Sas တွင် indexc လုပ်ဆောင်ချက်ကိုအသုံးပြုနည်း
SAS တွင် INDEXC လုပ်ဆောင်ချက်ကို သင်အသုံးပြု၍ စာကြောင်းတစ်ခုရှိ ဇာတ်ကောင်တစ်ဦးချင်းစီ၏ ပထမဆုံးဖြစ်ပေါ်မှု အနေအထားကို ပြန်ပေးနိုင်သည်။
ဤလုပ်ဆောင်ချက်သည် အောက်ပါအခြေခံ syntax ကိုအသုံးပြုသည်-
INDEXC(အရင်းအမြစ်၊ ထုတ်ယူခြင်း)
ရွှေ-
- အရင်းအမြစ် : ခွဲခြမ်းစိတ်ဖြာရန် ချန်နယ်
- ထုတ်ယူခြင်း – အရင်းအမြစ် တွင် ရှာဖွေရန် စာလုံးစာကြောင်း
အောက်ဖော်ပြပါ ဥပမာသည် ဤလုပ်ဆောင်ချက်ကို လက်တွေ့အသုံးချနည်းကို ပြသထားသည်။
ဥပမာ- SAS တွင် INDEXC လုပ်ဆောင်ချက်ကို အသုံးပြုခြင်း။
ကျွန်ုပ်တို့တွင် အမည်များကော်လံတစ်ခုပါရှိသော SAS တွင် အောက်ပါဒေတာအစုံရှိသည် ဆိုကြပါစို့။
/*create dataset*/
data original_data;
input name $25.;
datalines ;
Andy Lincoln Bernard
Michael Smith
Chad Simpson Arnolds
Derrick Smith Henrys
Eric Millerton Smith
Frank Giovanni Goode
;
run ;
/*view dataset*/
proc print data = original_data;
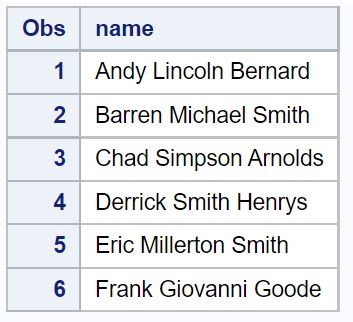
ကျွန်ုပ်တို့သည် စာလုံး x , y သို့မဟုတ် z တို့၏ ပထမဆုံးဖြစ်ပေါ်မှု အနေအထားကို ရှာဖွေရန် INDEXC လုပ်ဆောင်ချက်ကို အသုံးပြုနိုင်သည်။
/*find position of first occurrence of either x, y or z in name*/
data new_data;
set original_data;
first_xyz = indexc (name, 'xyz');
run ;
/*view results*/
proc print data = new_data;
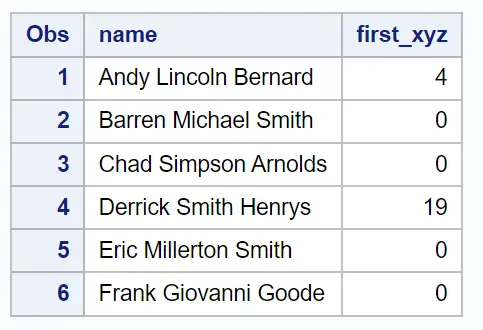
first_xyz ဟုခေါ်သော ကော်လံအသစ်သည် အမည် ကော်လံတွင် စာလုံး x , y , သို့မဟုတ် z တို့၏ ပထမဆုံးပေါ်ပေါက်သည့် အနေအထားကို ပြသသည်။
အကယ်၍ ဤအက္ခရာသုံးလုံးမှ အမည် ကော်လံတွင် မပါဝင်ပါက၊ INDEXC လုပ်ဆောင်ချက်သည် 0 တန်ဖိုးကို ရိုးရိုးပြန်ပေးသည်။
ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့မြင်နိုင်သည်-
ပထမတန်းရှိ x၊ y သို့မဟုတ် z ၏ပထမဆုံးဖြစ်ပျက်မှုအနေအထားသည် အနေအထား 4 ဖြစ်သည်။ ပထမစာကြောင်းရှိ position 4 တွင်ရှိသော ဇာတ်ကောင်သည် a y ဖြစ်ကြောင်း ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။
ဒုတိယအတန်းရှိ x၊ y သို့မဟုတ် z ၏ ပထမတန်း၏ အနေအထားသည် 0 ဖြစ်သောကြောင့် ဒုတိယအတန်းအမည်တွင် ဤစာလုံးသုံးလုံးမျှမရှိပါ။
နောက် … ပြီးတော့။
INDEX နှင့် INDEXC လုပ်ဆောင်ချက်များအကြား ကွာခြားချက်
SAS ရှိ INDEX လုပ်ဆောင်ချက်သည် အခြား string တစ်ခုရှိ သီးခြားစာတန်းခွဲတစ်ခု၏ ပထမဆုံးဖြစ်ပေါ်မှု အနေအထားကို ပြန်ပေးသည်။
အောက်ဖော်ပြပါ ဥပမာသည် INDEX နှင့် INDEXC လုပ်ဆောင်ချက်များကြား ခြားနားချက်ကို ဖော်ပြသည်-
/*create new dataset*/
data new_data;
set original_data;
index_smith = index (name, 'Smith');
indexc_smith = indexc (name, 'Smith');
run ;
/*view new dataset*/
proc print data =new_data;
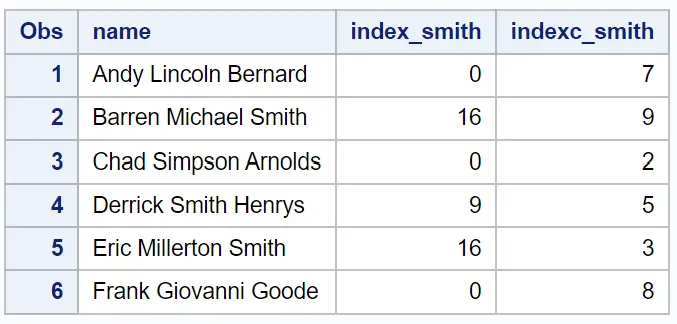
index_smith ကော်လံသည် အမည် ကော်လံတွင် ‘Smith’ ၏ ‘စမစ်’ စာကြောင်းခွဲ၏ ပထမဆုံး ပေါ်ပေါက်သည့် အနေအထားကို ပြသသည်။
indexc_smith ကော်လံသည် အမည် ကော်လံတွင် s , m , i , t , သို့မဟုတ် h စာလုံးများ၏ ပထမဆုံးပေါ်ပေါက်သည့် အနေအထားကို ပြသသည်။
ဥပမာအားဖြင့်၊ ကျွန်ုပ်တို့မြင်နိုင်သည်-
စာတန်းခွဲ ‘Smith’ သည် ပထမအမည်တွင် ဘယ်တော့မှ မပေါ်သောကြောင့် index_smith သည် 0 တန်ဖိုးကို ပြန်ပေးသည်။
ပထမအမည်၏ 7th အနေအထားတွင် i စာလုံးသည် indexc_smith မှ 7 တန်ဖိုးကို ပြန်ပေးသည်။
နောက် … ပြီးတော့။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် SAS တွင် အခြားသော အသုံးများသော လုပ်ဆောင်ချက်များကို အသုံးပြုနည်းကို ရှင်းပြသည်-
SAS တွင် SUBSTR လုပ်ဆောင်ချက်ကိုအသုံးပြုနည်း
SAS တွင် COMPRESS လုပ်ဆောင်ချက်ကို မည်သို့အသုံးပြုရမည်နည်း။
SAS တွင် FIND လုပ်ဆောင်ချက်ကိုအသုံးပြုနည်း
SAS တွင် COALESCE လုပ်ဆောင်ချက်ကိုအသုံးပြုနည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။