Python တွင် တူညီသောကြိမ်နှုန်း binning
စာရင်းဇယားများတွင် အုပ်စုဖွဲ့ခြင်းသည် ကိန်းဂဏာန်းတန်ဖိုးများကို အုပ်စုများ အဖြစ် သတ်မှတ်ခြင်းလုပ်ငန်းစဉ်ဖြစ်သည်။
အစုအဝေး၏အသုံးအများဆုံးပုံစံကို တူညီသောအနံရှိသောအစုအဝေးများ ဟုခေါ်သည်၊ ယင်းတွင် ကျွန်ုပ်တို့သတ်မှတ်ထားသောဒေတာကို အညီအမျှအကျယ်ရှိသော k အုပ်စုများအဖြစ် ပိုင်းခြားသည်။
အသုံးနည်းသော အစုအဝေးပုံစံကို ကြိမ်နှုန်းညီမျှသော ကြိမ်နှုန်းအစုအဝေး ဟု ခေါ်သည်၊ ယင်းတွင် ကျွန်ုပ်တို့သည် သတ်မှတ်ထားသော ဒေတာကို ကြိမ်နှုန်းများစွာရှိသည့် k အုပ်စုများအဖြစ် ပိုင်းခြားထားသည်။
ဤသင်ခန်းစာတွင် python တွင် တူညီသောကြိမ်နှုန်းအစုအဝေးကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြထားသည်။
Python တွင် တူညီသောကြိမ်နှုန်း Binning
ကျွန်ုပ်တို့တွင် တန်ဖိုး 100 ပါသော ဒေတာအတွဲတစ်ခုရှိသည်ဆိုပါစို့။
import numpy as np import matplotlib.pyplot as plt #create data np.random.seed(1) data = np.random.randn(100) #view first 5 values data[:5] array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
တူညီသော အကျယ်ကို အုပ်စုဖွဲ့ခြင်း-
ဤတန်ဖိုးများကိုပြသရန် ဟီစတိုဂရမ်တစ်ခုကို ဖန်တီးပါက၊ Python သည် တူညီသောအနံဖြင့် အုပ်စုဖွဲ့ခြင်းသို့ ပုံသေဖြစ်လိမ့်မည်-
#create histogram with equal-width bins n, bins, patches = plt.hist(data, edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -1.85282729, -1.40411588, -0.95540447, -0.50669306, -0.05798165, 0.39072977, 0.83944118, 1.28815259, 1.736864, 2.18557541]), array([ 3., 1., 6., 17., 19., 20., 14., 12., 5., 3.]))
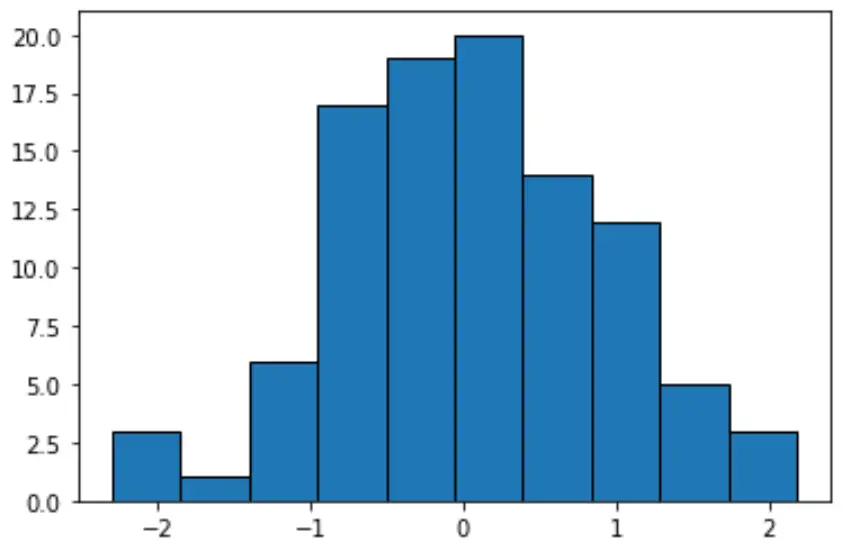
အုပ်စုတစ်ခုစီတွင် ခန့်မှန်းခြေ 0.4487 နှင့် တူညီသောအကျယ်ရှိသော်လည်း အုပ်စုတစ်ခုစီတွင် တူညီသောလေ့လာတွေ့ရှိချက်ပမာဏ မပါဝင်ပါ။ ဥပမာအားဖြင့်:
- ပထမပုံးသည် -2.3015387 မှ -1.8528279 အထိ ချဲ့ထွင်ပြီး လေ့လာချက် 3 ခု ပါရှိသည်။
- ဒုတိယပုံးသည် -1.8528279 မှ -1.40411588 သို့ တိုးချဲ့ပြီး 1 စူးစမ်းမှုပါရှိသည်။
- တတိယပုံးသည် -1.40411588 မှ -0.95540447 သို့ တိုးချဲ့ပြီး 6 ချက်ပါရှိသည်။
နောက် … ပြီးတော့။
တူညီသောကြိမ်နှုန်းအုပ်စုဖွဲ့ခြင်း-
လေ့လာတွေ့ရှိချက်အရေအတွက် တူညီသောပုံးများဖန်တီးရန်၊ အောက်ပါလုပ်ဆောင်ချက်ကို ကျွန်ုပ်တို့အသုံးပြုနိုင်သည်-
#define function to calculate equal-frequency bins def equalObs(x, nbin): nlen = len(x) return np.interp(np.linspace(0, nlen, nbin + 1), np.arange(nlen), np.sort(x)) #create histogram with equal-frequency bins n, bins, patches = plt.hist(data, equalObs(data, 10), edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -0.93576943, -0.67124613, -0.37528495, -0.20889423, 0.07734007, 0.2344157, 0.51292982, 0.86540763, 1.19891788, 2.18557541]), array([10., 10., 10., 10., 10., 10., 10., 10., 10., 10.]))
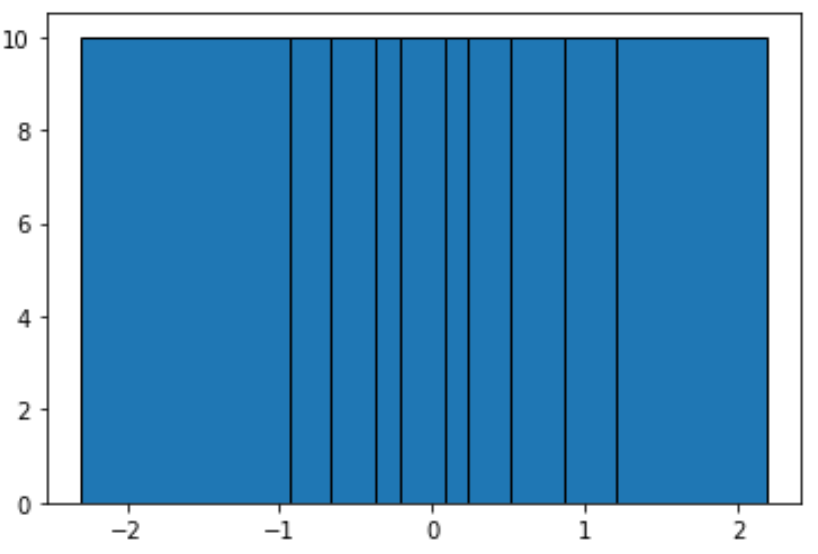
အုပ်စုတစ်ခုစီသည် အကျယ်မညီသော်လည်း အုပ်စုတစ်ခုစီတွင် တူညီသော ပမာဏတစ်ခုစီ ပါရှိသည် ။ ဥပမာအားဖြင့်:
- ပထမပုံးသည် -2.3015387 မှ -0.93576943 အထိ ချဲ့ထွင်ပြီး မှတ်သားစရာ 10 ခုပါရှိသည်။
- ဒုတိယပုံးသည် -0.93576943 မှ -0.67124613 သို့ ချဲ့ထွင်ပြီး 10 အကဲခတ်မှုများပါရှိသည်။
- တတိယပုံးသည် -0.67124613 မှ -0.37528495 အထိ ချဲ့ထွင်ပြီး 10 မှတ်ချက်များ ပါရှိသည်။
နောက် … ပြီးတော့။
ဘင်တစ်ခုစီသည် အကျယ်မတူညီကြောင်း ရှင်းရှင်းလင်းလင်း သိနိုင်သော်လည်း ဘင်တစ်ခုစီတွင် တူညီသော လေ့လာတွေ့ရှိချက်အရေအတွက်များပါရှိသည်၊ ယင်းပုံးတစ်ခုစီ၏ အမြင့်သည် တူညီကြောင်း အတည်ပြုနိုင်သည်
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။