Sas တွင် shapiro-wilk စမ်းသပ်မှုပြုလုပ်နည်း
Shapiro-Wilk စမ်းသပ်မှုအား ဒေတာအစုံသည် ပုံမှန်ဖြန့်ဝေမှု နောက်သို့လိုက်ခြင်း ရှိ၊ မရှိ ဆုံးဖြတ်ရန် အသုံးပြုပါသည်။
အောက်ဖော်ပြပါ အဆင့်ဆင့် ဥပမာသည် SAS တွင် ဒေတာအစုံအတွက် Shapiro-Wilk စမ်းသပ်နည်းကို ပြသသည်။
အဆင့် 1: ဒေတာကိုဖန်တီးပါ။
ပထမဦးစွာ ကျွန်ုပ်တို့သည် လေ့လာတွေ့ရှိချက် 15 ခုပါဝင်သော ဒေတာအတွဲတစ်ခုကို ဖန်တီးပါမည်။
/*create dataset*/ data my_data; input x; datalines ; 3 3 4 6 7 8 8 9 12 14 15 15 17 20 21 ; run ; /*view dataset*/ proc print data =my_data;
အဆင့် 2: Shapiro-Wilk စမ်းသပ်မှုကို လုပ်ဆောင်ပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် Shapiro-Wilk ပုံမှန်စစ်ဆေးမှုကိုလုပ်ဆောင်ရန် ပုံမှန် command ဖြင့် proc univariate ကို အသုံးပြုပါမည်။
/*perform Shapiro-Wilk test*/ proc univariate data =my_data normal ; run ;
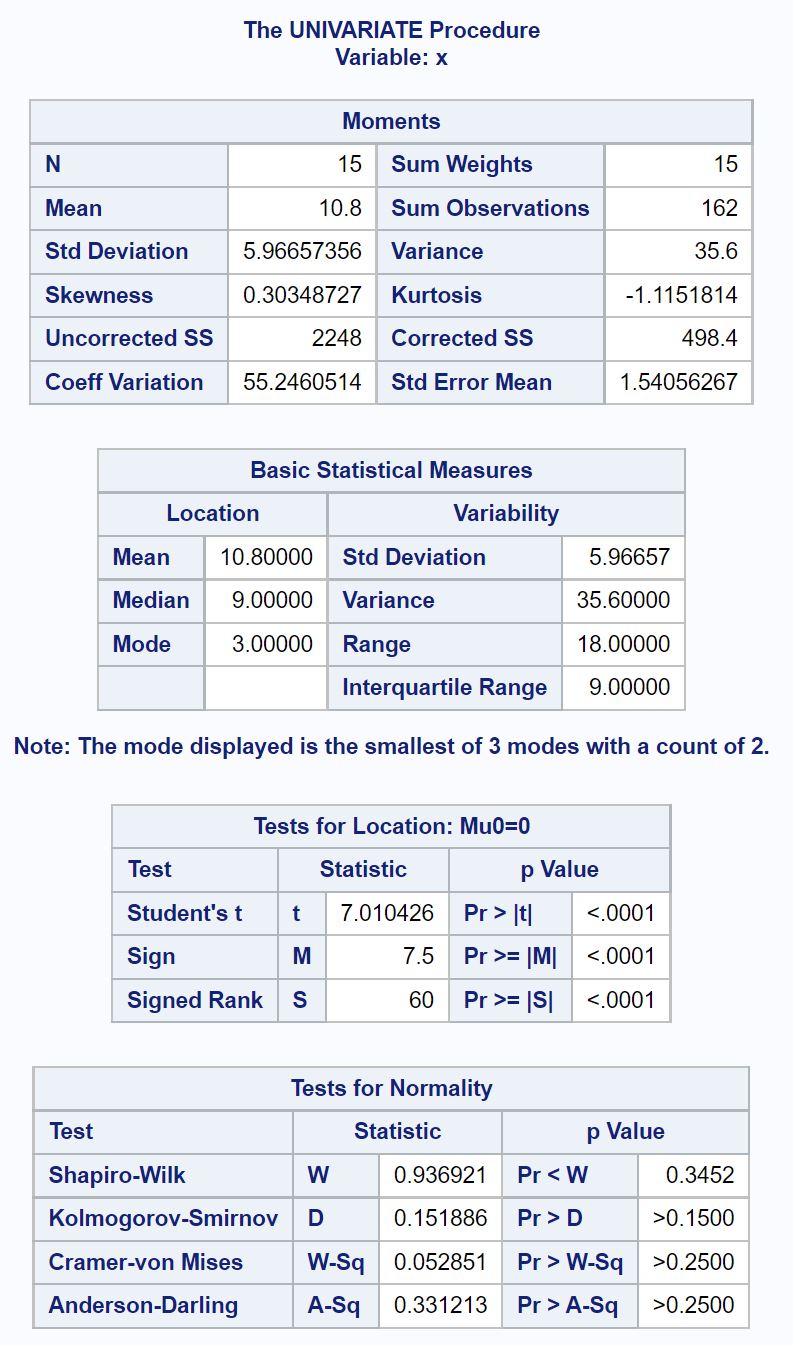
ရလဒ်သည် ကျွန်ုပ်တို့အား သတင်းအချက်အလက်များစွာပေးသည်၊ သို့သော် ကျွန်ုပ်တို့ကြည့်ရှုရန်လိုအပ်သည့်တစ်ခုတည်းသောဇယားမှာ Normality Tests ဟုခေါ်သည်။
ဤဇယားသည် အပါအဝင် ပုံမှန်ပုံမှန်စစ်ဆေးမှုများစွာအတွက် စမ်းသပ်စာရင်းအင်းများနှင့် p-တန်ဖိုးများကို ပံ့ပိုးပေးသည်-
- Shapiro-Wilk စမ်းသပ်မှု
- Kolmogorov-Smirnov စမ်းသပ်မှု
- Cramer-von Mises စမ်းသပ်မှု
- Anderson-Darling စမ်းသပ်မှု
ဤဇယားမှ Shapiro-Wilk စမ်းသပ်မှုအတွက် p-တန်ဖိုးသည် 0.3452 ဖြစ်သည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။
Shapiro-Wilk စမ်းသပ်မှုတွင် အောက်ပါ null နှင့် အခြားအခြားသော အယူအဆများကို အသုံးပြုကြောင်း သတိရပါ။
- H 0 : ဒေတာကို ပုံမှန်အတိုင်း ဖြန့်ဝေသည်။
- H A : ဒေတာကို ပုံမှန်ဖြန့်ဝေခြင်း မဟုတ်ပါ ။
p-value ( .3452 ) သည် 0.05 ထက်မနည်းသောကြောင့်၊ null hypothesis ကို ငြင်းပယ်ရန် ပျက်ကွက်ပါသည်။
ဆိုလိုသည်မှာ ဒေတာအတွဲကို ပုံမှန်အတိုင်း ဖြန့်ဝေခြင်းမဟုတ်ဟု ပြောရန် လုံလောက်သော အထောက်အထား မရှိဟု ဆိုလိုပါသည်။
တစ်နည်းဆိုရသော် Dataset အား ပုံမှန်ဖြန့်ဝေသည်ဟု ယူဆနိုင်ပါသည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် SAS တွင် အခြားသော ဘုံကိန်းဂဏန်းစစ်ဆေးမှုများကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
SAS တွင် Kolmogorov-Smirnov စမ်းသပ်မှုပြုလုပ်နည်း
SAS တွင် chi-square goodness-of-fit test ကို မည်သို့လုပ်ဆောင်ရမည်နည်း။
SAS တွင် Fisher ၏တိကျသောစမ်းသပ်မှုပြုလုပ်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။