အစက်ချကွက်နှင့် ဟီစတိုဂရမ်- ကွာခြားချက်ကား အဘယ်နည်း။
ဒေတာအတွဲတစ်ခုအတွင်း တန်ဖိုးများဖြန့်ဝေမှုကို မြင်သာစေရန် အသုံးများသောကွက်နှစ်ခုမှာ အစက်ကွက်များ နှင့် ဟစ်စတိုဂရမ်များ ဖြစ်သည်။
အစက်ချကွက် တစ်ခုသည် x-ဝင်ရိုးတစ်လျှောက် ဒေတာတန်ဖိုးများကို ပြသပြီး တန်ဖိုးတစ်ခုစီ၏ ကြိမ်နှုန်းများကို ကိုယ်စားပြုရန် အမှတ်များကို အသုံးပြုသည်။
ဟီစတိုဂရမ် သည် x-ဝင်ရိုးတစ်လျှောက် ဒေတာအပိုင်းအခြားများကို ပြသပြီး အပိုင်းအခြားတစ်ခုစီနှင့် သက်ဆိုင်သည့် တန်ဖိုးများ၏ ကြိမ်နှုန်းများကို ကိုယ်စားပြုရန်အတွက် လေးထောင့်ကွက်များကို အသုံးပြုသည်။
အောက်ပါဥပမာသည် တူညီသောဒေတာအတွဲအတွက် အစက်ချကွက်နှင့် ဟီစတိုဂရမ်တစ်ခုကို မည်သို့ဖန်တီးရမည်ကို ပြသထားသည်။
ဥပမာ- တူညီသော Data Set အတွက် Dot Plot နှင့် Histogram ဖန်တီးခြင်း။
ကျွန်ုပ်တို့တွင် တန်ဖိုး 18 ခုရှိသည့် အောက်ပါဒေတာအတွဲရှိသည်ဆိုပါစို့။
ဒေတာ- 1၊ 1၊ 1၊ 1၊ 2၊ 2၊ 2၊ 3၊ 4၊ 5၊ 5၊ 6၊ 6၊ 6၊ 6၊ 7၊ 8၊ 10
ဤဒေတာအတွဲအတွက် အစက်ချကွက်သည် မည်သို့မည်ပုံဖြစ်သည်-
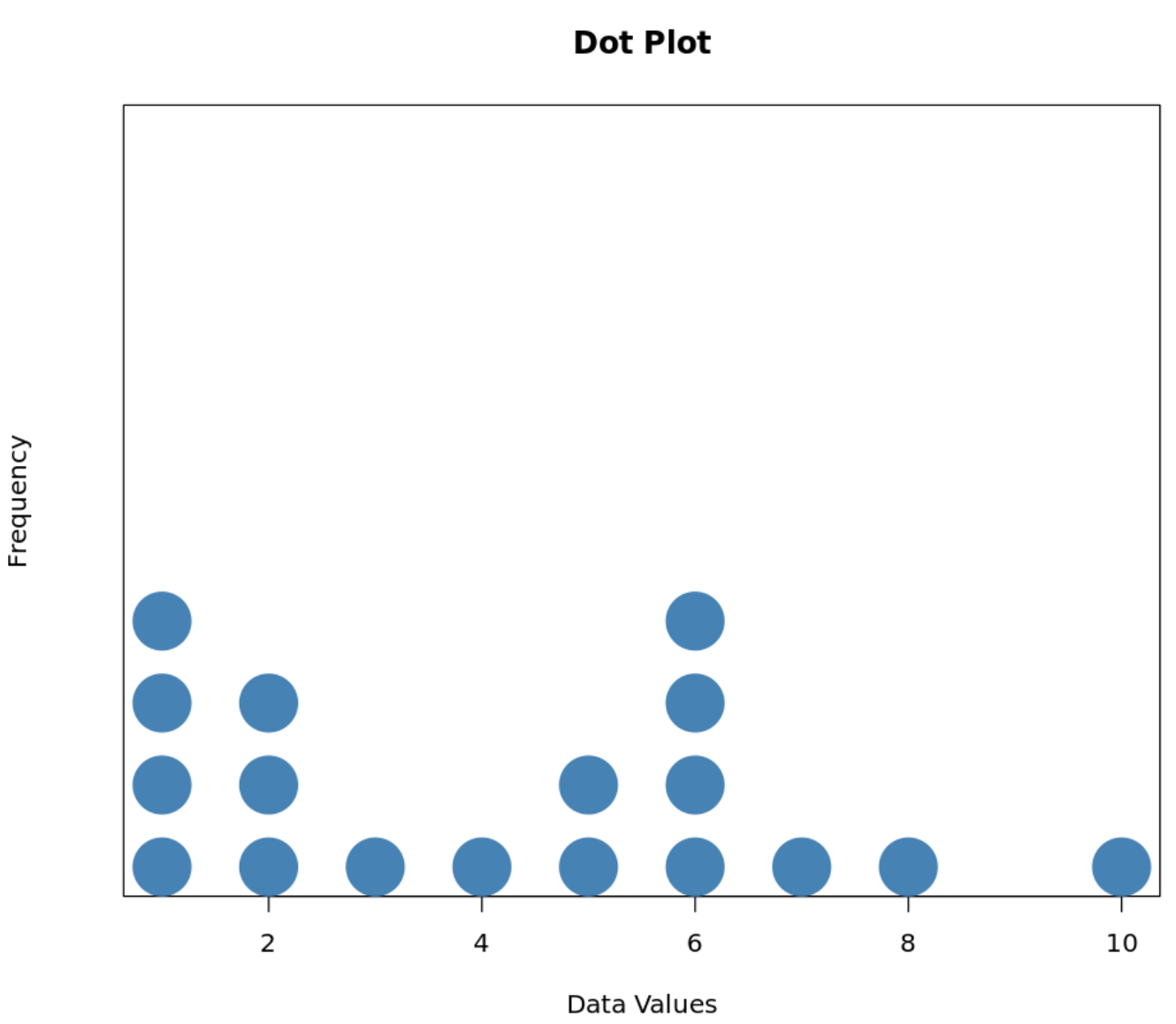
x-axis သည် တစ်ဦးချင်းစီဒေတာတန်ဖိုးများကိုပြသပြီး y-axis သည် တန်ဖိုးတစ်ခုစီ၏ကြိမ်နှုန်းကိုပြသသည်။
ဥပမာအားဖြင့်၊ တန်ဖိုး “ 2” သည် ၎င်း၏အထက်တွင် အချက်သုံးချက်ရှိသောကြောင့် ဒေတာအတွဲတွင် သုံးကြိမ်ပေါ်လာကြောင်း ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။ အလားတူ၊ ၎င်း၏အထက်တွင် အစက်တစ်စက်သာရှိသောကြောင့် တန်ဖိုး “ 3” သည် တစ်ကြိမ်သာပေါ်လာသည်ကို ကျွန်ုပ်တို့တွေ့မြင်နိုင်ပါသည်။
ဤဒေတာအတွဲအတွက် ဟစ်စတိုဂရမ်ပုံသဏ္ဍန်မှာ ဤအရာဖြစ်သည်-
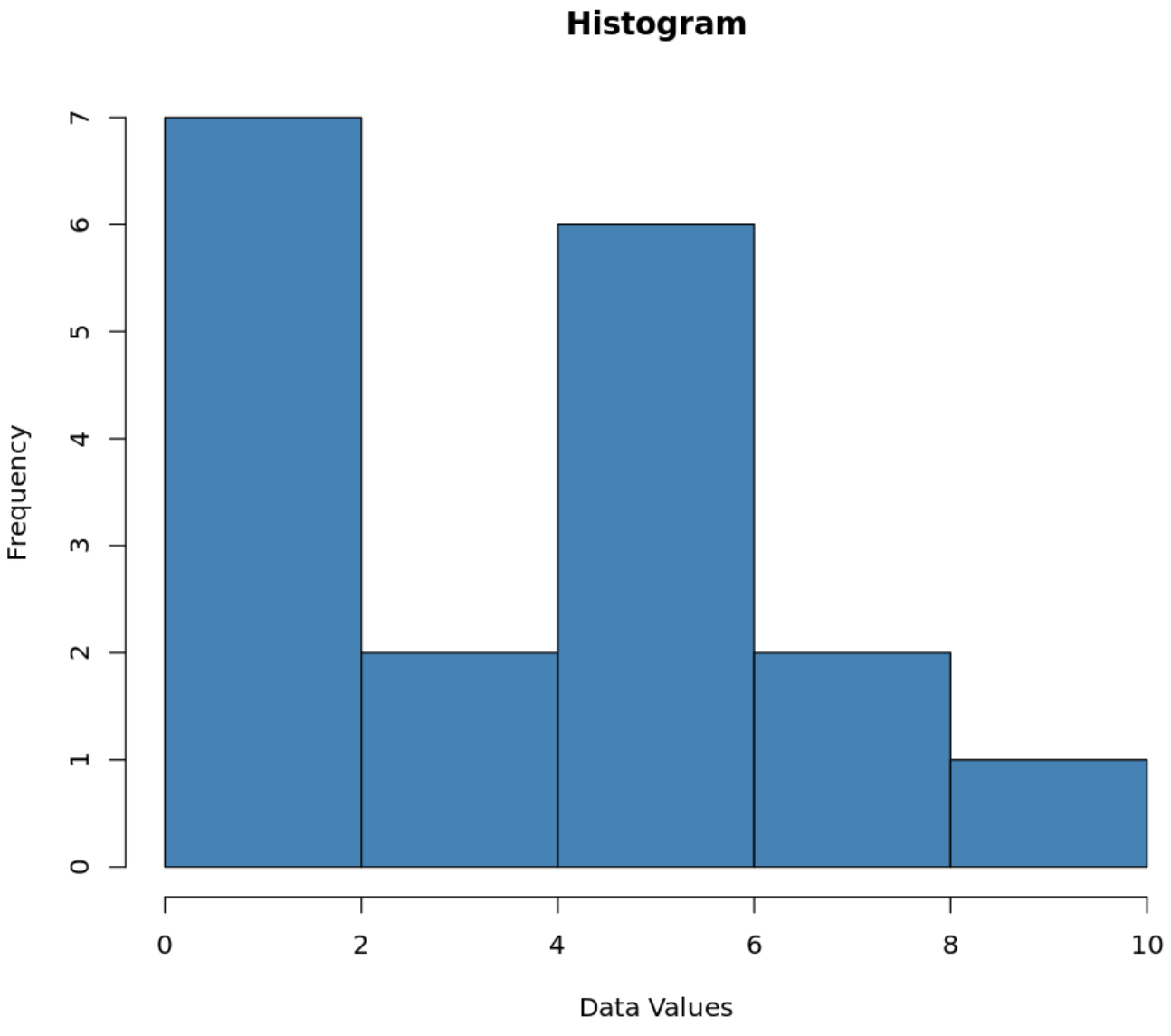
သပ်ရပ်သည်။
ဥပမာအားဖြင့်၊ တန်ဖိုးခုနစ်ခုသည် 0 နှင့် 2 အကြား၊ နှစ်ခုတန်ဖိုးများသည် 2 နှင့် 4 အကြား စသည်တို့ဖြစ်သည်။
အပိုဆု – သိချင်သူများအတွက်၊ အထက်တွင်ပြထားသည့် အစက်ကွက်နှင့် ဟီစတိုဂရမ်ကို ဖန်တီးရန် အောက်ပါ R ကုဒ်ကို အသုံးပြုခဲ့သည်။
#define dataset data <- c(1, 1, 1, 1, 2, 2, 2, 3, 4, 5, 5, 6, 6, 6, 6, 7, 8, 10) #create dot plot stripchart(data, method = "stack", offset = .5, at = 0, pch = 19, cex=5, col = "steelblue", main = "Dot Plot", xlab = "Data Values", ylab="Frequency") #create histogram hist(data, col='steelblue', main='Histogram', xlab='Data Values')
Dot Plot သို့မဟုတ် Histogram- မည်သည့်အရာကို အသုံးပြုသင့်သနည်း။
အစောပိုင်းတွင် ဖော်ပြခဲ့သည့်အတိုင်း ဒေတာအတွဲတစ်ခုတွင် တန်ဖိုးများဖြန့်ဝေမှုကို မြင်သာစေရန် အစက်ချကွက်နှင့် ဟီစတိုဂရမ်ကို အသုံးပြုနိုင်သည်။
လက်မ၏ စည်းမျဉ်းအတိုင်း၊ ကျွန်ုပ်တို့၏ဒေတာအတွဲသည် သေးငယ်သောအခါတွင် အစက်ချကွက်များကို အသုံးပြုလေ့ရှိပြီး ၎င်းသည် ကျွန်ုပ်တို့အား တန်ဖိုးတစ်ခုစီတွင် အကြိမ်မည်မျှပေါ်လာသည်ကို အတိအကျမြင်နိုင်စေသောကြောင့်ဖြစ်သည်။
အပြန်အလှန်အားဖြင့်၊ ကျွန်ုပ်တို့၏ဒေတာအစုံသည် ကြီးမားသောအခါတွင်၊ ဒေတာအစုတစ်ခုစီတွင် တစ်ဦးချင်းစီတန်ဖိုးတစ်ခုစီကိုကိုယ်စားပြုရန် အမှတ်တစ်ခုဖန်တီးရန် ပျင်းသောကြောင့် ယေဘူယျအားဖြင့် ဟီစတိုဂရမ်များကို အသုံးပြုပါသည် ။
ဟီစတိုဂရမ်ကို အသုံးပြုခြင်း၏ တစ်ခုတည်းသော အားနည်းချက်မှာ တန်ဖိုးတစ်ခုစီတွင် မည်မျှပေါ်လာသည်ကို ကျွန်ုပ်တို့အတိအကျ မပြောနိုင်ကြောင်း သတိရပါ။
ဥပမာအားဖြင့်၊ ယခင် histogram တွင် တန်ဖိုးခုနစ်ခုသည် 0 နှင့် 2 အကြားရှိသည်ကို ကျွန်ုပ်တို့တွေ့ခဲ့ရသော်လည်း တန်ဖိုးမည်မျှရှိသည်ကို 1 နှင့် 2 တန်ဖိုးများမည်မျှရှိသည်ကို အတိအကျမသိပါ။
အကယ်၍ ကျွန်ုပ်တို့သည် ဖြန့်ဖြူးမှုတစ်ခု၏ ယေဘုယျ “ ပုံသဏ္ဍာန်” ကို နားလည်လိုပါက၊ ဒေတာအစုတစ်ခု၏ တစ်ဦးချင်းတန်ဖိုးများကို မသိပါက ယေဘုယျအားဖြင့် အရေးမကြီးပါ။
ကျွန်ုပ်တို့သည် တစ်ဦးချင်းတန်ဖိုးများကို မသိသောကြောင့် ဟီစတိုဂရမ်ကို ကြည့်ရုံဖြင့် အတိအကျ ပျမ်းမျှ သို့မဟုတ် ပျမ်းမျှကို တွက်ချက်၍မရနိုင်ကြောင်းကိုလည်း သတိပြုပါ။
ထပ်လောင်းအရင်းအမြစ်များ
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် ဟီစတိုဂရမ်များအကြောင်း နောက်ထပ်အချက်အလက်များကို ပေးဆောင်သည်-
ပျမ်းမျှနှင့် အလယ်အလတ် ဟီစတိုဂရမ်များကို ခန့်မှန်းနည်း
ဟစ်စတိုဂရမ်ပုံသဏ္ဍာန်ကို ဘယ်လိုဖော်ပြမလဲ။
R တွင် histograms ဖန်တီးနည်း
Python တွင် Histogram ဖန်တီးနည်း
အောက်ဖော်ပြပါ သင်ခန်းစာများသည် အမှတ်ကွက်များအကြောင်း နောက်ထပ်အချက်အလက်များကို ပေးဆောင်သည်-
အစက်ချကွက်တစ်ခု၏ အလယ်ဗဟိုကို ရှာဖွေနည်း
Google Sheets တွင် Dot Plot ဖန်တီးနည်း
Excel တွင် Dot Plot ဖန်တီးနည်း
R တွင် Dot Plot ဖန်တီးနည်း
စာရေးသူအကြောင်း
Benjamin Anderson
မင်္ဂလာပါ၊ ကျွန်ုပ်သည် အငြိမ်းစား စာရင်းအင်း ပါမောက္ခ ဘင်ဂျမင်ဖြစ်ပြီး သီးသန့် Statorials ဆရာအဖြစ် လှည့်ပတ်ပါသည်။ စာရင်းဇယားနယ်ပယ်တွင် ကျယ်ပြန့်သောအတွေ့အကြုံနှင့် ကျွမ်းကျင်မှုနှင့်အတူ၊ Statorials မှတစ်ဆင့် ကျောင်းသားများကို ခွန်အားဖြစ်စေရန်အတွက် ကျွန်ုပ်၏အသိပညာကို မျှဝေလိုပါသည်။ ပိုသိတယ်။