R in diamond dataset အတွက် လမ်းညွှန်ချက်အပြည့်အစုံ
Diamond dataset သည် R ရှိ ggplot2 ပက်ကေ့ချ်တွင် တည်ဆောက်ထားသော ဒေတာအတွဲတစ်ခုဖြစ်သည်။
၎င်းတွင် မတူညီသော စိန်ပေါင်း 53,940 (စျေးနှုန်း၊ အရောင်၊ ကြည်လင်ပြတ်သားမှုစသည်) အတွက် မတူညီသော ကိန်းရှင် 10 ခုတွင် တိုင်းတာမှုများ ပါရှိသည်။
ဤသင်ခန်းစာတွင် R တွင် စိန် ဒေတာအတွဲကို စူးစမ်းရန်၊ အကျဉ်းချုပ်ပြီး မြင်ယောင်ပုံကို ရှင်းပြထားသည်။
စိန်ဒေတာအတွဲကို တင်ပါ။
Diamond dataset သည် ggplot2 တွင် built-in dataset တစ်ခုဖြစ်သောကြောင့်၊ ကျွန်ုပ်တို့သည် ပထမဦးစွာ install လုပ်ရန် (မဖြစ်သေးပါက) နှင့် ggplot2 ပက်ကေ့ဂျ်ကို တင်ရန် လိုအပ်သည်-
#install ggplot2 if not already installed
install. packages (' ggplot2 ')
#load ggplot2
library (ggplot2)
ကျွန်ုပ်တို့ ggplot2 ကို တင်ပြီးသည်နှင့်၊ စိန်ဒေ တာအတွဲကို တင်ရန် data() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်ပါသည်။
data(diamonds)
head() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ dataset ၏ ပထမခြောက်တန်းကို ကြည့်နိုင်သည်-
#view first six rows of diamonds dataset
head(diamonds)
carat cut color clarity depth table price xyz
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.290 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
စိန်ဒေတာအတွဲကို အကျဉ်းချုပ်ပါ။
dataset အတွင်းရှိ variable တစ်ခုစီကို လျင်မြန်စွာ အကျဉ်းချုပ်ရန် summary() function ကို အသုံးပြုနိုင်ပါသည်။
#summarize diamonds dataset
summary(diamonds)
carat cut color clarity depth
Min. :0.2000 Fair: 1610 D: 6775 SI1:13065 Min. :43.00
1st Qu.:0.4000 Good: 4906 E: 9797 VS2:12258 1st Qu.:61.00
Median: 0.7000 Very Good: 12082 F: 9542 SI2: 9194 Median: 61.80
Mean: 0.7979 Premium: 13791 G: 11292 VS1: 8171 Mean: 61.75
3rd Qu.:1.0400 Ideal:21551 H:8304 VVS2:5066 3rd Qu.:62.50
Max. :5.0100 I: 5422 VVS1: 3655 Max. :79.00
D: 2808 (Other): 2531
table price xyz Min. :43.00 Min. : 326 Min. : 0.000 Min. : 0.000 Min. : 0.000
1st Qu.: 56.00 1st Qu.: 950 1st Qu.: 4.710 1st Qu.: 4.720 1st Qu.: 2.910
Median: 57.00 Median: 2401 Median: 5.700 Median: 5.710 Median: 3.530
Mean: 57.46 Mean: 3933 Mean: 5.731 Mean: 5.735 Mean: 3.539
3rd Qu.: 59.00 3rd Qu.: 5324 3rd Qu.: 6.540 3rd Qu.: 6.540 3rd Qu.: 4.040
Max. :95.00 Max. :18823 Max. :10,740 Max. :58,900 Max. :31,800
ကိန်းဂဏန်းကိန်းရှင်တစ်ခုစီအတွက် အောက်ပါအချက်အလက်များကို ကျွန်ုပ်တို့ကြည့်ရှုနိုင်သည်-
- အနည်းဆုံး : အနိမ့်ဆုံးတန်ဖိုး။
- 1st Qu : ပထမ quartile ၏တန်ဖိုး (25th ရာခိုင်နှုန်း)။
- Median : ပျမ်းမျှတန်ဖိုး။
- ပျမ်းမျှ : ပျမ်းမျှတန်ဖိုး။
- 3rd Qu : တတိယ quartile (75th ရာခိုင်နှုန်း) ၏တန်ဖိုး။
- Max : အများဆုံးတန်ဖိုး။
ဒေတာအတွဲရှိ အမျိုးအစားအလိုက် ကိန်းရှင်များ (ဖြတ်တောက်ခြင်း၊ အရောင်နှင့် ကြည်လင်ပြတ်သားမှု) အတွက် တန်ဖိုးတစ်ခုစီ၏ ကြိမ်နှုန်းအရေအတွက်ကို ကျွန်ုပ်တို့တွေ့မြင်ရသည်။
ဥပမာအားဖြင့်၊ cut variable အတွက်၊
- မျှတ : ဤတန်ဖိုးသည် 1,610 ကြိမ် ပေါ်လာသည်။
- ကောင်း : ဤတန်ဖိုးသည် 4,906 ကြိမ် ပေါ်လာသည်။
- အလွန်ကောင်းသည် – ဤတန်ဖိုးသည် 12,082 ကြိမ်ပေါ်လာသည်။
- ပရီမီယံ : ဤတန်ဖိုးသည် 13,791 ကြိမ် ပေါ်လာသည်။
- စံပြ – ဤတန်ဖိုးသည် 21,551 ကြိမ် ပေါ်လာသည်။
အတန်းများနှင့် ကော်လံအရေအတွက်အရ ဒေတာအတွဲ၏အတိုင်းအတာများကို ရယူရန် dim() လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်သည်။
#display rows and columns
dim(diamonds)
[1] 53940 10
ဒေတာအတွဲတွင် အတန်းပေါင်း 53,940 နှင့် ကော်လံ 10 ခု ပါရှိသည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။
ဒေတာဘောင်၏ကော်လံအမည်များကိုပြသရန် names() လုပ်ဆောင်ချက်ကိုလည်း အသုံးပြုနိုင်ပါသည်။
#display column names
names(diamonds)
[1] "carat" "cut" "color" "clarity" "depth" "table" "price" "x"
[9] “y” “z”
Diamonds Dataset ကို မြင်ယောင်ကြည့်ပါ။
ဒေတာအတွဲ၏ တန်ဖိုးများကို မြင်ယောင်နိုင်ရန် ကွက်ကွက်များ ဖန်တီးနိုင်သည်။
ဥပမာအားဖြင့်၊ အချို့သော variable တစ်ခု၏တန်ဖိုးများဆိုင်ရာ histogram ကိုဖန်တီးရန် geom_histogram() function ကိုသုံးနိုင်သည်။
#create histogram of values for price
ggplot(data=diamonds, aes (x=price)) +
geom_histogram(fill=" steelblue ", color=" black ") +
ggtitle(" Histogram of Price Values ")
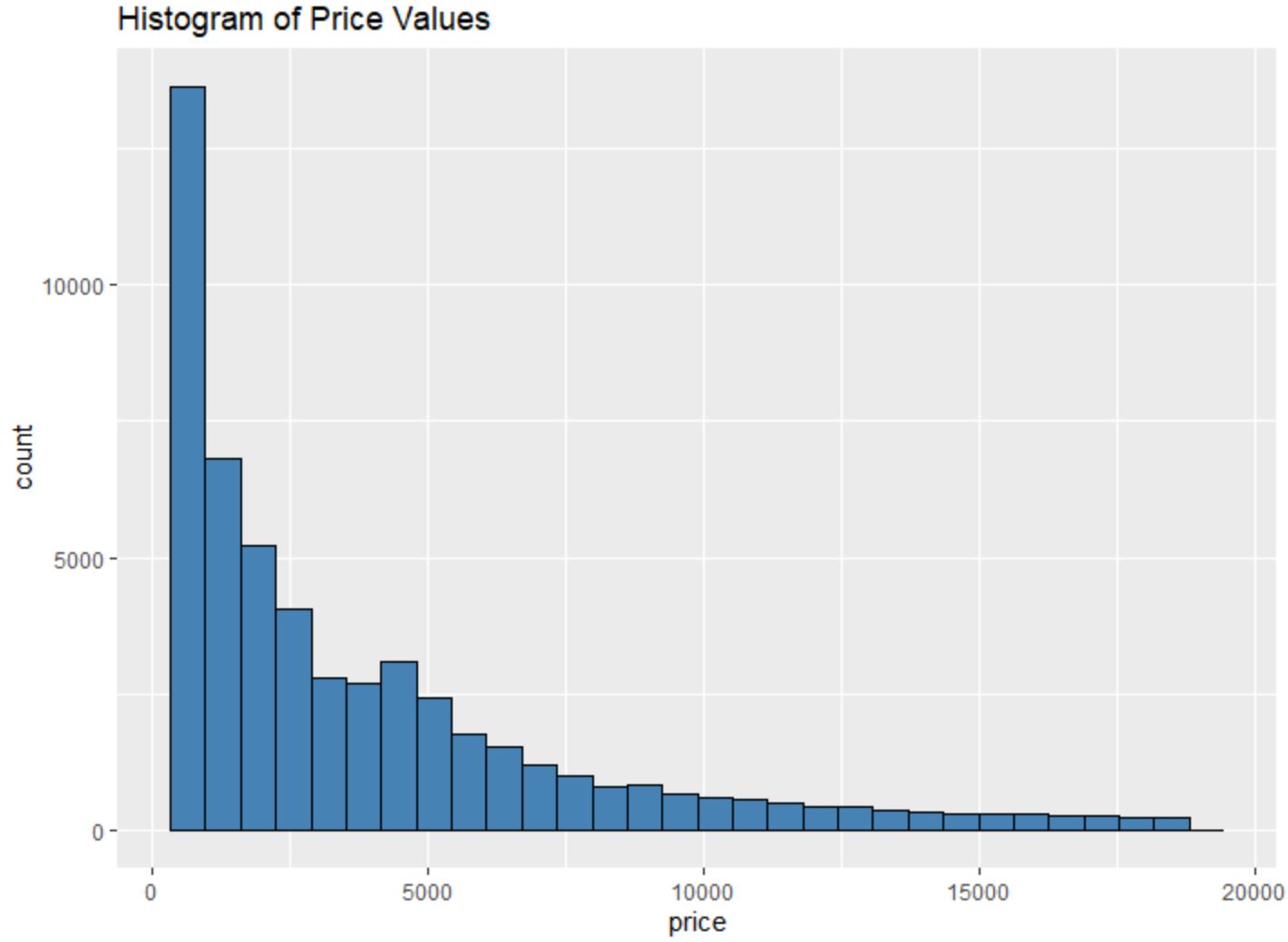
ကျွန်ုပ်တို့သည် မည်သည့်ကိန်းရှင်၏တွဲဆက်ပေါင်းစပ်မှု၏အမှတ်ကိုမဆိုဖန်တီးရန် geom_point() လုပ်ဆောင်ချက်ကိုလည်း အသုံးပြုနိုင်သည်။
#create scatterplot of carat vs. price, using cut as color variable
ggplot(data=diamonds, aes (x=carat, y=price, color=cut)) +
geom_point()
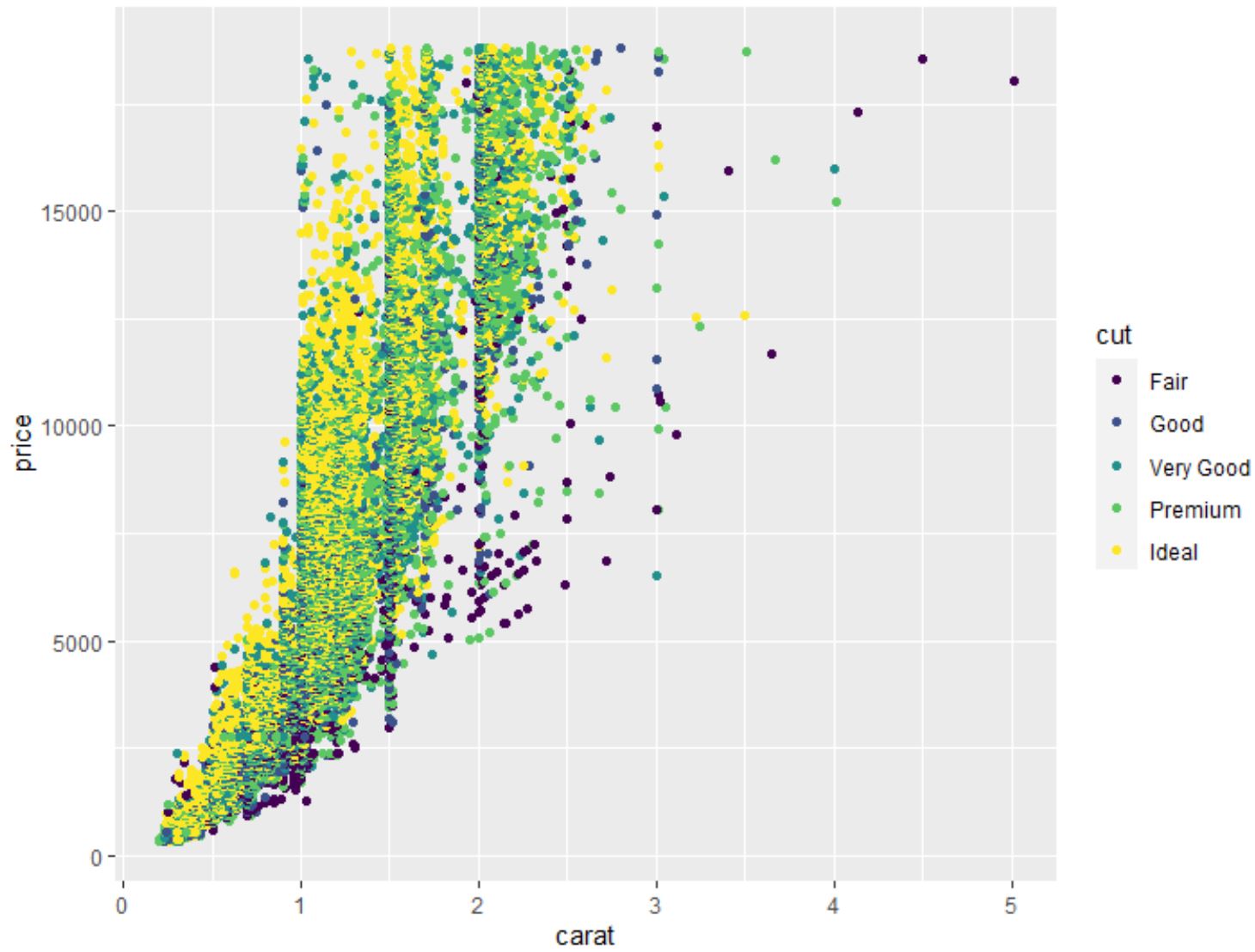
အခြားသော variable ဖြင့် အုပ်စုဖွဲ့ထားသော variable ၏ boxplot တစ်ခုကို ဖန်တီးရန် geom_boxplot() လုပ်ဆောင်ချက်ကိုလည်း အသုံးပြုနိုင်သည်။
#create scatterplot of price, grouped by cut
ggplot(data=diamonds, aes (x=cut, y=price)) +
geom_boxplot(fill=" steelblue ")
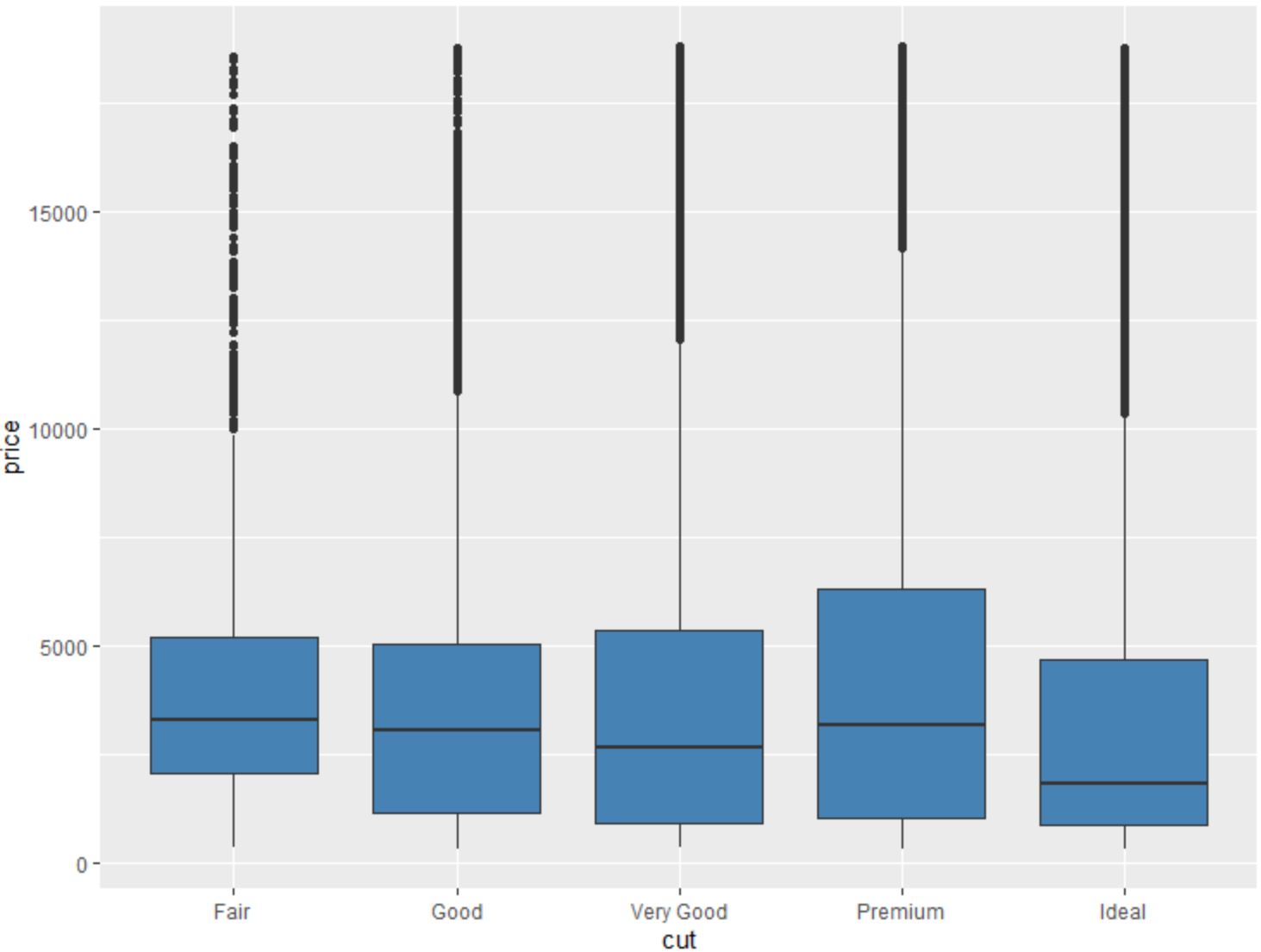
ဤ ggplot2 လုပ်ဆောင်ချက်များကိုအသုံးပြုခြင်းဖြင့် Diamond dataset အတွင်းရှိ variable များအကြောင်း များစွာလေ့လာနိုင်ပါသည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် R တွင် အခြားဒေတာအတွဲများကို ရှာဖွေနည်းကို ရှင်းပြသည်-
R in the Iris Dataset အတွက် လမ်းညွှန်ချက်အပြည့်အစုံ
R ရှိ mtcars ဒေတာအစုံအတွက် လမ်းညွှန်ချက်အပြည့်အစုံ
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။