Sas- find နှင့် index အကြား ကွာခြားချက်
SAS ရှိ FIND နှင့် INDEX လုပ်ဆောင်ချက်များကို အသုံးပြု၍ စာကြောင်းတစ်ခုအတွင်း ပေါ်လာသည့် စာကြောင်းခွဲတစ်ခု၏ ပထမဇာတ်ကောင်၏ အနေအထားကို ပြန်ပေးနိုင်သည်။
ဤလုပ်ဆောင်ချက်များကြား ခြားနားချက်မှာ FIND လုပ်ဆောင်ချက်သည် သင့်အား INDEX လုပ်ဆောင်ချက် မလုပ်ဆောင်နိုင်သည့် အရာနှစ်ခုကို လုပ်ဆောင်နိုင်စေခြင်းဖြစ်သည်-
- FIND သည် သင့်အား case-insensitive ရှာဖွေမှုကို လုပ်ဆောင်နိုင်စေပါသည်။
- FIND သည် ရှာဖွေမှုအတွက် စတင်သည့် အနေအထားကို သတ်မှတ်နိုင်စေပါသည်။
အောက်ဖော်ပြပါ ဥပမာများသည် စာကြောင်းကော်လံပါရှိသော SAS တွင် အောက်ပါဒေတာအစုံဖြင့် လက်တွေ့တွင် FIND နှင့် INDEX လုပ်ဆောင်ချက်များကြား ကွာခြားချက်ကို သရုပ်ဖော်သည် –
/*create dataset*/
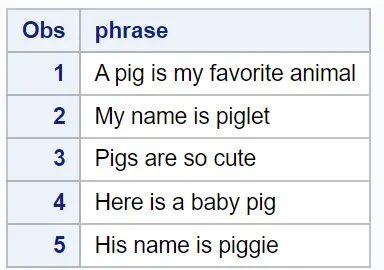
data original_data;
input sentence $40. ;
datalines ;
A pig is my favorite animal
My name is piglet
Pigs are so cute
Here is a baby pig
His name is piggy
;
run ;
/*view dataset*/
proc print data = original_data;
ဥပမာ 1- ကွဲပြားမှုမရှိဘဲ FIND နှင့် INDEX ကို အသုံးပြုခြင်း။
ဖော်ပြပါ ကော်လံရှိ စာကြောင်းခွဲ “ ဝက်” ၏ ပထမဆုံးဖြစ်ပေါ်မှုအနေအထားကို ရှာဖွေရန် FIND နှင့် INDEX လုပ်ဆောင်ချက်များကို အောက်ပါကုဒ်တွင် ဖော်ပြသည်-
/*find position of first occurrence of 'pig' in phrase column*/
data new_data;
set original_data;
find_pig = find (phrase, 'pig');
index_pig = index (phrase, 'pig');
run ;
/*view results*/
proc print data = new_data;

FIND နှင့် INDEX လုပ်ဆောင်ချက်များသည် အတိအကျတူညီသောရလဒ်များပြန်လာသည်ကို သတိပြုပါ။
find_pig နှင့် index_pig ကော်လံများ စကားစု ကော်လံရှိ စာကြောင်းခွဲ “ ဝက်” ၏ ပထမဆုံး ဖြစ်ပေါ်မှု အနေအထားကို ပြသပါ။
ဥပမာ 2- FIND နှင့် INDEX ကို case-sensitive ရှာဖွေမှုဖြင့် အသုံးပြုခြင်း။
ဖော်ပြပါ ကော်လံရှိ စကားလုံး “ PIG” ၏ ပထမဆုံးပေါ်ပေါက်သည့် အနေအထားကို ရှာဖွေရန် FIND နှင့် INDEX လုပ်ဆောင်ချက်များကို အောက်ပါကုဒ်တွင် ဖော်ပြသည်-
/*find position of first occurrence of 'PIG' in phrase column*/
data new_data;
set original_data;
find_pig = find (phrase, 'PIG', 'i');
index_pig = index (phrase, 'PIG');
run ;
/*view results*/
proc print data =new_data;

FIND လုပ်ဆောင်ချက်ရှိ “ i” ပြုပြင်မွမ်းမံမှုကို အသုံးပြု၍ စကားစုကော်လံရှိ “ PIG” စာကြောင်းခွဲအတွက် ဖြစ်ရပ်မှန်-အာရုံမခံသော ရှာဖွေမှုကို လုပ်ဆောင်နိုင်ခဲ့သည်။
သို့ရာတွင်၊ INDEX လုပ်ဆောင်ချက်သည် စာလုံးအသေး-အာရုံမခံသောရှာဖွေမှုကို မလုပ်ဆောင်နိုင်သောကြောင့် စာလုံးအကြီးအသေးခွဲ “ PIG” သည် မည်သည့်ဝါကျ၌မျှ မရှိသောကြောင့် အတန်းတစ်ခုစီအတွက် 0 ကို ရိုးရိုးရှင်းရှင်း ပြန်ပေးသည်။
ဥပမာ 3- FIND နှင့် INDEX ကို သီးခြားစတင်သည့်အနေအထားဖြင့် အသုံးပြုခြင်း။
INDEX လုပ်ဆောင်ချက် သည် သတ်သတ်မှတ်မှတ် စတင်သည့်အနေအထားကို လုံးဝအသုံးမပြုနိုင်သော်လည်း ရာထူး 5 မှ စတင်သည့် စကားစု ကော်လံရှိ စာကြောင်းခွဲ “ ဝက်” ကို ရှာဖွေရန် အောက်ပါကုဒ်သည် FIND လုပ်ဆောင်ချက်ကို မည်သို့အသုံးပြုရမည်ကို ပြသသည် –
/*find position of first occurrence of 'pig' in phrase column starting at position 5*/
data new_data;
set original_data;
find_pig = find (phrase, 'pig', 5 );
index_pig = index (phrase, 'pig');
run ;
/*view results*/
proc print data = new_data;

find_pig လုပ်ဆောင်ချက်သည် စာပိုဒ်တို ကော်လံ၏ ရာထူး 5 မှ စတင်သည့် ‘ဝက်’ စာသားခွဲကို ရှာဖွေသည်။
index_pig လုပ်ဆောင်ချက်သည် ရှာဖွေမှုအတွက် စတင်သည့် အနေအထားကို မသတ်မှတ်နိုင်သောကြောင့် စကားစု ကော်လံရှိ မည်သည့်နေရာတွင်မဆို “ ဝက်” စာကြောင်းခွဲကို ရိုးရှင်းစွာ ရှာဖွေသည်။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် SAS တွင် အခြားသော အသုံးများသော လုပ်ဆောင်ချက်များကို အသုံးပြုနည်းကို ရှင်းပြသည်-
SAS တွင် SUBSTR လုပ်ဆောင်ချက်ကိုအသုံးပြုနည်း
SAS တွင် COMPRESS လုပ်ဆောင်ချက်ကို မည်သို့အသုံးပြုရမည်နည်း။
SAS တွင် COALESCE လုပ်ဆောင်ချက်ကိုအသုံးပြုနည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။