Python တွင် cook ၏အကွာအဝေးကိုဘယ်လိုတွက်မလဲ။
Cook ၏ အကွာအဝေး ကို ဆုတ်ယုတ်မှုပုံစံတစ်ခုတွင် သြဇာညောင်းသော စောင့်ကြည့်မှုများကို ဖော်ထုတ်ရန် အသုံးပြုသည်။
Cook ၏ အကွာအဝေးအတွက် ဖော်မြူလာမှာ-
d i = (r i 2 / p*MSE) * (h ii / (1-h ii ) 2 )
ရွှေ-
- r i သည် i th အကြွင်းဖြစ်သည်။
- p သည် regression model တွင် coefficients အရေအတွက်ဖြစ်သည်။
- MSE သည် mean square error ဖြစ်သည်။
- h ii သည် ith leverage တန်ဖိုးဖြစ်သည်။
အခြေခံအားဖြင့်၊ Cook ၏ အကွာအဝေးသည် i th observation ကို ဖယ်ရှားလိုက်သောအခါ မော်ဒယ်ပြောင်းလဲမှုအားလုံး၏ တပ်ဆင်တန်ဖိုးများ မည်မျှရှိသည်ကို တိုင်းတာသည်။
Cook ၏ အကွာအဝေး၏တန်ဖိုး ကြီးမားလေ၊ ပေးထားသော စောင့်ကြည့်မှုမှာ သြဇာပိုလေဖြစ်သည်။
ယေဘူယျအားဖြင့်၊ Cook ၏ အကွာအဝေးသည် 4/n ( n = စုစုပေါင်း စောင့်ကြည့်မှုများ) ထက် ကြီးမားသော လွှမ်းမိုးမှုရှိသည်ဟု ယူဆပါသည်။
ဤသင်ခန်းစာသည် Python ရှိ ပေးထားသော ဆုတ်ယုတ်မှုပုံစံအတွက် Cook ၏ အကွာအဝေးကို တွက်ချက်နည်း အဆင့်ဆင့် ဥပမာကို ပေးပါသည်။
အဆင့် 1: ဒေတာကိုထည့်ပါ။
ပထမဦးစွာ Python တွင်အလုပ်လုပ်ရန် သေးငယ်သောဒေတာအတွဲတစ်ခုကို ဖန်တီးပါမည်။
import pandas as pd #create dataset df = pd. DataFrame ({' x ': [8, 12, 12, 13, 14, 16, 17, 22, 24, 26, 29, 30], ' y ': [41, 42, 39, 37, 35, 39, 45, 46, 39, 49, 55, 57]})
အဆင့် 2- ဆုတ်ယုတ်မှုပုံစံကို အံကိုက်လုပ်ပါ။
ထို့နောက်၊ ကျွန်ုပ်တို့သည် ရိုးရှင်းသော linear regression model ကို ကိုက်ညီပါမည်-
import statsmodels. api as sm
#define response variable
y = df[' y ']
#define explanatory variable
x = df[' x ']
#add constant to predictor variables
x = sm. add_constant (x)
#fit linear regression model
model = sm. OLS (y,x). fit ()
အဆင့် 3- Cook Distance ကို တွက်ချက်ပါ။
ထို့နောက်၊ မော်ဒယ်ရှိကြည့်ရှုမှုတစ်ခုစီအတွက် Cook အကွာအဝေးကို တွက်ချက်ပါမည်။
#suppress scientific notation
import numpy as np
n.p. set_printoptions (suppress= True )
#create instance of influence
influence = model. get_influence ()
#obtain Cook's distance for each observation
cooks = influence. cooks_distance
#display Cook's distances
print (cooks)
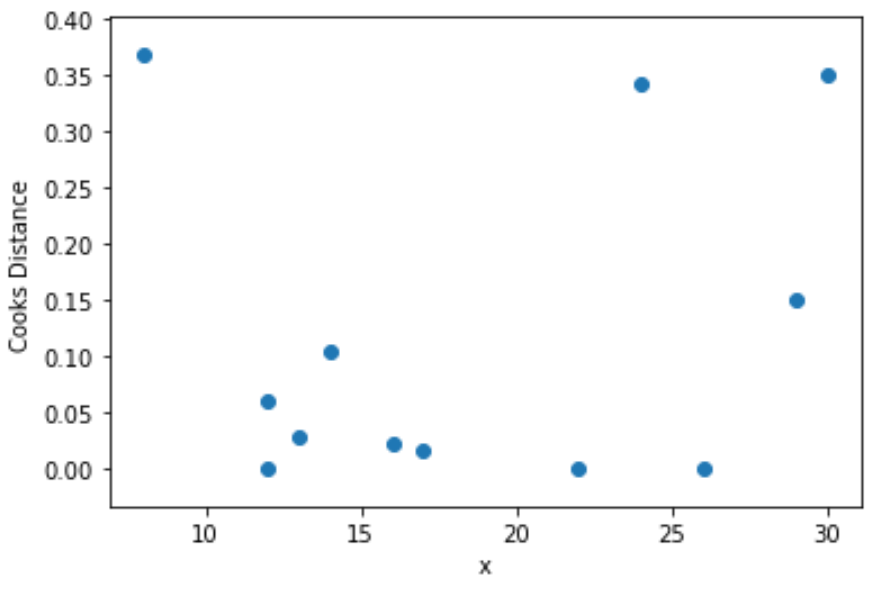
(array([0.368, 0.061, 0.001, 0.028, 0.105, 0.022, 0.017, 0. , 0.343,
0. , 0.15 , 0.349]),
array([0.701, 0.941, 0.999, 0.973, 0.901, 0.979, 0.983, 1. , 0.718,
1. , 0.863, 0.713]))
ပုံမှန်အားဖြင့်၊ cooks_distance() လုပ်ဆောင်ချက်သည် ရှုမြင်မှုတစ်ခုစီအတွက် Cook ၏ အကွာအဝေးအတွက် တန်ဖိုးများ ခင်းကျင်းပြသထားပြီး ၎င်းနောက်တွင် သက်ဆိုင်ရာ p-တန်ဖိုးများ ပါဝင်သည်။
ဥပမာအားဖြင့်:
- ရှုခင်းအတွက် Cook ၏ အကွာအဝေး #1: 0.368 (p-value: 0.701)
- ရှုခင်းအတွက် Cook ၏ အကွာအဝေး #2: 0.061 (p-value: 0.941)
- ရှုခင်းအတွက် Cook ၏ အကွာအဝေး #3: 0.001 (p-value: 0.999)
နောက် … ပြီးတော့။
အဆင့် 4-ချက်ပြုတ်သူ၏အကွာအဝေးကိုမြင်ယောင်ကြည့်ပါ။
နောက်ဆုံးအနေနဲ့၊ ရှုမြင်မှုတစ်ခုစီအတွက် Cook ရဲ့ အကွာအဝေးရဲ့ လုပ်ဆောင်မှုတစ်ခုအနေနဲ့ ခန့်မှန်းသူ variable ရဲ့ တန်ဖိုးတွေကို မြင်ယောင်နိုင်ဖို့ scatterplot တစ်ခုကို ဖန်တီးနိုင်ပါတယ်။
import matplotlib. pyplot as plt
plt. scatter (df.x, cooks[0])
plt. xlabel (' x ')
plt. ylabel (' Cooks Distance ')
plt. show ()
နောက်ဆုံးအတွေးများ
သြဇာရှိနိုင်ချေရှိသော စူးစမ်းမှုများကို ဖော်ထုတ်ရန် Cook ၏ အကွာအဝေးကို အသုံးပြုသင့်ကြောင်း မှတ်သားထားရန် အရေးကြီးပါသည်။ စူးစမ်းမှုတစ်ခုသည် လွှမ်းမိုးမှုရှိသောကြောင့် ၎င်းအား ဒေတာအတွဲမှ ဖယ်ရှားသင့်သည်ဟု မဆိုလိုပါ။
ပထမဦးစွာ၊ လေ့လာကြည့်ရှုမှုသည် ဒေတာထည့်သွင်းမှုအမှား သို့မဟုတ် အခြားထူးဆန်းသည့်ဖြစ်ရပ်တစ်ခု၏ ရလဒ်မဟုတ်ကြောင်း သင်စစ်ဆေးရန်လိုအပ်သည်။ တရားဝင်တန်ဖိုးဖြစ်လာပါက ၎င်းကိုဖယ်ရှားရန်၊ ၎င်းကို ယခင်အတိုင်းထားရန်၊ သို့မဟုတ် ၎င်းကို အလယ်အလတ်ကဲ့သို့သော အခြားတန်ဖိုးတစ်ခုဖြင့် အစားထိုးရန် သင့်လျော်မှုရှိမရှိ သင်ဆုံးဖြတ်နိုင်သည်။
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။