Vorm metingen
In dit artikel wordt uitgelegd wat vormmetingen zijn. U leert dus waarvoor vormmetrieken worden gebruikt, hoe vormmetrieken worden geïnterpreteerd en hoe dit soort statistische metrieken worden berekend.
Wat zijn vormmetingen?
In de statistiek zijn vormmetingen indicatoren waarmee we een waarschijnlijkheidsverdeling kunnen beschrijven op basis van zijn vorm. Dat wil zeggen dat vormmetingen worden gebruikt om te bepalen hoe een verdeling eruit ziet zonder dat deze in een grafiek hoeft te worden weergegeven.
Er zijn twee soorten vormmetingen: scheefheid en kurtosis. Scheefheid geeft aan hoe symmetrisch een verdeling is, terwijl kurtosis aangeeft hoe geconcentreerd een verdeling rond het gemiddelde is.
Wat zijn de vormmetingen?
Gezien de definitie van vormmetingen, laat deze sectie zien wat dit soort statistische parameters zijn.
In de statistiek onderscheiden we twee vormmetingen:
- Scheefheid : geeft aan of een verdeling symmetrisch of asymmetrisch is.
- Kurtosis – Geeft aan of een verdeling steil of vlak is.
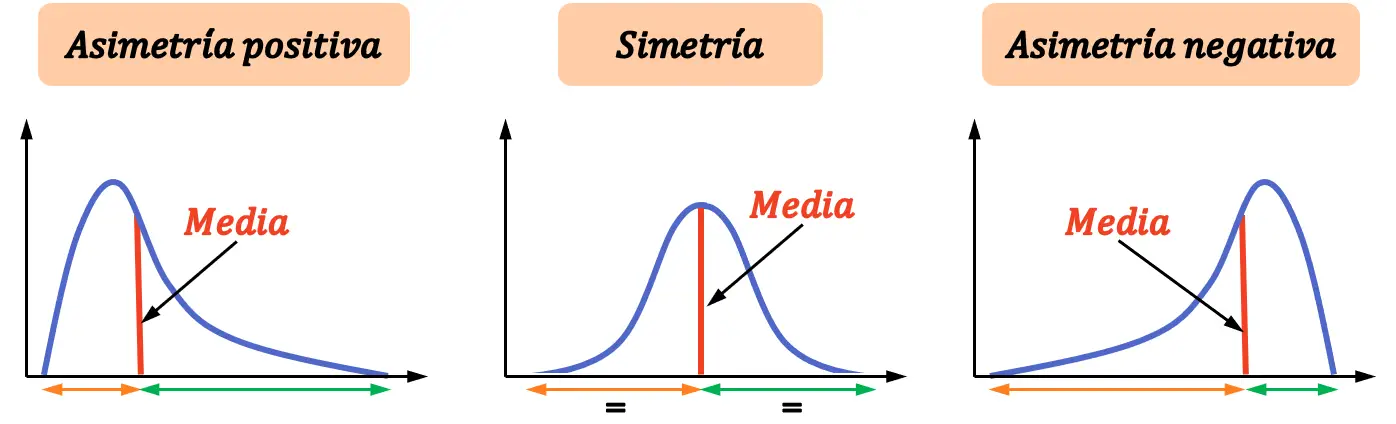
Asymmetrie
Er zijn drie soorten asymmetrie :
- Positieve asymmetrie : De verdeling heeft meer verschillende waarden rechts van het gemiddelde dan links ervan.
- Symmetrie : De verdeling heeft hetzelfde aantal waarden links van het gemiddelde als rechts van het gemiddelde.
- Negatieve scheefheid : de verdeling heeft meer verschillende waarden links van het gemiddelde dan rechts ervan.
asymmetriecoëfficiënt
De scheefheidscoëfficiënt , of asymmetrie-index , is een statistische coëfficiënt die helpt bij het bepalen van de asymmetrie van een verdeling. Door de asymmetriecoëfficiënt te berekenen is het dus mogelijk om het type asymmetrie van de verdeling te kennen zonder er een grafische weergave van te hoeven maken.
Hoewel er verschillende formules zijn om de asymmetriecoëfficiënt te berekenen, en we zullen ze hieronder allemaal zien, gebeurt de interpretatie van de asymmetriecoëfficiënt, ongeacht de gebruikte formule, altijd als volgt:
- Als de scheefheidscoëfficiënt positief is, is de verdeling positief scheef .
- Als de scheefheidscoëfficiënt nul is, is de verdeling symmetrisch .
- Als de scheefheidscoëfficiënt negatief is, is de verdeling negatief scheef .
Fisher’s asymmetriecoëfficiënt
De scheefheidscoëfficiënt van Fisher is gelijk aan het derde moment rond het gemiddelde gedeeld door de standaarddeviatie van de steekproef. Daarom is de formule voor de asymmetriecoëfficiënt van Fisher :

Op equivalente wijze kan een van de volgende twee formules worden gebruikt om de Fisher-coëfficiënt te berekenen:

![\displaystyle\gamma_1=\frac{\operatorname{E}[X^3] - 3\mu\sigma^2 - \mu^3}{\sigma^3}](https://statorials.org/wp-content/ql-cache/quicklatex.com-92f7c8482d520258f24cc0166d898d1e_l3.png "Rendered by QuickLaTeX.com")
Goud

is de wiskundige verwachting,

het rekenkundig gemiddelde,

de standaarddeviatie en

het totale aantal gegevens.
Aan de andere kant, als de gegevens gegroepeerd zijn, kunt u de volgende formule gebruiken:

Waar in dit geval

Het is het teken van klasse en

de absolute frequentie van de cursus.
Pearson’s asymmetriecoëfficiënt
De scheefheidscoëfficiënt van Pearson is gelijk aan het verschil tussen het steekproefgemiddelde en de steekproefmodus gedeeld door de standaardafwijking (of standaardafwijking). De formule voor de Pearson-asymmetriecoëfficiënt is daarom als volgt:

Goud

is de Pearson-coëfficiënt,
het rekenkundig gemiddelde,

mode en
de standaardafwijking.
Houd er rekening mee dat de Pearson-scheefheidscoëfficiënt alleen kan worden berekend als het een unimodale verdeling is, dat wil zeggen als er slechts één modus in de gegevens aanwezig is.
Bowley’s asymmetriecoëfficiënt
De scheefheidscoëfficiënt van Bowley is gelijk aan de som van het derde kwartiel plus het eerste kwartiel minus tweemaal de mediaan gedeeld door het verschil tussen het derde en het eerste kwartiel. De formule voor deze asymmetriecoëfficiënt is daarom als volgt:

Goud

En

zijn respectievelijk het eerste en derde kwartiel en

is de mediaan van de verdeling.
Afvlakking
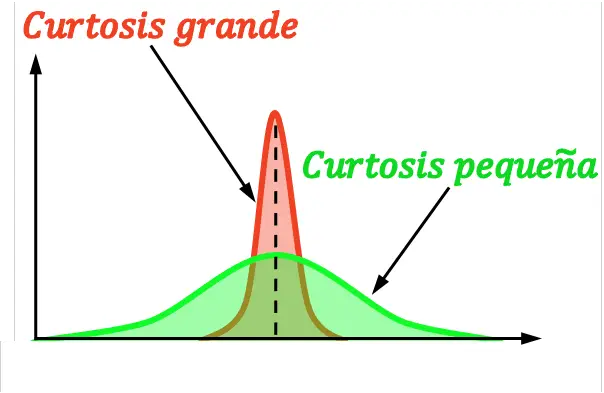
Kurtosis , ook wel scheefheid genoemd, geeft aan hoe geconcentreerd een verdeling rond het gemiddelde is. Met andere woorden, kurtosis geeft aan of een verdeling steil of vlak is. Concreet geldt: hoe groter de kurtosis van een verdeling, hoe steiler (of scherper) deze is.
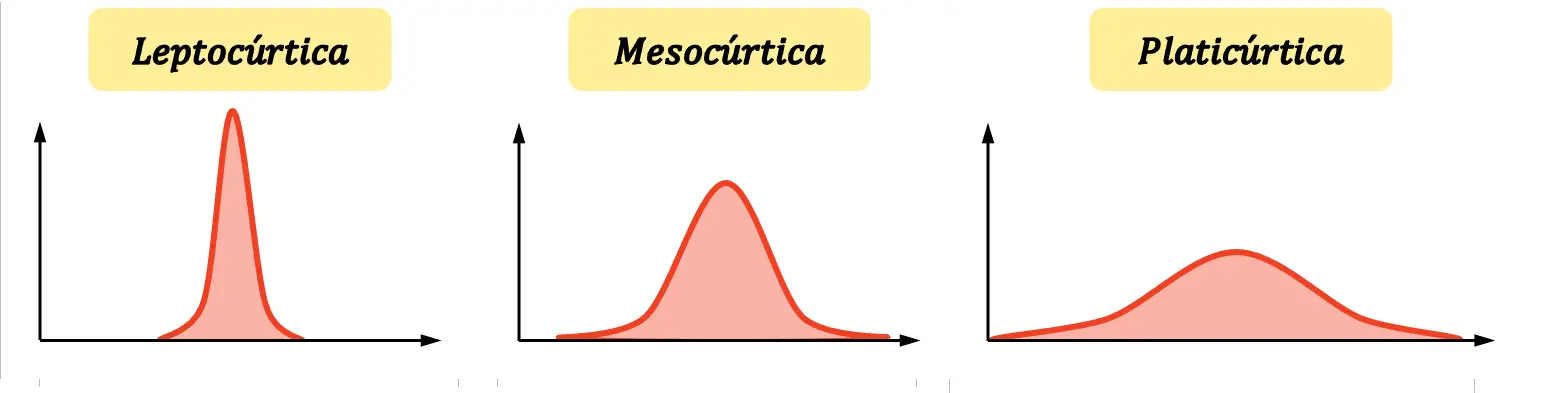
Er zijn drie soorten vleierij :
- Leptokurtisch : de verdeling is zeer puntig, dat wil zeggen dat de gegevens sterk geconcentreerd zijn rond het gemiddelde. Nauwkeuriger gezegd: leptokurtische verdelingen worden gedefinieerd als verdelingen die scherper zijn dan de normale verdeling.
- Mesokurtisch : De kurtosis van de verdeling is equivalent aan de kurtosis van de normale verdeling. Het wordt daarom als puntig of afgeplat beschouwd.
- Platicurtisch : de verdeling is zeer afgevlakt, dat wil zeggen dat de concentratie rond het gemiddelde laag is. Formeel worden platykurtische verdelingen gedefinieerd als verdelingen die vlakker zijn dan de normale verdeling.
Merk op dat de verschillende soorten kurtosis worden gedefinieerd door de kurtosis van de normale verdeling als referentie te nemen.
Afvlakkingscoëfficiënt
De formule voor de kurtosis-coëfficiënt is als volgt:

De formule voor de kurtosis-coëfficiënt voor gegevens gegroepeerd in frequentietabellen :

Tenslotte de formule voor de kurtosis-coëfficiënt voor gegevens gegroepeerd in intervallen :

Goud:
-

is de kurtosis-coëfficiënt.
-
is het totale aantal gegevens.
-
zijn de i-de gegevens in de reeks.
-
is het rekenkundig gemiddelde van de verdeling.
-
is de standaardafwijking (of typische afwijking) van de verdeling.
-
is de absolute frequentie van de it-gegevensset.
-

is het klassekenmerk van de i-de groep.
Merk op dat in alle formules voor de kurtosis-coëfficiënt 3 wordt afgetrokken omdat dit de kurtosis-waarde van de normale verdeling is. De berekening van de kurtosis-coëfficiënt wordt dus gedaan door de kurtosis van de normale verdeling als referentie te nemen. Dit is de reden waarom soms in de statistieken wordt gezegd dat overmatige kurtosis wordt berekend.
Nadat de kurtosis-coëfficiënt is berekend, moet deze als volgt worden geïnterpreteerd om te identificeren welk type kurtosis het is:
- Als de kurtosis-coëfficiënt positief is, betekent dit dat de verdeling leptokurtisch is.
- Als de kurtosis-coëfficiënt nul is, betekent dit dat de verdeling mesokurtisch is.
- Als de kurtosis-coëfficiënt negatief is, betekent dit dat de verdeling platykurtisch is.
Andere soorten statistische metingen
Mogelijk bent u ook geïnteresseerd in een van de volgende statistische metingen. Klik erop om te zien wat ze zijn en hoe ze worden berekend.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder