A- လုပ်ဆောင်ချိန်ကို တိုင်းတာရန် microbenchmark ပက်ကေ့ဂျ်ကို အသုံးပြုနည်း
မတူညီသောအသုံးအနှုန်းများ၏ လုပ်ဆောင်ချိန်ကို နှိုင်းယှဉ်ရန် R တွင် microbenchmark ပက်ကေ့ခ်ျကို သင်အသုံးပြုနိုင်ပါသည်။
၎င်းကိုလုပ်ဆောင်ရန် အောက်ပါ syntax ကို သင်အသုံးပြုနိုင်သည်-
library (microbenchmark) #compare execution time of two different expressions microbenchmark( expression1, expression2) )
အောက်ဖော်ပြပါ ဥပမာသည် ဤ syntax ကို လက်တွေ့တွင် မည်သို့အသုံးပြုရမည်ကို ပြသထားသည်။
ဥပမာ- R တွင် microbenchmark() ကိုအသုံးပြုခြင်း။
ဘတ်စကက်ဘောအသင်းအသီးသီးရှိ ကစားသမားများမှ ရမှတ်များအကြောင်း အချက်အလက်များပါရှိသော R တွင် အောက်ပါဒေတာဘောင်တစ်ခုရှိသည် ဆိုပါစို့။
#make this example reproducible
set. seed ( 1 )
#create data frame
df <- data. frame (team=rep(c(' A ', ' B '), each= 500 ),
points=rnorm( 1000 , mean= 20 ))
#view data frame
head(df)
team points
1 A 19.37355
2 A 20.18364
3 A 19.16437
4 A 21.59528
5 A 20.32951
6 A 19.17953
ယခု ကျွန်ုပ်တို့သည် မတူညီသောနည်းလမ်းနှစ်ခုဖြင့် အသင်းတစ်ခုစီရှိ ကစားသမားများရရှိသော ပျမ်းမျှအမှတ်များကို တွက်ချက်လိုသည်ဆိုပါစို့။
- နည်းလမ်း 1 : Base R မှ Aggregate() ကို သုံးပါ။
- နည်းလမ်း 2- dplyr မှ group_by() နှင့် summarise_at() ကို သုံးပါ။
ဤအသုံးအနှုန်းတစ်ခုစီကို လုပ်ဆောင်ရန် လိုအပ်သည့်အချိန်ကို တိုင်းတာရန် microbenchmark() လုပ်ဆောင်ချက်ကို ကျွန်ုပ်တို့ အသုံးပြုနိုင်ပါသည်။
library (microbenchmark) library (dplyr) #time how long it takes to calculate mean value of points by team microbenchmark( aggregate(df$points, list(df$team), FUN=mean), df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) ) Unit: milliseconds express aggregate(df$points, list(df$team), FUN = mean) df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) min lq mean median uq max neval cld 1.307908 1.524078 1.852167 1.743568 2.093813 4.67408 100 a 6.788584 7.810932 9.946286 8.914692 10.239904 56.20928 100 b
microbenchmark() လုပ်ဆောင်ချက်သည် စကားရပ်တစ်ခုစီကို အကြိမ် 100 လုပ်ဆောင်ပြီး အောက်ပါ မက်ထရစ်များကို တိုင်းတာသည်-
- အနည်းဆုံး – အကောင်အထည်ဖော်ရန် အနည်းဆုံးအချိန်လိုအပ်သည်။
- lq : ပြီးမြောက်ရန် အချိန်၏အောက်ခြေ quartile (25th ရာခိုင်နှုန်း)
- ဆိုလိုသည်မှာ အကောင်အထည်ဖော်ရန် ပျမ်းမျှအချိန်လိုအပ်သည်။
- ပျမ်းမျှ : ပျမ်းမျှ ကွပ်မျက်ချိန်
- uq : အထက် quartile (75th percentile) ကို လုပ်ဆောင်ရန် လိုအပ်သည်။
- အမြင့်ဆုံး : အကောင်အထည်ဖော်ရန် အများဆုံးအချိန် လိုအပ်သည်။
- neval : စကားရပ်တစ်ခုစီကို အကဲဖြတ်သည့်အကြိမ်အရေအတွက်
ပုံမှန်အားဖြင့်၊ ကျွန်ုပ်တို့သည် စကားရပ်တစ်ခုစီကို လုပ်ဆောင်ရန် ပျမ်းမျှ သို့မဟုတ် ပျမ်းမျှအချိန်ကိုသာ ကြည့်ရှုသည်။
ရလဒ်မှ ကျွန်ုပ်တို့ မြင်နိုင်သည်-
- R-based နည်းလမ်းကို အသုံးပြု၍ အသင်းရမှတ်များကို ပျမ်းမျှတွက်ချက်ရန် ပျမ်းမျှအချိန် 1,852 မီလီစက္က န့် ကြာပါသည်။
- dplyr နည်းလမ်းကို အသုံးပြု၍ အဖွဲ့တစ်ဖွဲ့လျှင် ပျမ်းမျှအမှတ်များကို တွက်ချက်ရန် ပျမ်းမျှအချိန် 9.946 မီလီစက္က န့် ကြာသည်။
ဤရလဒ်များကို အခြေခံ၍ အခြေခံ R နည်းလမ်းသည် သိသိသာသာ ပိုမြန်သည်ဟု ကျွန်ုပ်တို့ ကောက်ချက်ချပါသည်။
စကားရပ်တစ်ခုစီကိုလုပ်ဆောင်ရန် လိုအပ်သောအချိန်များကို ဖြန့်ကျက်မြင်ယောင်ရန် boxplot() လုပ်ဆောင်ချက်ကိုလည်း အသုံးပြုနိုင်သည်။
library (microbenchmark) library (dplyr) #time how long it takes to calculate mean value of points by team results <- microbenchmark( aggregate(df$points, list(df$team), FUN=mean), df %>% group_by(team) %>% summarise_at(vars(points), list(name = mean)) ) #create boxplot to visualize results boxplot(results, names=c(' Base R ', ' dplyr '))
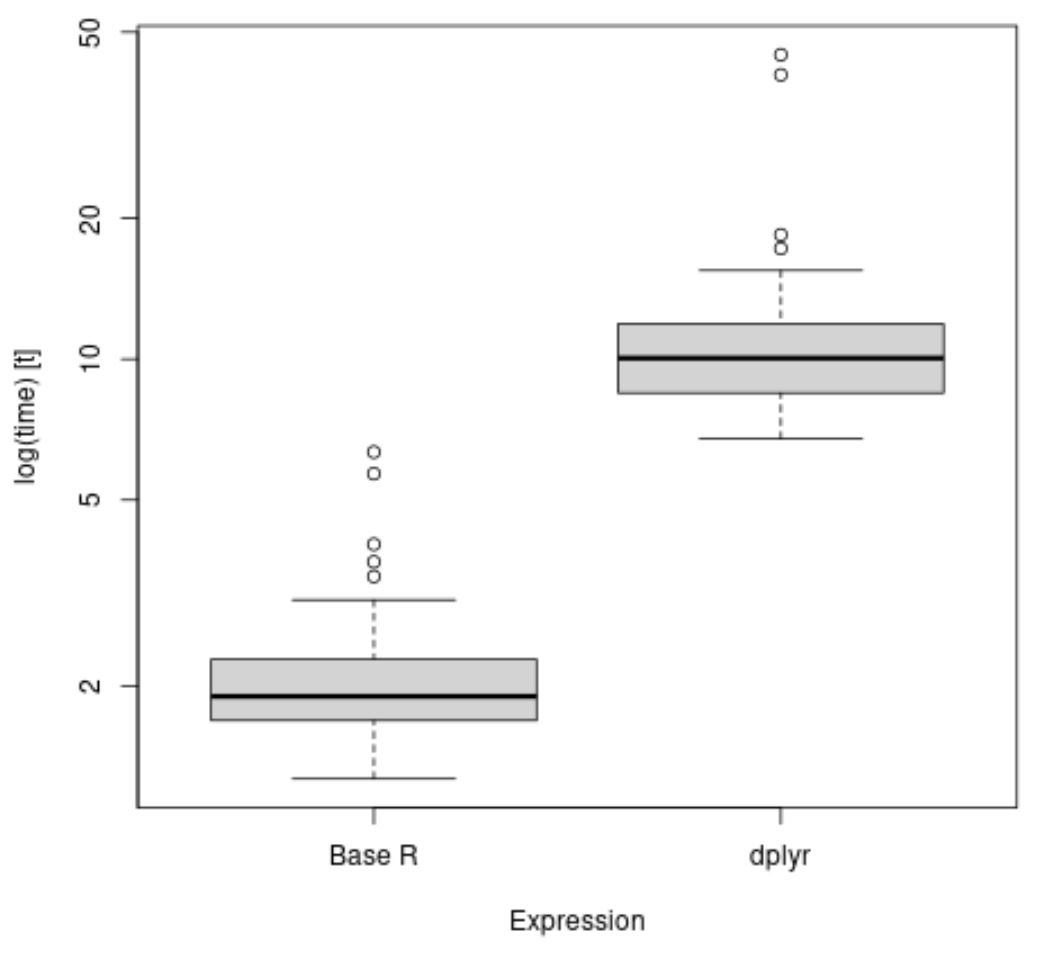
အကွက်ကွက်များမှ၊ အဖွဲ့တစ်ဖွဲ့လျှင် ပျမ်းမျှအမှတ်တန်ဖိုးကို တွက်ချက်ရန် dplyr နည်းလမ်းသည် ပျမ်းမျှပိုကြာကြောင်း ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။
မှတ်ချက် – ဤဥပမာတွင်၊ မတူညီသောအသုံးအနှုန်းနှစ်ခု၏ လုပ်ဆောင်ချိန်ကို နှိုင်းယှဉ်ရန် microbenchmark() လုပ်ဆောင်ချက်ကို ကျွန်ုပ်တို့အသုံးပြုခဲ့သည်၊ သို့သော် သင်သည် လက်တွေ့တွင် သင်အလိုရှိသော စကားရပ်များစွာကို နှိုင်းယှဉ်နိုင်သည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် R တွင် အခြားဘုံအလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
R တွင် ပတ်ဝန်းကျင်ကို မည်ကဲ့သို့ ရှင်းလင်းမည်နည်း။
RStudio ရှိ မြေကွက်များအားလုံးကို ရှင်းလင်းနည်း
R တွင် ပက်ကေ့ဂျ်များစွာကို မည်သို့တင်ရမည်နည်း။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။