R တွင် fisher's least significant difference (lsd) ကိုအသုံးပြုနည်း
တစ်လမ်းသွား ANOVA ကို သုံးသော သို့မဟုတ် ထို့ထက်ပိုသော လွတ်လပ်သော အုပ်စုများကြားတွင် စာရင်းအင်းဆိုင်ရာ သိသာထင်ရှားသော ခြားနားမှု ရှိ၊ မရှိ ဆုံးဖြတ်ရန် အသုံးပြုသည်။
တစ်လမ်းမောင်း ANOVA တွင်အသုံးပြုသော ယူဆချက် များမှာ-
- H 0 : အုပ်စုတစ်ခုစီအတွက် အဓိပ္ပါယ်မှာ တူညီသည်။
- H A : အနည်းဆုံး နည်းလမ်းတစ်ခုက တခြားနည်းလမ်းတွေနဲ့ မတူပါဘူး။
ANOVA ၏ p-value သည် အချို့သော အရေးပါမှုအဆင့် (ဥပမာ α = 0.05) အောက်တွင် ရှိနေပါက၊ ကျွန်ုပ်တို့သည် null hypothesis ကို ငြင်းပယ်နိုင်ပြီး အနည်းဆုံး အုပ်စု၏ ဆိုလိုသည်မှာ အခြားနည်းများနှင့် ကွဲပြားသည်ဟု ကောက်ချက်ချနိုင်ပါသည်။
ဒါပေမယ့် ဘယ်အဖွဲ့တွေက တစ်ခုနဲ့တစ်ခု မတူဘူးဆိုတာ အတိအကျသိဖို့အတွက် Post-hoc test လုပ်ဖို့လိုပါတယ်။
အသုံးများသော post hoc test သည် Fisher ၏ အနည်းဆုံး သိသာထင်ရှားသောခြားနားချက် (LSD) စမ်းသပ်မှု ဖြစ်သည်။
ဤစမ်းသပ်မှုကို R ဖြင့်လုပ်ဆောင်ရန် agricoae package မှ LSD.test() လုပ်ဆောင်ချက်ကို သင်အသုံးပြုနိုင်ပါသည်။
အောက်ဖော်ပြပါ ဥပမာသည် ဤလုပ်ဆောင်ချက်ကို လက်တွေ့အသုံးချနည်းကို ပြသထားသည်။
ဥပမာ- R တွင် Fisher’s LSD စမ်းသပ်မှု
မတူကွဲပြားသော လေ့လာမှုနည်းပညာသုံးမျိုးသည် ကျောင်းသားများကြားတွင် မတူညီသော စာမေးပွဲရမှတ်များ ဖြစ်ပေါ်လာခြင်းရှိမရှိကို ပါမောက္ခတစ်ဦးက သိချင်သည်ဆိုပါစို့။
၎င်းကို စမ်းသပ်ရန်အတွက် ကျောင်းသား ၁၀ ဦးအား လေ့လာမှုနည်းပညာတစ်ခုစီကို အသုံးပြုကာ ၎င်းတို့၏ စာမေးပွဲရလဒ်များကို မှတ်တမ်းတင်ရန် ကျပန်းပေးသည်။
အောက်ဖော်ပြပါဇယားတွင် အသုံးပြုသည့် လေ့လာမှုနည်းပညာအပေါ် အခြေခံ၍ ကျောင်းသားတစ်ဦးစီ၏ စာမေးပွဲရလဒ်များကို ပြသသည်-
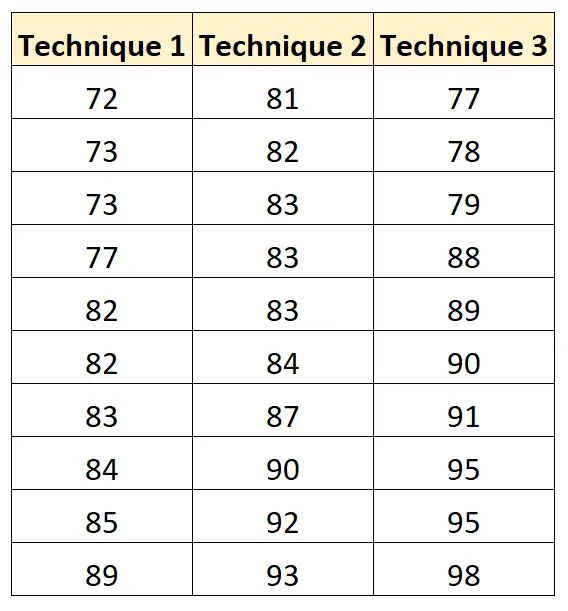
ဤဒေတာအတွဲကို ဖန်တီးရန်နှင့် R ဖြင့် တစ်ကြောင်း ANOVA ကို လုပ်ဆောင်ရန် အောက်ပါကုဒ်ကို ကျွန်ုပ်တို့ အသုံးပြုနိုင်ပါသည်။
#create data frame
df <- data. frame (technique = rep(c("tech1", "tech2", "tech3"), each = 10 ),
score = c(72, 73, 73, 77, 82, 82, 83, 84, 85, 89,
81, 82, 83, 83, 83, 84, 87, 90, 92, 93,
77, 78, 79, 88, 89, 90, 91, 95, 95, 98))
#view first six rows of data frame
head(df)
technical score
1 tech1 72
2 tech1 73
3 tech1 73
4 tech1 77
5 tech1 82
6 tech1 82
#fit one-way ANOVA
model <- aov(score ~ technique, data = df)
#view summary of one-way ANOVA
summary(model)
Df Sum Sq Mean Sq F value Pr(>F)
technical 2 341.6 170.80 4.623 0.0188 *
Residuals 27,997.6 36.95
---
Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
ANOVA ဇယားရှိ p-value (0.0188) သည် 0.05 ထက်နည်းသောကြောင့်၊ အုပ်စုသုံးစုကြားရှိ ပျမ်းမျှစာမေးပွဲရမှတ်များအားလုံး မညီမျှကြောင်း ကောက်ချက်ချနိုင်ပါသည်။
ထို့ကြောင့်၊ ကျွန်ုပ်တို့သည် မည်သည့်အဖွဲ့၏နည်းလမ်းများ ကွဲပြားသည်ကို ဆုံးဖြတ်ရန် Fisher’s LSD စမ်းသပ်မှုကို လုပ်ဆောင်နိုင်သည်။
အောက်ပါကုဒ်သည် ၎င်းကိုပြုလုပ်နည်းကို ပြသသည်-
library (agricolae)
#perform Fisher's LSD
print( LSD.test (model," technic "))
$statistics
MSerror Df Mean CV t.value LSD
36.94815 27 84.6 7.184987 2.051831 5.57767
$parameters
test p.adjusted name.t ntr alpha
Fisher-LSD none technical 3 0.05
$means
std score r LCL UCL Min Max Q25 Q50 Q75
tech1 80.0 5.868939 10 76.05599 83.94401 72 89 74.00 82.0 83.75
tech2 85.8 4.391912 10 81.85599 89.74401 81 93 83.00 83.5 89.25
tech3 88.0 7.557189 10 84.05599 91.94401 77 98 81.25 89.5 94.00
$comparison
NULL
$groups
score groups
tech3 88.0 a
tech2 85.8a
tech1 80.0 b
attr(,"class")
[1] “group”
ကျွန်ုပ်တို့စိတ်ဝင်စားဆုံးရလဒ်၏အစိတ်အပိုင်းမှာ $groups ဟုခေါ်သောအပိုင်းဖြစ်သည်။ အုပ်စု ကော်လံတွင် မတူညီသော ဇာတ်ကောင်များပါသည့် နည်းပညာများသည် အလွန်ကွဲပြားပါသည်။
ရလဒ်မှ ကျွန်ုပ်တို့ မြင်နိုင်သည်-
- Technique 1 နှင့် Technique 3 တွင် သိသိသာသာကွဲပြားသော ပျမ်းမျှစာမေးပွဲရမှတ်များ (tech1 တွင် “b” တန်ဖိုးရှိပြီး tech3 တွင် “a” တန်ဖိုးရှိသောကြောင့်)။
- Technique 1 နှင့် Technique 2 တွင် သိသိသာသာကွာခြားသော ပျမ်းမျှစာမေးပွဲရမှတ်များ (tech1 တွင် “b” တန်ဖိုးရှိပြီး tech2 တွင် “a” တန်ဖိုးရှိသောကြောင့်)။
- Technique 2 နှင့် Technique 3 တွင် သိသိသာသာကွဲပြားသော ပျမ်းမျှစာမေးပွဲရမှတ်များ မရှိပါ (နှစ်ခုလုံးတွင် “a” တန်ဖိုးရှိသောကြောင့်)
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် R တွင် အခြားဘုံအလုပ်များကို မည်သို့လုပ်ဆောင်ရမည်ကို ရှင်းပြသည်-
တစ်လမ်းမောင်း ANOVA ကို R ဖြင့် မည်သို့လုပ်ဆောင်ရမည်နည်း။
R တွင် Bonferroni post hoc စမ်းသပ်နည်း
R တွင် Scheffe post-hoc စမ်းသပ်နည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။