Sas တွင် proc cluster ကိုအသုံးပြုနည်း (ဥပမာနှင့်အတူ)
Clustering သည် ဒေတာအတွဲတစ်ခုအတွင်း လေ့လာတွေ့ရှိချက် အုပ်စုများကို ရှာဖွေရန် ကြိုးစားသည့် စက်သင်ယူမှုနည်းပညာတစ်ခုဖြစ်သည်။
ရည်ရွယ်ချက်မှာ အစုအဝေးတစ်ခုစီအတွင်းရှိ ရှုမြင်သုံးသပ်ချက်များသည် တစ်ခုနှင့်တစ်ခု အလွန်တူညီပြီး ကွဲပြားသောအစုအဝေးရှိ လေ့လာတွေ့ရှိချက်များသည် တစ်ခုနှင့်တစ်ခု အလွန်ကွာခြားသည့် အစုအဝေးများကို ရှာဖွေရန်ဖြစ်သည်။
SAS တွင် အစုအဝေးပြုလုပ်ရန် အလွယ်ကူဆုံးနည်းလမ်းမှာ PROC CLUSTER ကို အသုံးပြုရန်ဖြစ်သည်။
အောက်ဖော်ပြပါ ဥပမာသည် PROC CLUSTER ကို လက်တွေ့တွင် အသုံးပြုနည်းကို ပြသထားသည်။
ဥပမာ- SAS တွင် PROC CLUSTER ကိုအသုံးပြုနည်း
မတူညီသော ဘတ်စကက်ဘောကစားသမား 20 အတွက် အမှတ်များ၊ ပံ့ပိုးမှုများနှင့် ပြန်အထွက်များဆိုင်ရာ အချက်အလက်များပါရှိသော အောက်ပါဒေတာအစုံရှိသည် ဆိုကြပါစို့။
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
တစ်ခုနှင့်တစ်ခုတူညီသောကိန်းဂဏန်းများရှိသောကစားသမားများ၏ “ အစုအဝေးများ” ကိုခွဲခြားသတ်မှတ်ရန်ကြိုးစားရန်အုပ်စုအချို့ပြုလုပ်လိုသည်ဆိုကြပါစို့။
အောက်ပါကုဒ်သည် အစုအဝေးပြုလုပ်ရန်အတွက် SAS တွင် PROC CLUSTER ကို အသုံးပြုပုံကို ပြသသည်-
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
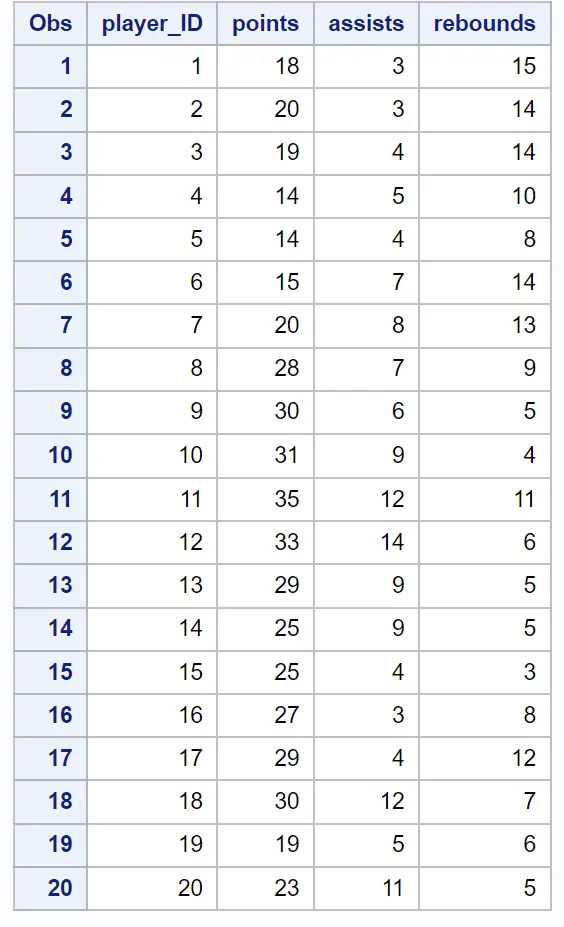
ရလဒ်၏ပထမဇယားများသည် အစုအဝေးပြုလုပ်ပုံနှင့်ပတ်သက်၍ အချက်အလက်များကို ပေးဆောင်သည်-
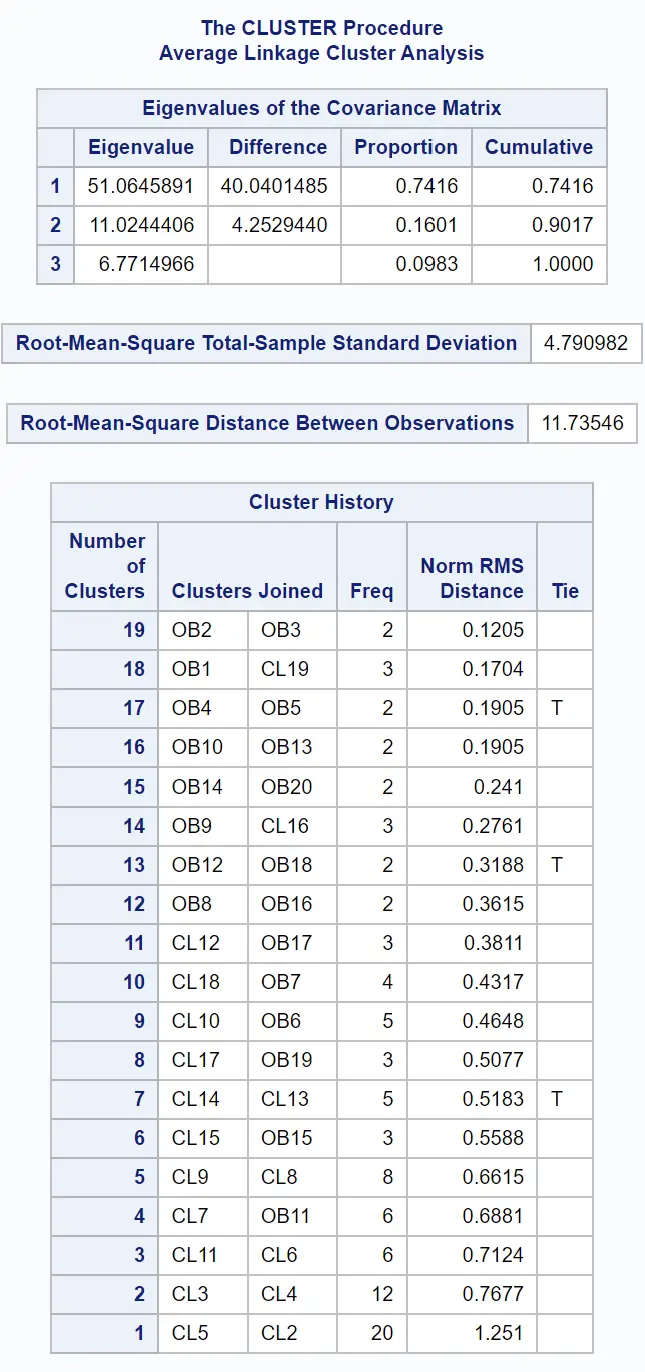
ဒေတာအတွဲရှိ စူးစမ်းမှုများကြားရှိ တူညီမှုကို မြင်သာမြင်သာစွာ စစ်ဆေးနိုင်ရန် dendrogram တစ်ခုကိုလည်း ထုတ်လုပ်ထားပါသည်။
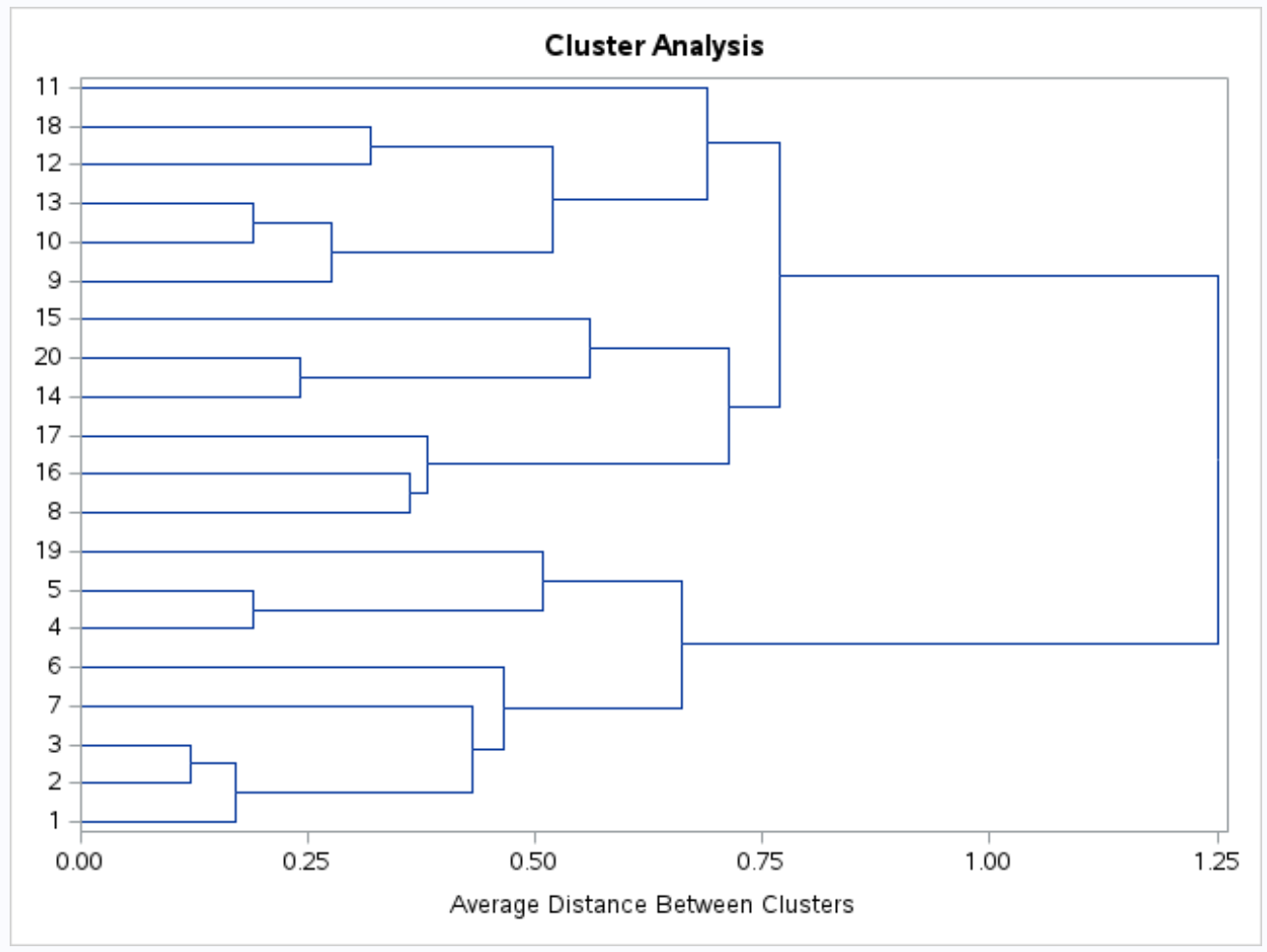
y-axis သည် တစ်ဦးချင်းစီ စောင့်ကြည့်မှုများကို ပြသပြီး x-axis သည် အစုအဖွဲ့များကြား ပျမ်းမျှအကွာအဝေးကို ပြသသည်။
ဤ denrogram ကိုကြည့်လျှင် လေ့လာတွေ့ရှိချက်များကို သဘာဝအတိုင်း အုပ်စုသုံးစုခွဲထားပုံရသည်။
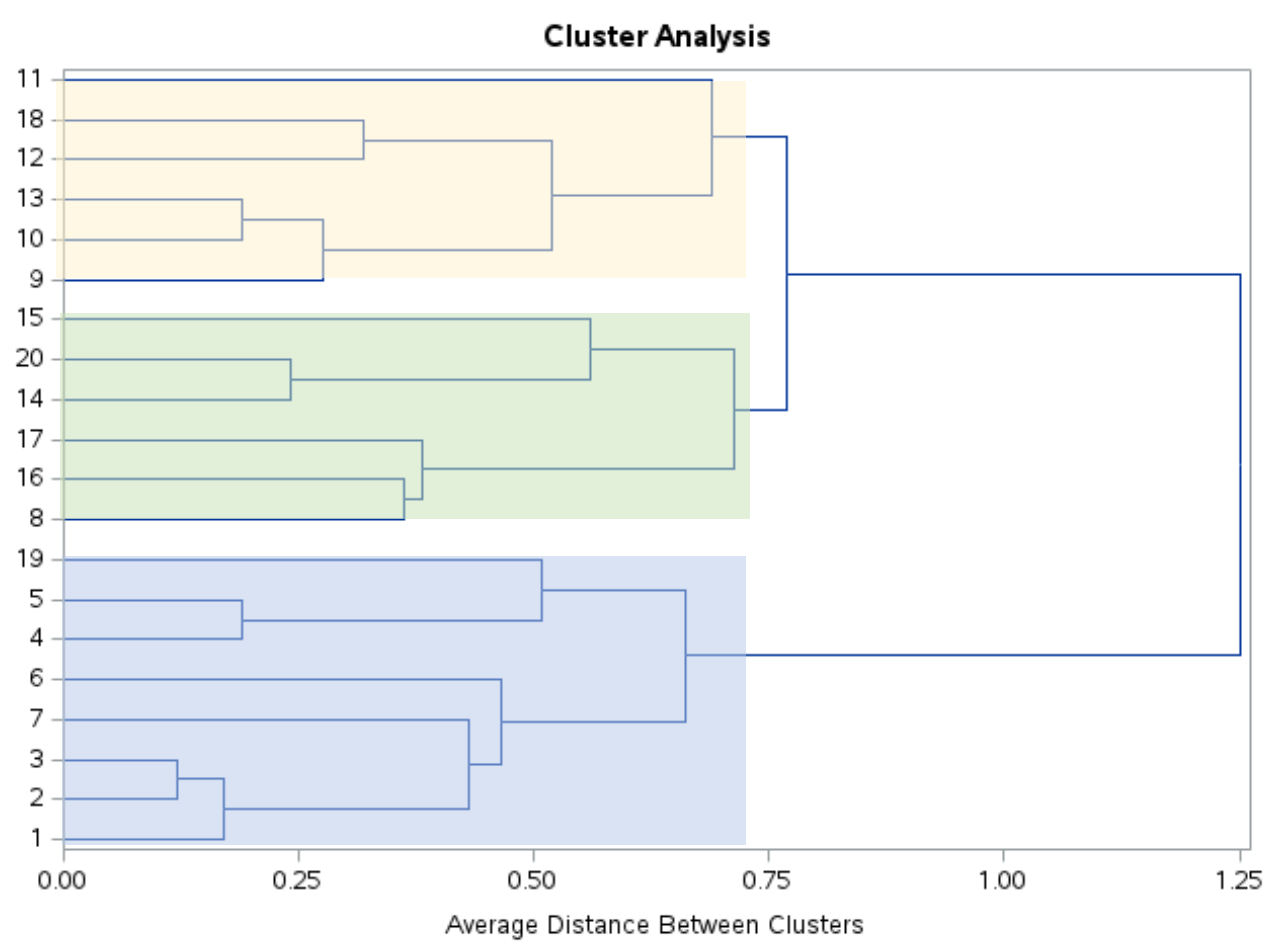
ထို့နောက် ကျွန်ုပ်တို့သည် PROC TREE ကြေညာချက်ကို ncl=3 ဖြင့် အသုံးပြု၍ မူရင်းဒေတာအတွဲတွင် လေ့လာမှုတစ်ခုစီကို အစုသုံးခုအနက်မှတစ်ခုသို့ သတ်မှတ်ရန် SAS ကို ပြောပြနိုင်သည်-
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
ရလဒ်ဒေတာအတွဲသည် ၎င်းတို့ပိုင်ဆိုင်သည့် အစုအဝေးနှင့်အတူ မူလလေ့လာတွေ့ရှိချက်တစ်ခုစီကို ပြသသည်-
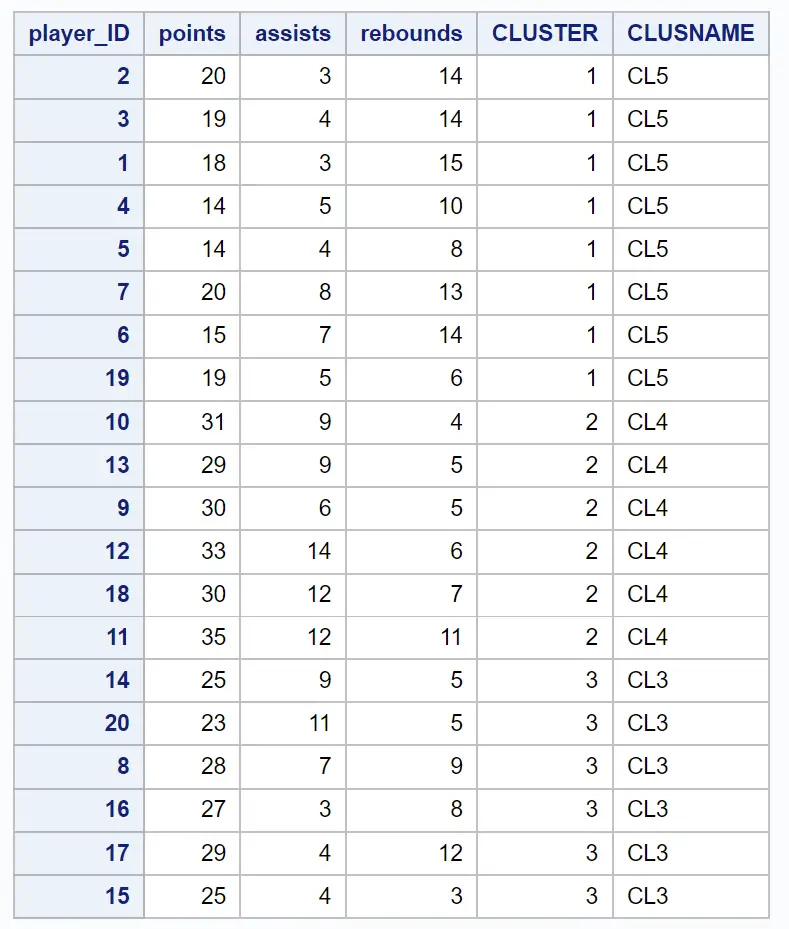
ဥပမာအားဖြင့်၊ IDs 2၊ 3၊ 1၊ 4၊ 5၊ 7၊ 6 နှင့် 19 ရှိသော ကစားသမားများအားလုံးသည် cluster 1 နှင့် သက်ဆိုင်ပါသည်။
၎င်းသည် ဤကစားသမားရှစ်ဦးသည် အမှတ်များ၊ ပံ့ပိုးမှုများနှင့် ပြန်လှန်ပေးသည့်ကိန်းရှင်များတွင် “ ဆင်တူသည်” ဖြစ်သည်ဟု ကျွန်ုပ်တို့ကိုပြောပြသည်။
မှတ်ချက် – ဤဥပမာအတွက်၊ အစုလိုက်ဖွဲ့ခြင်းအတွက် ပျမ်းမျှအား ချိတ်ဆက်ခြင်းနည်းလမ်းအဖြစ် ကျွန်ုပ်တို့ရွေးချယ်ခဲ့သည်။ သင်အသုံးပြုနိုင်သော အခြားစည်းနှောင်မှုနည်းလမ်းများ စာရင်းအပြည့်အစုံအတွက် SAS စာရွက်စာတမ်း ကို ကိုးကားပါ။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် SAS တွင် အခြားဘုံအလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
SAS တွင် Principal Component Analysis ကို မည်သို့လုပ်ဆောင်ရမည်နည်း
SAS တွင် မျဉ်းကြောင်းပြန်ဆုတ်ခြင်းများစွာကို မည်သို့လုပ်ဆောင်ရမည်နည်း။
SAS တွင် logistic regression ကိုမည်သို့လုပ်ဆောင်ရမည်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။