အတည်ပြုသတ်မှတ်မှုနှင့် စမ်းသပ်မှုအစုံ- ကွာခြားချက်ကား အဘယ်နည်း။
ကျွန်ုပ်တို့သည် စက်သင်ယူမှု အယ်လဂိုရီသမ်ကို ဒေတာအတွဲတစ်ခုသို့ လိုက်လျောညီထွေဖြစ်စေသည့်အခါတိုင်း၊ ကျွန်ုပ်တို့သည် ပုံမှန်အားဖြင့် ဒေတာအတွဲကို သုံးပိုင်းခွဲသည်-
1. Training set : မော်ဒယ်ကို လေ့ကျင့်ရန် အသုံးပြုသည်။
2. Validation set : မော်ဒယ်ဘောင်များကို ပိုမိုကောင်းမွန်အောင်ပြုလုပ်ရန် အသုံးပြုသည်။
3. စမ်းသပ်မှုအစုံ – နောက်ဆုံးမော်ဒယ်စွမ်းဆောင်ရည်ကို ဘက်မလိုက်ဘဲ ခန့်မှန်းချက်ရယူရန် အသုံးပြုသည်။
အောက်ဖော်ပြပါ ပုံကြမ်းသည် ဤမတူညီသော ဒေတာအတွဲသုံးမျိုး၏ အမြင်ဆိုင်ရာ ရှင်းလင်းချက်ကို ပေးသည်-
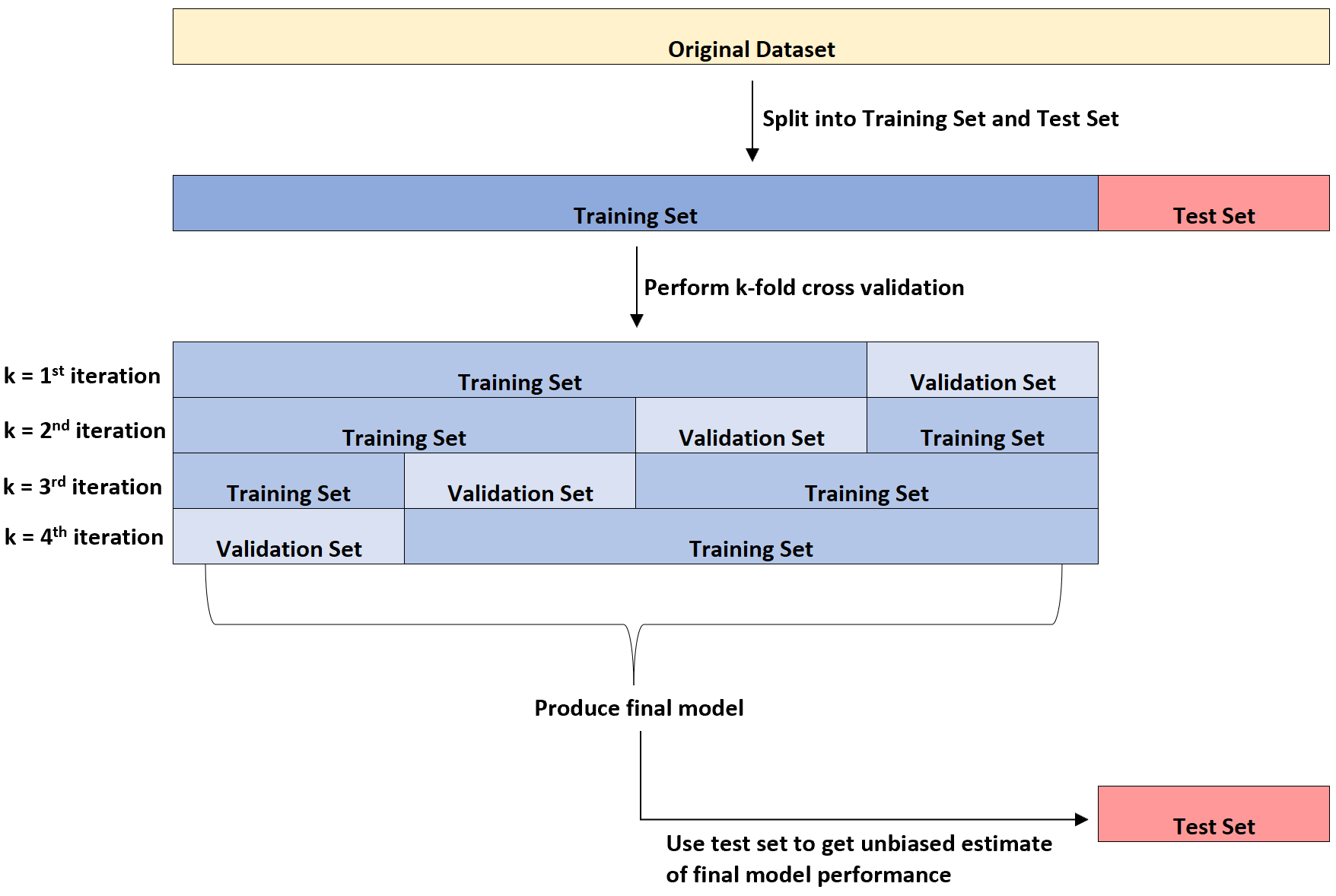
ကျောင်းသားများအတွက် စိတ်ရှုပ်ထွေးစရာအချက်တစ်ခုမှာ အတည်ပြုချက်သတ်မှတ်မှုနှင့် စာမေးပွဲသတ်မှတ်ကြား ကွာခြားချက်ဖြစ်သည်။
ရိုးရှင်းစွာပြောရလျှင်၊ နောက်ဆုံးမော်ဒယ်၏ ဘက်မလိုက်သော ခန့်မှန်းချက်ကို ပေးဆောင်ရန် စမ်းသပ်မှု အစုံကို အသုံးပြုထားသော်လည်း မော်ဒယ်ဘောင်များကို ပိုမိုကောင်းမွန်အောင်ပြုလုပ်ရန် မှန်ကန်ကြောင်းသတ်မှတ်ခြင်းကို အသုံးပြုပါသည်။
k-fold cross-validation ဖြင့်တိုင်းတာသည့် error rate သည် model ကို မမြင်ရသော dataset တစ်ခုသို့အသုံးချပြီးသည်နှင့် real error rate ကို လျှော့တွက်တတ်ကြောင်း ပြသနိုင်သည်။
ထို့ကြောင့်၊ ကျွန်ုပ်တို့သည် လက်တွေ့ကမ္ဘာတွင် အမှားအယွင်းနှုန်းအမှန်ဖြစ်မည်ကို ဘက်မလိုက်ဘဲ ခန့်မှန်းချက်ရယူရန် နောက်ဆုံးပုံစံကို စမ်းသပ်သတ်မှတ်ထား ရန် ကိုက်ညီပါသည်။
အောက်ဖော်ပြပါ ဥပမာသည် သက်သေပြချက်တစ်ခုနှင့် လက်တွေ့စမ်းသပ်မှုတစ်ခုကြား ခြားနားချက်ကို ဖော်ပြသည်။
ဥပမာ- validation set နှင့် test set အကြား ခြားနားချက်ကို နားလည်ခြင်း။
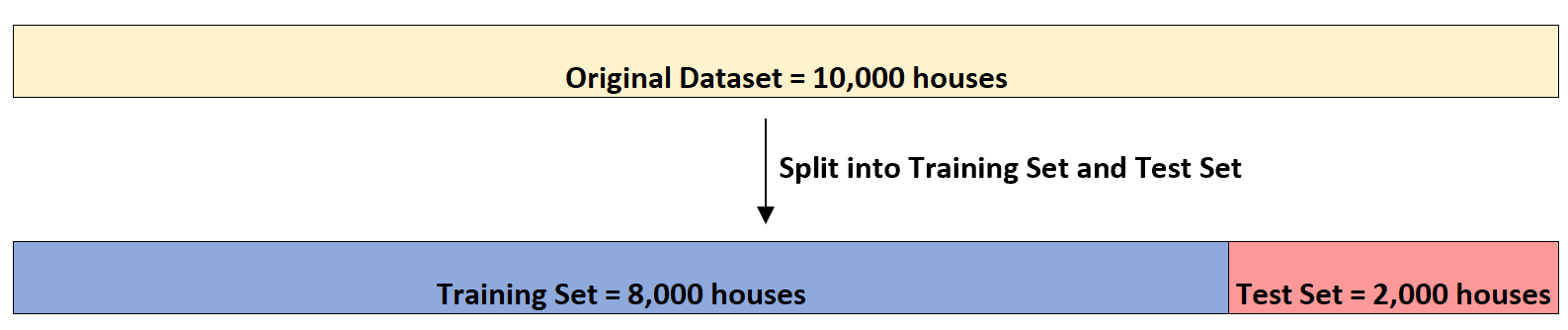
အိမ်ခြံမြေရင်းနှီးမြှုပ်နှံသူတစ်ဦးသည် (၁) အိပ်ခန်းအရေအတွက်၊ (၂) စုစုပေါင်းစတုရန်းပေနှင့် ရေချိုးခန်းအရေအတွက် (၃) ကို အသုံးပြုလိုသည်ဆိုပါစို့၊ ပေးထားသည့်အိမ်၏အရောင်းစျေးနှုန်းကို ခန့်မှန်းရန်။
အိမ် 10,000 တွင် ဤအချက်အလက်ပါသော ဒေတာအစုံရှိသည် ဆိုကြပါစို့။ ပထမဦးစွာ၊ ၎င်းသည် ဒေတာအစုံကို အိမ် ၈၀၀၀ ၏ လေ့ကျင့်ရေးအစုတစ်ခုနှင့် အိမ်ခြေ ၂၀၀၀ ၏ စမ်းသပ်မှုအစုအဖြစ် ခွဲသွားမည်ဖြစ်သည်။
ထို့နောက် ၎င်းသည် ဒေတာသတ်မှတ်မှုတွင် လေးကြိမ်ခန့် ထပ်တူထပ်မျှသော ဆုတ်ယုတ်မှုပုံစံကို အံဝင်ခွင်ကျဖြစ်စေမည်ဖြစ်သည်။ သင်တန်းအတွက် အိမ်ခြေ ၆,၀၀၀ နှင့် တစ်ကြိမ်စီအတွက် တရားဝင်သတ်မှတ်ထားသည့် အိမ်ခြေ ၂,၀၀၀ ကို အသုံးပြုမည်ဖြစ်သည်။
k-fold cross validation ဟုခေါ်သည်။
လေ့ကျင့်ရေး အစုံကို မော်ဒယ်လေ့ကျင့်ရန် အသုံးပြုပြီး မော်ဒယ်၏ စွမ်းဆောင်ရည်ကို အကဲဖြတ်ရန် မှန်ကန်ကြောင်း အတည်ပြုသတ်မှတ်ကို အသုံးပြုပါသည်။ တရားဝင်သတ်မှတ်မှုအတွက် တစ်ကြိမ်လျှင် အိမ် 2,000 ၏ မတူညီသောအုပ်စုတစ်စုကို အသုံးပြုမည်ဖြစ်သည်။
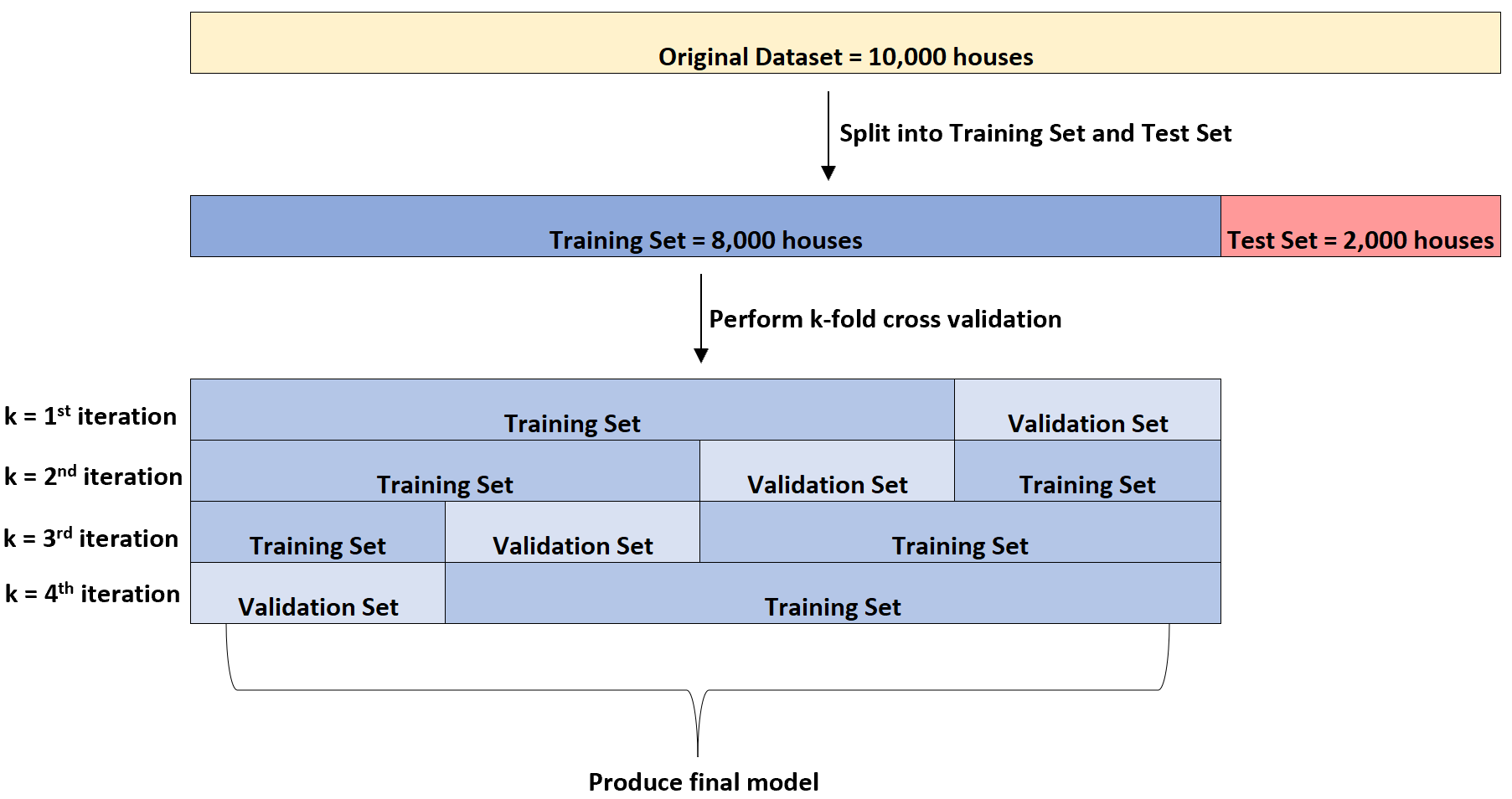
၎င်းသည် အနိမ့်ဆုံး အမှားအယွင်းရှိသည့် မော်ဒယ်ကို ခွဲခြားသတ်မှတ်ရန် ကွဲပြားသော ဆုတ်ယုတ်မှု မော်ဒယ်များစွာတွင် ဤ k-fold အပြန်အလှန် validation ကို လုပ်ဆောင်နိုင်သည်။
အကောင်းဆုံးမော်ဒယ်ကို ဖော်ထုတ်ပြီးသည်နှင့်သာ ၎င်းသည် မော်ဒယ်၏နောက်ဆုံးစွမ်းဆောင်ရည်ကို ဘက်မလိုက်ဘဲ ဘက်မလိုက်ဘဲ ခန့်မှန်းချက်ရရန် အစပိုင်းတွင် တင်ပြထားသည့် အိမ်စမ်းသပ်မှု 2,000 ကို အသုံးပြုမည်ဖြစ်သည်။
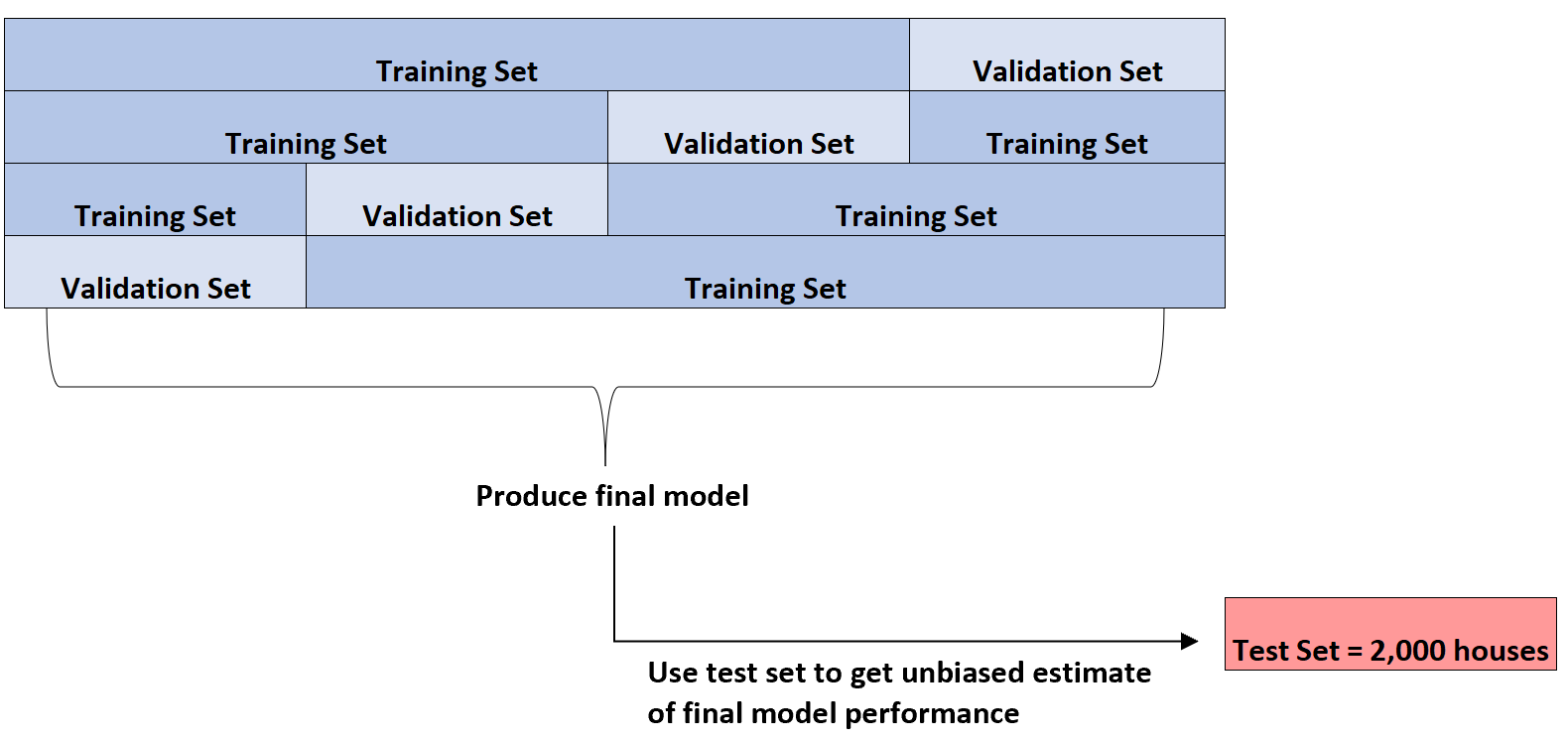
ဥပမာအားဖြင့်၊ အကြွင်းမဲ့အမှားမှာ 8.345 ဖြစ်ပြီး ဆိုလိုရင်းမှာ တိကျသောဆုတ်ယုတ်မှုပုံစံကို ခွဲခြားသတ်မှတ်နိုင်သည်။ ဆိုလိုသည်မှာ ခန့်မှန်းထားသည့် အိမ်ရာစျေးနှုန်းနှင့် အမှန်တကယ်အိမ်ရာစျေးနှုန်းကြား ပျမ်းမျှ ပကတိ ကွာခြားချက်မှာ $8,345 ဖြစ်သည်။
ထို့နောက် ၎င်းသည် အသုံးမပြုရသေးသော အိမ် 2,000 ၏ စမ်းသပ်မှုအစုတွင် ဤအတိအကျ ဆုတ်ယုတ်မှုပုံစံကို အံဝင်ခွင်ကျဖြစ်စေနိုင်ပြီး မော်ဒယ်၏ ပျမ်းမျှပကတိအမှားမှာ 8.847 ဖြစ်ကြောင်း တွေ့ရှိနိုင်သည်။
ထို့ကြောင့်၊ မော်ဒယ်၏ စစ်မှန်သော ဆိုလိုရင်းအကြွင်းမဲ့ မှားယွင်းမှု၏ ဘက်မလိုက်သော ခန့်မှန်းချက်မှာ $8,847 ဖြစ်သည်။
ထပ်လောင်းအရင်းအမြစ်များ
K-Fold Cross-Validation အတွက် ရိုးရှင်းသောလမ်းညွှန်
Python တွင် K-Fold အပြန်အလှန် validation လုပ်ဆောင်နည်း
R တွင် K-Fold အပြန်အလှန်တရားဝင်စစ်ဆေးနည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။