားသည့် variable ၏အမည်ဖြစ်သည့် fit ကို ရိုက်ထည့်ခြင်းဖြင့် ကွက်ကွက်အတွင်းရှိ ကစားသမားတစ်ဦးစီ၏ အတိအကျ သြဒိနိတ်များ (x, y) ကို ထုတ်ယူနိုင်သည်ကို သတိပြုပါ။
#view (x, y) coordinates of points in the plot
fit
[,1] [,2]
A -10.6617577 -1.2511291
B -10.3858237 -3.3450473
C -9.0330408 -1.1968116
D -7.4905743 1.0578445
E -6.4021114 -1.0743669
F -0.4618426 4.7392534
G 0.8850934 6.1460850
H 4.7352436 -0.6004609
I 11.3793381 -1.3563398
J 12.0844168 -1.5494108
K 15.3510585 -1.5696166
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် R တွင် အခြားဘုံအလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
R တွင်ဒေတာကိုပုံမှန်ဖြစ်အောင်လုပ်နည်း
R တွင်ဒေတာစင်တာကိုဘယ်လိုလုပ်မလဲ။
R တွင် outliers ကိုမည်သို့ဖယ်ရှားရမည်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။