Wanneer gebruik je ridge & lasso-regressie?
Bij gewone meervoudige lineaire regressie gebruiken we een reeks p- voorspellingsvariabelen en een responsvariabele om in een model van de vorm te passen:
Y = β 0 + β 1 X 1 + β 2 X 2 + … + β p
De waarden van β 0 , β 1 , B 2 , …, β p worden gekozen met behulp van de kleinste kwadratenmethode, die de som van de kwadraten van de residuen (RSS) minimaliseert:
RSS = Σ(y i – ŷ i ) 2
Goud:
- Σ : Een symbool dat “som” betekent
- y i : de werkelijke responswaarde voor de i-de waarneming
- ŷ i : De voorspelde responswaarde voor de i- de waarneming
Het probleem van multicollineariteit bij regressie
Een probleem dat zich in de praktijk vaak voordoet bij meervoudige lineaire regressie is multicollineariteit – wanneer twee of meer voorspellende variabelen sterk met elkaar gecorreleerd zijn, zodat ze geen unieke of onafhankelijke informatie verschaffen in het regressiemodel.
Dit kan schattingen van modelcoëfficiënten onbetrouwbaar maken en een hoge variantie vertonen. Dat wil zeggen dat wanneer het model wordt toegepast op een nieuwe dataset die het nog nooit eerder heeft gezien, het waarschijnlijk slecht zal presteren.
Multicollineariteit vermijden: Ridge & Lasso-regressie
Twee methoden die we kunnen gebruiken om dit multicollineariteitsprobleem te omzeilen zijn ridge-regressie en lasso-regressie .
Ridge-regressie probeert het volgende te minimaliseren:
- RSS + λΣβ j 2
Lasso-regressie probeert het volgende te minimaliseren:
- RSS + λΣ|β j |
In beide vergelijkingen wordt de tweede term de opnameboete genoemd.
Wanneer λ = 0 heeft deze strafterm geen effect en leveren ridge-regressie en lasso-regressie dezelfde coëfficiëntschattingen op als de kleinste kwadraten.
Naarmate λ het oneindige nadert, wordt de krimp echter invloedrijker en nemen voorspellende variabelen die niet in het model kunnen worden geïmporteerd, af richting nul.
Met Lasso-regressie is het mogelijk dat sommige coëfficiënten volledig nul worden wanneer λ groot genoeg wordt.
Voor- en nadelen van Ridge & Lasso-regressie
Het voordeel van Ridge- en Lasso-regressie ten opzichte van regressie met de kleinste kwadraten is de afweging tussen bias en variantie .
Bedenk dat Mean Square Error (MSE) een metriek is die we kunnen gebruiken om de nauwkeurigheid van een bepaald model te meten en die als volgt wordt berekend:
MSE = Var( f̂( x 0 )) + [Bias( f̂( x 0 ))] 2 + Var(ε)
MSE = Variantie + Bias 2 + Onherleidbare fout
Het basisidee van Ridge Regressie en Lasso Regressie is om een kleine vertekening te introduceren, zodat de variantie aanzienlijk kan worden verminderd, wat leidt tot een lagere algehele MSE.
Om dit te illustreren, bekijken we de volgende grafiek:

Merk op dat naarmate λ toeneemt, de variantie aanzienlijk afneemt met een zeer kleine toename van de bias. Vanaf een bepaald punt neemt de variantie echter minder snel af en leidt de afname van de coëfficiënten tot een significante onderschatting ervan, wat leidt tot een scherpe toename van de bias.
We kunnen uit de grafiek zien dat de MSE van de test het laagst is als we een waarde voor λ kiezen die een optimale afweging tussen vertekening en variantie oplevert.
Wanneer λ = 0 heeft de strafterm bij lasso-regressie geen effect en levert daarom dezelfde coëfficiëntschattingen op als de kleinste kwadraten. Door λ echter tot een bepaald punt te verhogen, kunnen we de algehele MSE van de test verminderen.
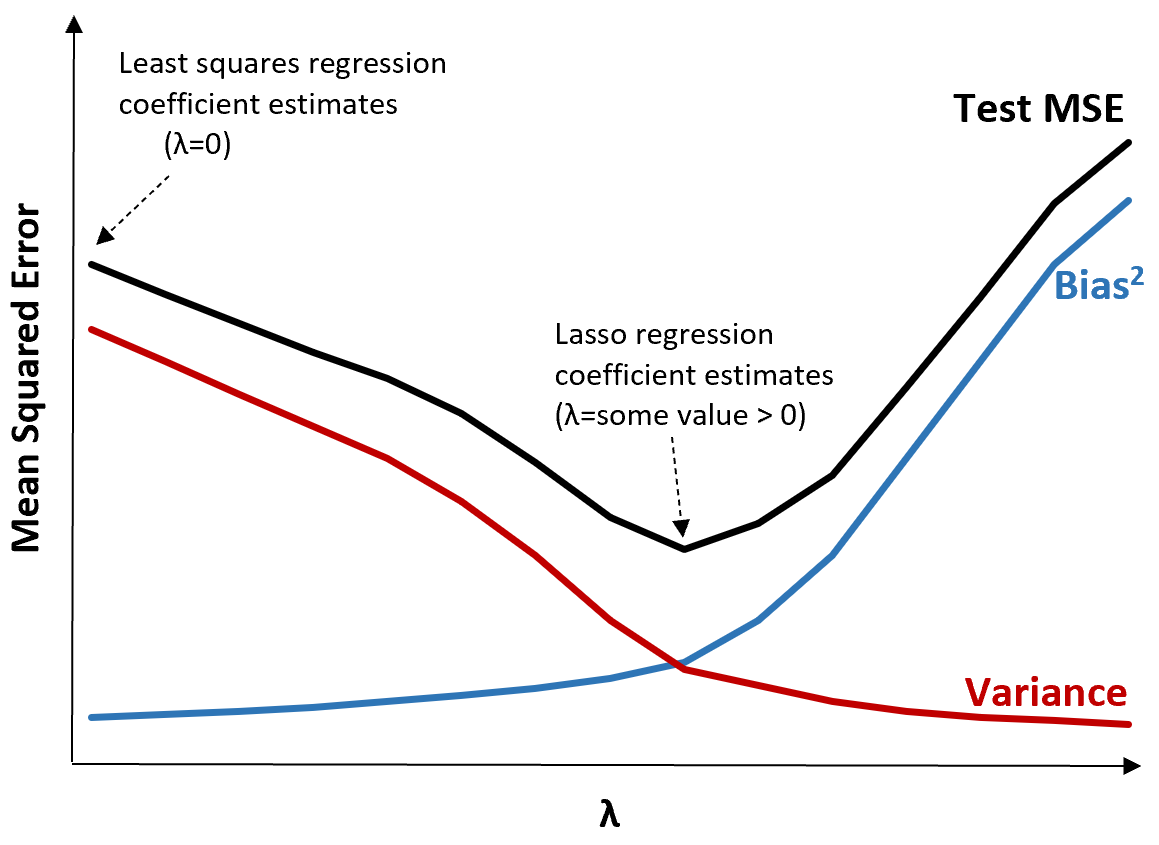
Dit betekent dat modelaanpassing door middel van ridge- en lasso-regressie mogelijk kleinere testfouten kan opleveren dan modelaanpassing door middel van regressie met de kleinste kwadraten.
Het nadeel van Ridge- en Lasso-regressie is dat het moeilijk wordt om de coëfficiënten in het uiteindelijke model te interpreteren naarmate ze kleiner worden richting nul.
Ridge- en Lasso-regressie moet dus worden gebruikt als u het voorspellende vermogen wilt optimaliseren in plaats van gevolgtrekkingen.
Ridge versus. Lasso-regressie: wanneer moet u ze gebruiken?
Lasso-regressie en ridge-regressie staan bekend als regularisatiemethoden omdat ze beide proberen de resterende kwadratensom (RSS) en een bepaalde strafterm te minimaliseren.
Met andere woorden, ze beperken of regulariseren de schattingen van de modelcoëfficiënten.
Dit roept uiteraard de vraag op: is ridge- of lasso-regressie beter?
In gevallen waarin slechts een klein aantal voorspellende variabelen significant is, werkt lasso-regressie doorgaans beter omdat het in staat is om onbelangrijke variabelen volledig tot nul terug te brengen en ze uit het model te verwijderen.
Wanneer echter veel voorspellende variabelen significant zijn in het model en hun coëfficiënten ongeveer gelijk zijn, werkt nokregressie meestal beter omdat alle voorspellers in het model blijven.
Om te bepalen welk model het beste is voor het maken van voorspellingen, voeren we doorgaans k-voudige kruisvalidatie uit en kiezen we het model dat de laagste gemiddelde kwadratische fout oplevert.
Aanvullende bronnen
De volgende tutorials bieden een inleiding tot Ridge Regressie en Lasso Regressie:
In de volgende tutorials wordt uitgelegd hoe u beide typen regressie in R en Python kunt uitvoeren:
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder