Hypothese contrast
In dit artikel wordt uitgelegd wat het testen van hypothesen in de statistiek is. Je leert dus hoe je een hypothesetest uitvoert, de verschillende soorten hypothesetests en de mogelijke fouten die gemaakt kunnen worden bij het uitvoeren van een hypothesetest.
Wat is hypothesetesten?
Een hypothesetest is een procedure die wordt gebruikt om een statistische hypothese te verwerpen of te verwerpen. Bij een hypothesetest beoordelen we of de waarde van een populatieparameter verenigbaar is met wat wordt waargenomen in een steekproef van die populatie.
Dat wil zeggen dat bij een hypothesetest een statistische steekproef wordt geanalyseerd en op basis van de verkregen resultaten wordt bepaald of een eerder vastgestelde hypothese moet worden verworpen of geaccepteerd.
Houd er rekening mee dat men uit het testen van hypothesen in het algemeen niet met volledige zekerheid kan concluderen dat een hypothese waar of onwaar is, maar dat een hypothese eenvoudigweg wordt verworpen of niet op basis van de verkregen resultaten. Bij het testen van een hypothese kan dus nog steeds een fout worden gemaakt, zelfs als er statistisch bewijs is dat de genomen beslissing het meest waarschijnlijk is.
In de statistiek wordt een hypothesetest ook wel een hypothesetest , hypothesetest of significantietest genoemd.
De theorie van het testen van hypothesen werd opgesteld door de Engelse statisticus Ronald Fisher en verder ontwikkeld door Jerzy Neyman en Egon Pearson.
Nulhypothese en alternatieve hypothese
Een hypothesetest bestaat uit twee soorten statistische hypothesen:
- Nulhypothese (H 0 ) : dit is de hypothese die stelt dat de initiële hypothese die we hebben met betrekking tot een populatieparameter onjuist is. De nulhypothese is dus de hypothese die we willen verwerpen.
- Alternatieve hypothese (H 1 ) : is de onderzoekshypothese waarvan de waarheid bewezen moet worden. Dat wil zeggen dat de alternatieve hypothese een eerdere hypothese van de onderzoeker is en om te proberen te bewijzen dat deze waar is, zal de contrasthypothese worden uitgevoerd.
In de praktijk wordt de alternatieve hypothese geformuleerd vóór de nulhypothese, aangezien het de hypothese is die moet worden bevestigd door de statistische analyse van een steekproef van gegevens. De nulhypothese wordt dan eenvoudigweg geformuleerd door de alternatieve hypothese tegen te spreken.
Soorten hypothesetoetsen
Hypothesetesten kunnen in twee verschillende typen worden ingedeeld:
- Tweezijdige hypothesetoetsing (of tweezijdige hypothesetoetsing) : De alternatieve hypothese van hypothesetoetsing stelt dat de populatieparameter “anders” is dan een specifieke waarde.
- Eenzijdige hypothesetests (of eenzijdige hypothesetests) : De alternatieve hypothese van hypothesetests geeft aan dat de populatieparameter „groter dan“ (rechterstaart) of „kleiner dan“ (linkerstaart) een specifieke waarde is.
Tweezijdige hypothesetesten
![\begin{cases}H_0: \mu=\mu_0\\[2ex]H_1:\mu\neq\mu_0\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-4f0c1b65b50009900a6facbefea23ca1_l3.png "Rendered by QuickLaTeX.com")
Eenzijdige hypothesetoetsing (rechterstaart)
![\begin{cases}H_0: \mu\leq \mu_0\\[2ex]H_1:\mu>\mu_0\end{cases}“ title=“Rendered by QuickLaTeX.com“ height=“65″ width=“102″ style=“vertical-align: 0px;“></p>
</p>
</div>
<div class=](https://statorials.org/wp-content/ql-cache/quicklatex.com-1393df603c93485a0f75ebd0116c46a2_l3.png)
Eenzijdige hypothesetoetsing (linkerstaart)
![\begin{cases}H_0: \mu\geq\mu_0\\[2ex]H_1:\mu<\mu_0\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-570fdfa44817f5392b33075476008f80_l3.png "Rendered by QuickLaTeX.com")
Afwijzingsgebied en acceptatiegebied van een hypothesetest
Zoals we hieronder in detail zullen zien, bestaat het testen van hypothesen uit het berekenen van een karakteristieke waarde van elk type hypothesetest. Deze waarde wordt hypotheseteststatistieken genoemd. Zodra de contraststatistiek is berekend, is het dus noodzakelijk om te observeren in welke van de volgende twee regio’s deze zich bevindt om tot een conclusie te komen:
- Afwijzingsgebied (of kritieke regio) : dit is het gebied van de grafiek van de referentieverdeling voor het testen van de hypothese, waarbij de nulhypothese wordt verworpen (en de alternatieve hypothese wordt geaccepteerd).
- Acceptatiegebied : dit is het gebied van de grafiek van de referentieverdeling voor het testen van de hypothese, dat acceptatie van de nulhypothese impliceert (en verwerping van de alternatieve hypothese).
Kortom, als de teststatistiek binnen de afwijzingszone valt, wordt de nulhypothese verworpen en wordt de alternatieve hypothese geaccepteerd. Integendeel, als de teststatistiek binnen het acceptatiegebied valt, wordt de nulhypothese geaccepteerd en de alternatieve hypothese verworpen.
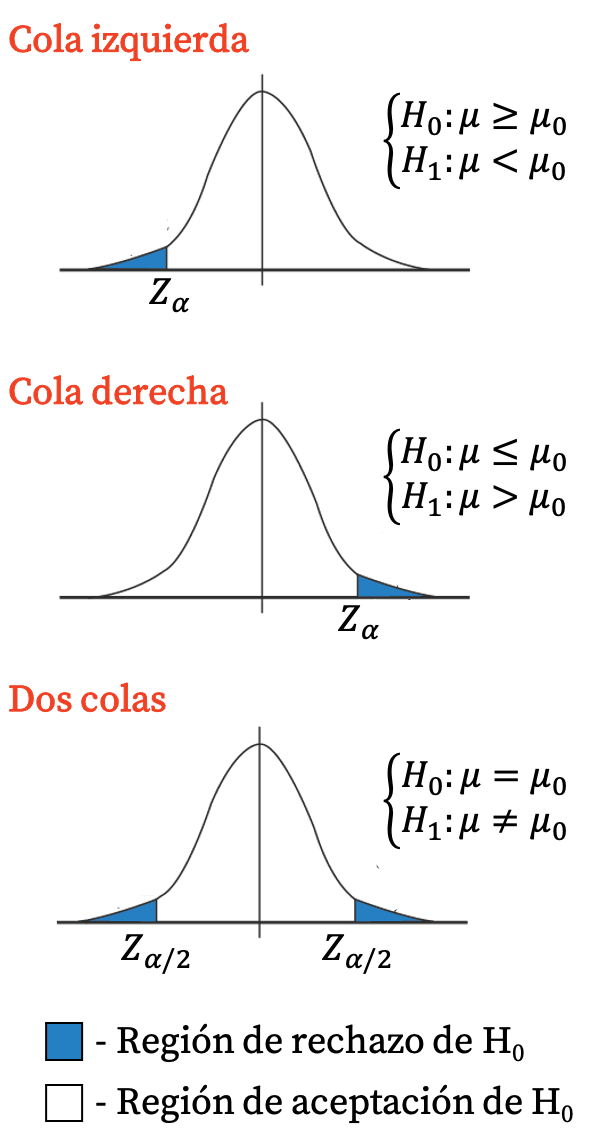
De waarden die de grenzen van het afwijzingsgebied en het acceptatiegebied bepalen, worden kritische waarden genoemd. Op dezelfde manier wordt het interval van waarden dat het afwijzingsgebied definieert, het betrouwbaarheidsinterval genoemd. En beide waarden zijn afhankelijk van het gekozen significantieniveau .
Aan de andere kant kan de beslissing om de nulhypothese te verwerpen of te accepteren ook worden genomen door de p-waarde (of p-waarde) verkregen uit de hypothesetest te vergelijken met het gekozen significantieniveau.
Hoe een hypothesetest uit te voeren
Om een hypothesetest uit te voeren, moeten de volgende stappen worden gevolgd:
- Geef de nulhypothese en de alternatieve hypothese van de hypothesetest.
- Bepaal het gewenste alfa(α)-significantieniveau.
- Bereken de hypothesecontraststatistiek.
- Bepaalt de kritische waarden van de hypothesetest om het afwijzingsgebied en acceptatiegebied van de hypothesetest te kennen.
- Observeer of de hypothesecontraststatistiek zich in het afwijzingsgebied of het acceptatiegebied bevindt.
- Als de statistiek binnen het afwijzingsgebied valt, wordt de nulhypothese verworpen (en wordt de alternatieve hypothese geaccepteerd). Maar als de statistiek binnen de acceptatiezone valt, wordt de nulhypothese geaccepteerd (en wordt de alternatieve hypothese verworpen).
➤ Zie: Hypothesetesten voor proportie
➤ Zie: Hypothesetesten op variantie
Hypothesetestfouten
Bij het testen van hypothesen kan bij het verwerpen van de ene hypothese en het accepteren van de andere testhypothese een van de volgende twee fouten worden gemaakt:
- Type I-fout : dit is de fout die wordt gemaakt bij het verwerpen van de nulhypothese terwijl deze feitelijk waar is.
- Type II-fout : dit is de fout die wordt gemaakt door de nulhypothese te accepteren terwijl deze feitelijk onwaar is.

Aan de andere kant wordt de kans op het begaan van elk type fout als volgt genoemd:
- Alfawaarschijnlijkheid (α) : is de waarschijnlijkheid dat een type I-fout wordt begaan.
- Bèta-waarschijnlijkheid (β) : is de kans op het begaan van de type II-fout.
Op dezelfde manier wordt de kracht van het testen van hypothesen gedefinieerd als de waarschijnlijkheid dat de nulhypothese (H 0 ) wordt verworpen wanneer deze onwaar is, of met andere woorden: het is de waarschijnlijkheid dat de alternatieve hypothese (H 1 ) wordt gekozen wanneer deze waar is. De kracht van de hypothesetest is daarom gelijk aan 1-β.
Hypotheseteststatistieken
De statistiek van een hypothesetest is de waarde van de referentieverdeling van de hypothesetest die wordt gebruikt om te bepalen of de nulhypothese al dan niet wordt verworpen. Als de teststatistiek in het afwijzingsgebied valt, wordt de nulhypothese verworpen (en wordt de alternatieve hypothese geaccepteerd). Als de teststatistiek daarentegen in het acceptatiegebied valt, wordt de nulhypothese geaccepteerd (en wordt de alternatieve hypothese geaccepteerd). verworpen).alternatieve hypothese).
De berekening van de hypotheseteststatistiek is afhankelijk van het type test. Daarom wordt hieronder de formule voor het berekenen van de statistiek voor elk type hypothesetoetsing weergegeven.
Hypothesetesten voor het gemiddelde
De formule voor de hypotheseteststatistiek voor het gemiddelde met bekende variantie is:

Goud:
-

is de hypothese-contraststatistiek voor het gemiddelde.
-

is het steekproefgemiddelde.
-

is de gemiddelde voorgestelde waarde.
-

is de standaarddeviatie van de populatie.
-

is de steekproefomvang.
Zodra de hypotheseteststatistiek voor het gemiddelde is berekend, moet het resultaat worden geïnterpreteerd om de nulhypothese al dan niet te verwerpen:
- Als de hypothesetest voor het gemiddelde tweezijdig is, wordt de nulhypothese verworpen als de absolute waarde van de statistiek groter is dan de kritische waarde Z α/2 .
- Als de hypothesetest voor het gemiddelde overeenkomt met de rechterstaart, wordt de nulhypothese verworpen als de statistiek groter is dan de kritische waarde Z α .
- Als de hypothesetest voor het gemiddelde overeenkomt met de linkerstaart, wordt de nulhypothese verworpen als de statistiek kleiner is dan de kritische waarde -Z α .
![\begin{array}{l}H_1: \mu\neq \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } |Z|>Z_{\alpha/2} \text{ se rechaza } H_0\\[3ex]H_1: \mu> \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } Z>Z_{\alpha} \text{ se rechaza } H_0\\[3ex]H_1: \mu< \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } Z<-Z_{\alpha} \text{ se rechaza } H_0\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-0e2ccadfc369eb7543b8f86dfccc528e_l3.png "Rendered by QuickLaTeX.com")
In dit geval worden de kritische waarden verkregen uit de gestandaardiseerde normale verdelingstabel.
Aan de andere kant is de formule voor de hypotheseteststatistiek voor het gemiddelde met onbekende variantie :

Goud:
-

is de hypotheseteststatistiek voor het gemiddelde, dat wordt gedefinieerd door de Student’s t-verdeling.
-
is het steekproefgemiddelde.
-
is de gemiddelde voorgestelde waarde.
-

is de standaardafwijking van het monster.
-
is de steekproefomvang.
Net als voorheen moet het berekende resultaat van de teststatistiek worden geïnterpreteerd met de kritische waarde om de nulhypothese al dan niet te verwerpen:
- Als de hypothesetest voor het gemiddelde tweezijdig is, wordt de nulhypothese verworpen als de absolute waarde van de statistiek groter is dan de kritische waarde t α/2|n-1 .
- Als de hypothesetest voor het gemiddelde overeenkomt met de rechterstaart, wordt de nulhypothese verworpen als de statistiek groter is dan de kritische waarde t α|n-1 .
- Als de hypothesetest voor het gemiddelde overeenkomt met de linkerstaart, wordt de nulhypothese verworpen als de statistiek kleiner is dan de kritische waarde -t α|n-1 .
![\begin{array}{l}H_1: \mu\neq \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } |t|>t_{\alpha/2|n-1} \text{ se rechaza } H_0\\[3ex]H_1: \mu> \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } t>t_{\alpha|n-1} \text{ se rechaza } H_0\\[3ex]H_1: \mu< \mu_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } t<-t_{\alpha|n-1} \text{ se rechaza } H_0\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-31fb206b75a47181c7c673f54ba28ee8_l3.png "Rendered by QuickLaTeX.com")
Wanneer de variantie onbekend is, worden de kritische testwaarden verkregen uit de verdelingstabel van de student.
Hypothese testen op proportie
De formule voor de hypotheseteststatistiek voor proportie is:

Goud:
-
is de hypotheseteststatistiek voor de proportie.
-

is de steekproefaandeel.
-

is de voorgestelde proportionele waarde.
-
is de steekproefomvang.
-

is de standaardafwijking van de verhouding.
Houd er rekening mee dat het niet voldoende is om de hypotheseteststatistiek voor het aandeel te berekenen, maar dat het resultaat vervolgens moet worden geïnterpreteerd:
- Als de hypothesetest voor de proportie tweezijdig is, wordt de nulhypothese verworpen als de absolute waarde van de statistiek groter is dan de kritische waarde Z α/2 .
- Als de hypothesetest voor de verhouding overeenkomt met de rechterstaart, wordt de nulhypothese verworpen als de statistiek groter is dan de kritische waarde Z α .
- Als de hypothesetest voor het aandeel overeenkomt met de linkerstaart, wordt de nulhypothese verworpen als de statistiek kleiner is dan de kritische waarde -Z α .
![\begin{array}{l}H_1: p\neq p_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } |Z|>Z_{\alpha/2} \text{ se rechaza } H_0\\[3ex]H_1: p> p_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } Z>Z_{\alpha} \text{ se rechaza } H_0\\[3ex]H_1: p< p_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } Z<-Z_{\alpha} \text{ se rechaza } H_0\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-7d5bd583532769e3014286e8ffd94c9f_l3.png "Rendered by QuickLaTeX.com")
Houd er rekening mee dat kritische waarden eenvoudig kunnen worden verkregen uit de standaardnormaalverdelingstabel.
Hypothesetesten voor variantie
De formule voor het berekenen van de hypotheseteststatistiek voor variantie is:

Goud:
-

is de hypotheseteststatistiek voor variantie, die een chikwadraatverdeling heeft.
-
is de steekproefomvang.
-

is de steekproefvariantie.
-

is de variantie van de voorgestelde populatie.
Om het resultaat van de statistiek te interpreteren, moet de verkregen waarde worden vergeleken met de kritische waarde van de test.
- Als de variantietest van de hypothese tweezijdig is, wordt de nulhypothese verworpen als de statistiek groter is dan de kritische waarde.

of als de kritische waarde kleiner is dan

.
- Als de hypothesetest voor de variantie overeenkomt met de rechterstaart, wordt de nulhypothese verworpen als de statistiek groter is dan de kritische waarde

.
- Als de hypothesetest voor variantie overeenkomt met de linkerstaart, wordt de nulhypothese verworpen als de statistiek kleiner is dan de kritische waarde

.
![\begin{array}{l}H_1: \sigma^2\neq \sigma_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } \chi^2>\chi^2_{1-\alpha/2|n-1}\text{ se rechaza } H_0\\[3ex]H_1: \sigma^2\neq \sigma_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si }\chi^2<\chi^2_{\alpha/2|n-1}\text{ se rechaza } H_0 \\[3ex]H_1: \sigma^2> \sigma_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } \chi^2>\chi^2_{1-\alpha|n-1}\text{ se rechaza } H_0\\[3ex]H_1: \sigma^2< \sigma_0 \ \color{orange}\bm{\longrightarrow}\color{black} \ \text{Si } \chi^2<\chi^2_{\alpha|n-1}\text{ se rechaza } H_0\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-ca46378c1a2ee04b5cc5bfa93002fe9c_l3.png "Rendered by QuickLaTeX.com")
De kritische hypothesetestwaarden voor variantie worden verkregen uit de chikwadraatverdelingstabel. Merk op dat de vrijheidsgraden voor de Chi-kwadraatverdeling de steekproefgrootte minus 1 zijn.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder