Python တွင် ပုံမှန်ဖြန့်ဝေနည်း (ဥပမာများနှင့်အတူ)
အောက်ပါ syntax ကိုအသုံးပြုသည့် numpy.random.normal() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ Python တွင် ပုံမှန်ဖြန့်ဝေမှုကို လျင်မြန်စွာ ဖန်တီးနိုင်သည်-
numpy. random . normal (loc=0.0, scale=1.0, size=None)
ရွှေ-
- တည်နေရာ- ဖြ န့်ဖြူးမှု၏ပျမ်းမျှ။ မူရင်းတန်ဖိုးသည် 0 ဖြစ်သည်။
- အတိုင်းအတာ- ဖြန့ ်ဖြူးမှု၏ စံသွေဖည်မှု။ မူရင်းတန်ဖိုးမှာ 1 ဖြစ်သည်။
- အရွယ်အစား- နမူနာအရွယ်အစား။
ဤသင်ခန်းစာတွင် Python တွင် ပုံမှန်ဖြန့်ဝေမှုတစ်ခုကို ဖန်တီးရန် ဤလုပ်ဆောင်ချက်ကို အသုံးပြုခြင်း၏ နမူနာကို ပြသထားသည်။
ဆက်စပ်- Python တွင် Bell Curve ဖန်တီးနည်း
ဥပမာ- Python တွင် ပုံမှန်ဖြန့်ဝေမှုကို ဖန်တီးခြင်း။
အောက်ဖော်ပြပါ ကုဒ်သည် Python တွင် ပုံမှန်ဖြန့်ဖြူးမှုကို မည်သို့ထုတ်လုပ်ရမည်ကို ပြသသည်-
from numpy. random import seed
from numpy. random import normal
#make this example reproducible
seed(1)
#generate sample of 200 values that follow a normal distribution
data = normal (loc=0, scale=1, size=200)
#view first six values
data[0:5]
array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
ဤဖြန့်ဖြူးမှု၏ ပျမ်းမျှနှင့် စံသွေဖည်မှုကို ကျွန်ုပ်တို့ အမြန်ရှာဖွေနိုင်သည်-
import numpy as np
#find mean of sample
n.p. mean (data)
0.1066888148479486
#find standard deviation of sample
n.p. std (data, ddof= 1 )
0.9123296653173484
ဒေတာတန်ဖိုးများ ဖြန့်ဖြူးမှုကို မြင်သာစေရန် အမြန် histogram တစ်ခုကိုလည်း ဖန်တီးနိုင်သည်-
import matplotlib. pyplot as plt
count, bins, ignored = plt. hist (data, 30)
plt. show ()
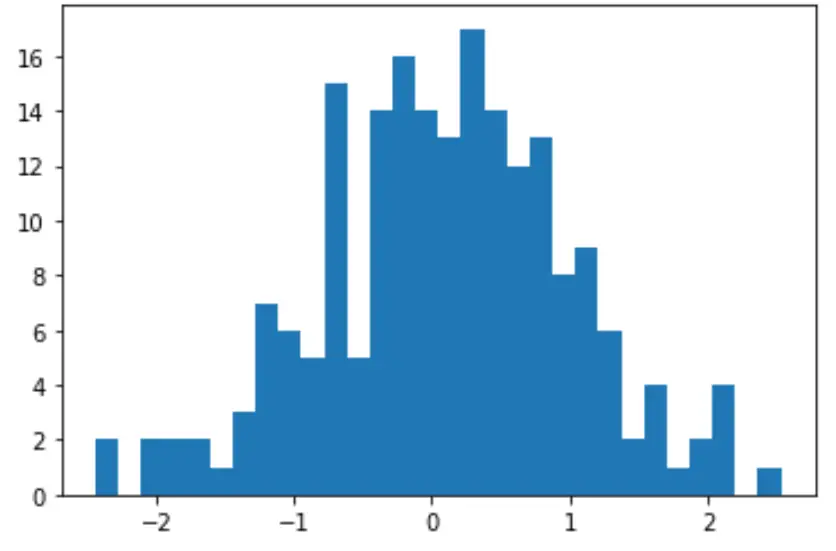
ဒေတာအတွဲသည် သာမန်လူဦးရေမှ ဆင်းသက်ခြင်းရှိ၊ မရှိ စစ်ဆေးရန် Shapiro-Wilk စမ်းသပ်မှုကို ပင် လုပ်ဆောင်နိုင်သည်-
from scipy. stats import shapiro
#perform Shapiro-Wilk test
shapiro(data)
ShapiroResult(statistic=0.9958659410, pvalue=0.8669294714)
စမ်းသပ်မှု၏ p-တန်ဖိုးသည် 0.8669 ဖြစ်လာသည်။ ဤတန်ဖိုးသည် 0.05 ထက်မနည်းသောကြောင့်၊ နမူနာဒေတာသည် ပုံမှန်ဖြန့်ဝေထားသော လူဦးရေမှလာသည်ဟု ကျွန်ုပ်တို့ ယူဆနိုင်ပါသည်။
ကျွန်ုပ်တို့သည် numpy.random.normal() လုပ်ဆောင်ချက်ကို အသုံးပြု၍ ဒေတာကို ပုံမှန်ဖြန့်ဝေမှုမှ ဒေတာ၏ ကျပန်းနမူနာကို ထုတ်ပေးသောကြောင့် ဤရလဒ်သည် အံ့သြစရာမဖြစ်သင့်ပါ။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။