R တွင် ဒေတာကို အလယ်ဗဟိုပြုနည်း (ဥပမာများဖြင့်)
ဒေတာအစုံကို ဗဟိုပြုခြင်း ဆိုသည်မှာ ဒေတာအစုအတွင်း တစ်ဦးချင်းစီ ကြည့်ရှုမှုတစ်ခုစီ၏ ပျမ်းမျှတန်ဖိုးကို နုတ်ယူခြင်းဖြစ်သည်။
ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့တွင် အောက်ပါဒေတာအစုံရှိသည်ဆိုပါစို့။
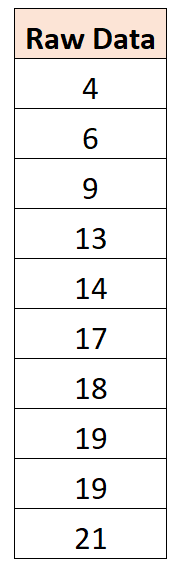
ပျမ်းမျှတန်ဖိုးသည် 14 ဖြစ်ကြောင်း တွေ့ရှိရပါသည်။ ထို့ကြောင့်၊ ဤဒေတာအတွဲကို ဗဟိုပြုရန်၊ တစ်ဦးချင်းစီ ရှုမြင်ချက်တစ်ခုစီမှ 14 ကို နုတ်ယူပါမည်-
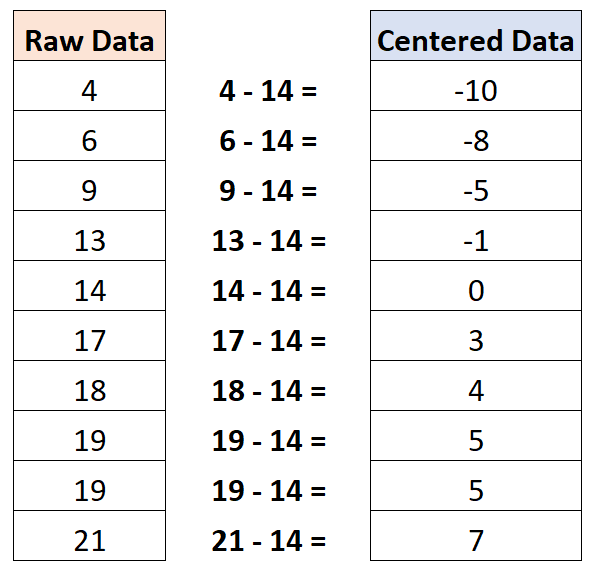
ဗဟိုပြုဒေတာအတွဲ၏ ပျမ်းမျှတန်ဖိုးသည် သုညဖြစ်ကြောင်း သတိပြုပါ။
ဤကျူတိုရီရယ်တွင် R တွင်ဒေတာကိုဗဟိုပြုပုံဥပမာများစွာကိုပေးသည်။
ဥပမာ 1: vector တစ်ခု၏ တန်ဖိုးများကို ဗဟိုပြုပါ။
အောက်ဖော်ပြပါ ကုဒ်သည် vector တစ်ခုရှိ တန်ဖိုးများကို ဗဟိုပြုရန်အတွက် base R scale() လုပ်ဆောင်ချက်ကို မည်သို့အသုံးပြုရမည်ကို ပြသသည်-
#createvector data <- c(4, 6, 9, 13, 14, 17, 18, 19, 19, 21) #subtract the mean value from each observation in the vector scale(data, scale= FALSE ) [,1] [1,] -10 [2,] -8 [3,] -5 [4,] -1 [5,] 0 [6,] 3 [7,] 4 [8,] 5 [9,] 5 [10,] 7 attr(,"scaled:center") [1] 14
ရလဒ်တန်ဖိုးများသည် dataset ၏ဗဟိုချက်တန်ဖိုးများဖြစ်သည်။ scale() function သည် dataset ၏ပျမ်းမျှတန်ဖိုးသည် 14 ဖြစ်သည်ကိုပြောပြသည်။
ပုံမှန်အားဖြင့် စကေး() လုပ်ဆောင်ချက်သည် တစ်ဦးချင်းစီ စူးစမ်းလေ့လာမှုတစ်ခုစီမှ ဆိုလိုချက်ကို နုတ်ပြီး စံသွေဖည်မှုဖြင့် ပိုင်းခြားကြောင်း သတိပြုပါ။
scale=FALSE ကို သတ်မှတ်ခြင်းဖြင့် ကျွန်ုပ်တို့ R ကို စံသွေဖည်မှုဖြင့် မခွဲရန် ပြောပါသည်။
ဥပမာ 2- ဒေတာဘောင်ရှိ ကော်လံများကို အလယ်ဗဟို
အောက်ပါကုဒ်သည် ဒေတာဘောင်တစ်ခုစီ၏ ကော်လံတစ်ခုစီ၏ တန်ဖိုးများကို ဗဟိုပြုရန် sapply() လုပ်ဆောင်ချက်နှင့် R ဒေတာဘေ့စ်၏ Scale() လုပ်ဆောင်ချက်ကို ပြသသည်-
#create data frame df <- data.frame(x = c(1, 4, 5, 6, 6, 8, 9), y = c(7, 7, 8, 8, 8, 9, 12), z = c(3, 3, 4, 4, 6, 7, 7)) #center each column in the data frame df_new <- sapply(df, function (x) scale(x, scale= FALSE )) #display data frame df_new X Y Z [1,] -4.5714286 -1.4285714 -1.8571429 [2,] -1.5714286 -1.4285714 -1.8571429 [3,] -0.5714286 -0.4285714 -0.8571429 [4,] 0.4285714 -0.4285714 -0.8571429 [5,] 0.4285714 -0.4285714 1.1428571 [6,] 2.4285714 0.5714286 2.1428571 [7,] 3.4285714 3.5714286 2.1428571
colMeans() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ ဒေတာဘောင်အသစ်ရှိ ကော်လံတစ်ခုစီ၏ ပျမ်းမျှအား သုညဖြစ်ကြောင်း စစ်ဆေးနိုင်သည်-
colMeans(df_new)
xyz 2.537653e-16 -2.537653e-16 3.806479e-16
တန်ဖိုးများကို သိပ္ပံနည်းကျမှတ်စုတွင် ပြထားသော်လည်း တန်ဖိုးတစ်ခုစီသည် မရှိမဖြစ်အားဖြင့် သုညဖြစ်သည်။
ထပ်လောင်းအရင်းအမြစ်များ
R တွင် ကော်လံများထက် ပျမ်းမျှနည်း
R တွင် သီးခြားကော်လံများကို ပေါင်းနည်း
R ရှိ ကော်လံများစွာမှ အစွန်းများကို ဖယ်ရှားနည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။