Anova-tafel
In dit artikel vindt u de uitleg van de ANOVA-tabel. Daarom leggen we u uit wat de ANOVA-tabel is, hoe u een ANOVA-tabel maakt, wat de formules van de ANOVA-tabel zijn en bovendien kunt u stap voor stap een oefening opgelost zien.
Wat is de ANOVA-tabel?
De ANOVA-tabel is een tabel die in de statistieken wordt gebruikt bij de variantieanalyse. Meer specifiek bevat de ANOVA-tabel alle informatie die nodig is voor een variantieanalyse.
Daarom wordt de ANOVA-tabel gebruikt om een variantieanalyse samen te vatten. Door de berekeningen van een variantieanalyse in een tabel uit te zetten, kunt u gemakkelijk conclusies trekken en kunt u ook snel de waarde van de ANOVA-teststatistiek berekenen.
ANOVA-tabelformules
In de eenrichtings-ANOVA-tabel zijn er drie rijen: factor, fout en totaal. In de ANOVA-tabel worden dus de som van de kwadraten van elke rij en hun vrijheidsgraden berekend. Bovendien wordt de gemiddelde kwadratische fout van de factor en de fout berekend en tenslotte wordt de ANOVA-teststatistiek bepaald, die gelijk is aan de verhouding van de kwadratische fouten.
De formules voor de ANOVA-tabel zijn daarom als volgt:
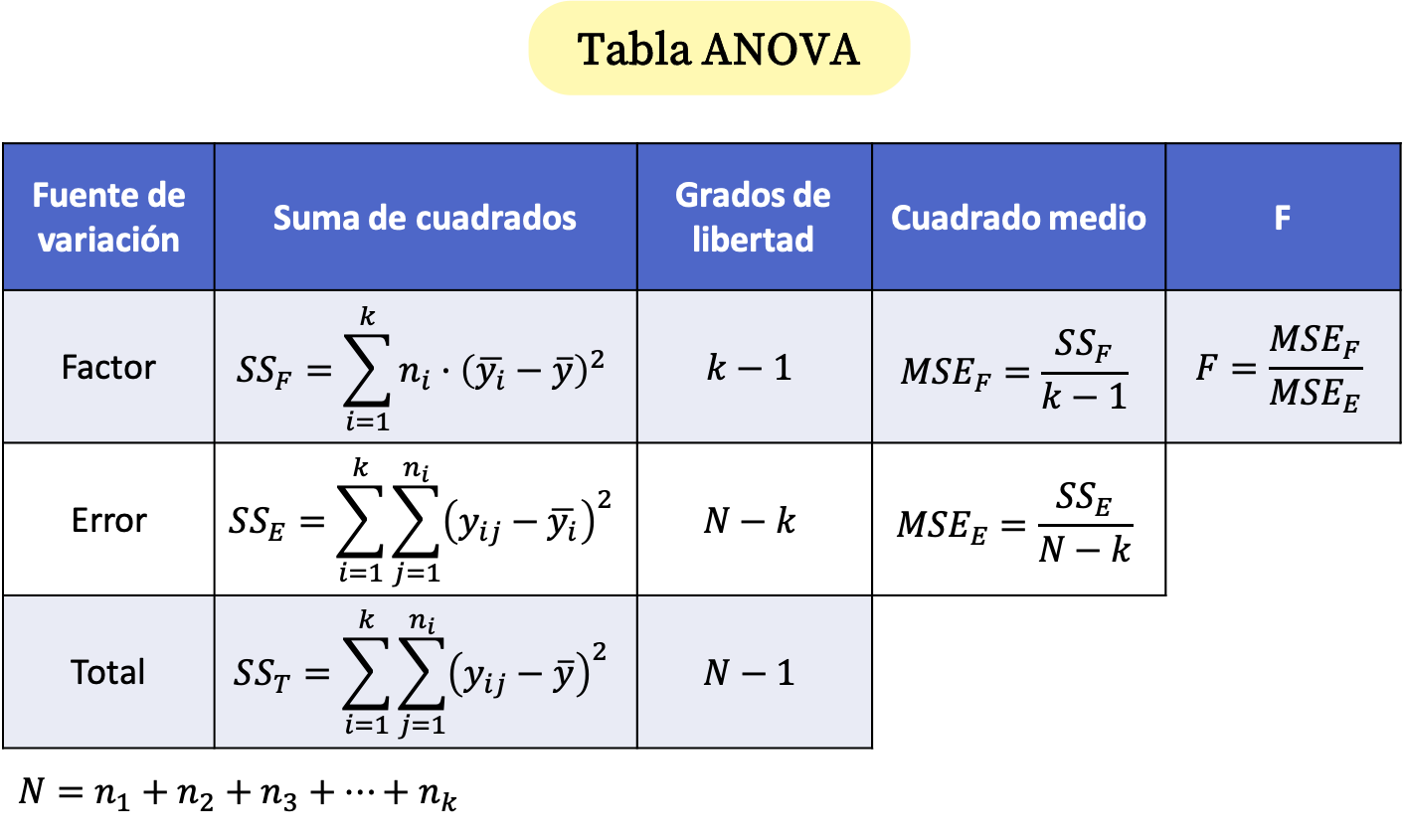
Goud:
-

is de steekproefomvang i.
-

is het totale aantal waarnemingen.
-

is het aantal verschillende groepen in de variantieanalyse.
-

is de waarde j van groep i.
-

is het gemiddelde van groep i.
-

Dit is het gemiddelde van alle geanalyseerde gegevens.
Voorbeeld van ANOVA-tabel
Om het concept goed te begrijpen, gaan we kijken hoe we een ANOVA-tabel kunnen maken door stap voor stap een voorbeeld op te lossen.
- Er wordt een statistisch onderzoek uitgevoerd om de scores van vier studenten in drie verschillende vakken (A, B en C) te vergelijken. In de volgende tabel worden de scores weergegeven die elke leerling heeft behaald op een toets waarvan de maximale score 20 is. Maak de ANOVA-tabel om de scores te vergelijken die elke leerling voor elk onderwerp heeft behaald.
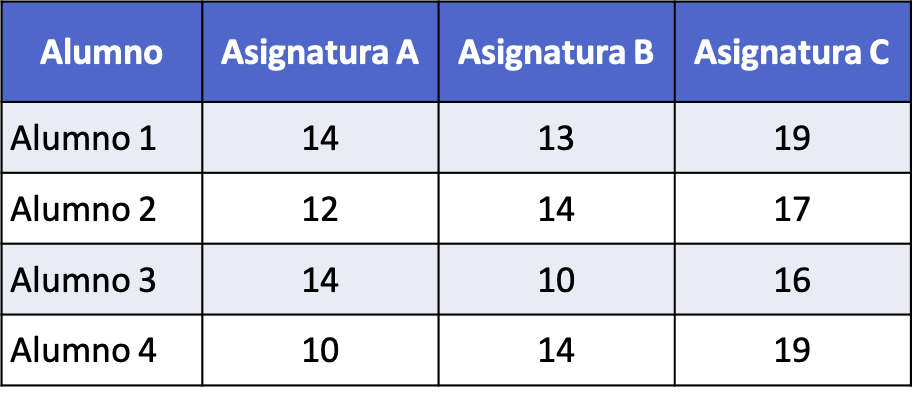
Het eerste dat we moeten doen is het gemiddelde van elk onderwerp en het totale gemiddelde van de gegevens berekenen:




Zodra we de waarde van de gemiddelden kennen, berekenen we de kwadratensommen met behulp van de formules in de ANOVA-tabel (zie hierboven):
![\begin{aligned}\displaystyle SS_F&=\sum_{i=1}^k n_i(\overline{y}_i-\overline{y})^2\\[2ex] SS_F&= 4\cdot (12,5-14,33)^2+4\cdot (12,75-14,33)^2+4\cdot (17,75-14,33)^2\\[2ex] SS_F&=70,17\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-77b3fecdc3b577841da684cd80297288_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_E=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y}_i)^2\\[2ex] \displaystyle SS_E=\ &(14-12,5)^2+(12-12,5)^2+(14-12,5)^2+(10-12,5)^2+\\&+(13-12,75)^2+(14-12,75)^2+(10-12,75)^2+(14-12,75)^2+\\&+(19-17,75)^2+(17-17,75)^2+(16-17,75)^2+(19-17,75)^2\\[2ex] SS_E=\ &28,50\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-aa02f1b826df45c26ead3537ecc4c7e5_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_T=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y})^2\\[2ex] \displaystyle SS_T= \ &(14-14,33)^2+(12-14,33)^2+(14-14,33)^2+(10-14,33)^2+\\&+(13-14,33)^2+(14-14,33)^2+(10-14,33)^2+(14-14,33)^2+\\&+(19-14,33)^2+(17-14,33)^2+(16-14,33)^2+(19-14,33)^2\\[2ex] SS_T= \ &98,67\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-2eb66d1d37653749f38916c905108a3b_l3.png "Rendered by QuickLaTeX.com")
Vervolgens bepalen we de vrijheidsgraden van de factor, de fout en het totaal:



We berekenen nu de gemiddelde kwadratische fouten door de som van de kwadraten van de factor en de fout te delen door hun respectieve vrijheidsgraden:


En ten slotte berekenen we de waarde van de F-statistiek door de twee fouten te delen die in de vorige stap zijn berekend:

Kort gezegd zou de ANOVA-tabel voor de voorbeeldgegevens er als volgt uitzien:

Zodra alle waarden in de ANOVA-tabel zijn berekend, hoeft u deze alleen nog maar te interpreteren. Om dit te doen, moeten we de waarschijnlijkheid vergelijken die overeenkomt met de waarde van de F-statistiek, de zogenaamde p-waarde. Hoe u dit doet, kunt u zien door op de volgende link te klikken:
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder