Variantieanalyse (anova)
In dit artikel wordt uitgelegd wat variantieanalyse, ook bekend als ANOVA, in de statistiek is. Je ontdekt dus hoe je een variantieanalyse uitvoert, wat de ANOVA-tabel is en een stap-voor-stap opgeloste oefening. Bovendien laat het zien wat de voorafgaande aannames zijn die moeten worden gerespecteerd om een variantieanalyse uit te voeren en, ten slotte, wat de voor- en nadelen van ANOVA-analyse zijn.
Wat is variantieanalyse (ANOVA)?
In de statistiek is variantieanalyse , ook wel ANOVA (variantieanalyse) genoemd, een techniek waarmee u de varianties tussen de gemiddelden van verschillende steekproeven kunt vergelijken.
Variantieanalyse (ANOVA) wordt gebruikt om te analyseren of er een verschil is tussen de gemiddelden van meer dan twee populaties. Variantieanalyse stelt ons dus in staat te bepalen of de populatiegemiddelden van twee of meer groepen verschillend zijn door de variabiliteit tussen de steekproefgemiddelden te analyseren.
De nulhypothese van de variantieanalyse is daarom dat de gemiddelden van alle geanalyseerde groepen gelijk zijn. Terwijl de alternatieve hypothese stelt dat ten minste één van de middelen anders is.
![\begin{cases}H_0: \mu_1=\mu_2=\ldots=\mu_k=\mu\\[2ex]H_1: \exists \mu_i\neq \mu \quad i=1,2,\ldots, k\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-6918550a8ad2954432ea33e07c7b83d0_l3.png "Rendered by QuickLaTeX.com")
Variantieanalyse is dus vooral nuttig voor het vergelijken van de gemiddelden van meer dan twee groepen, omdat je met dit type analyse de gemiddelden van alle groepen tegelijkertijd kunt bestuderen, in plaats van de gemiddelden in paren te vergelijken. Hieronder zullen we zien wat de voor- en nadelen van variantieanalyse zijn.
ANOVA-tafel
De variantieanalyse is samengevat in een tabel genaamd de ANOVA-tabel , waarvan de formules als volgt zijn:
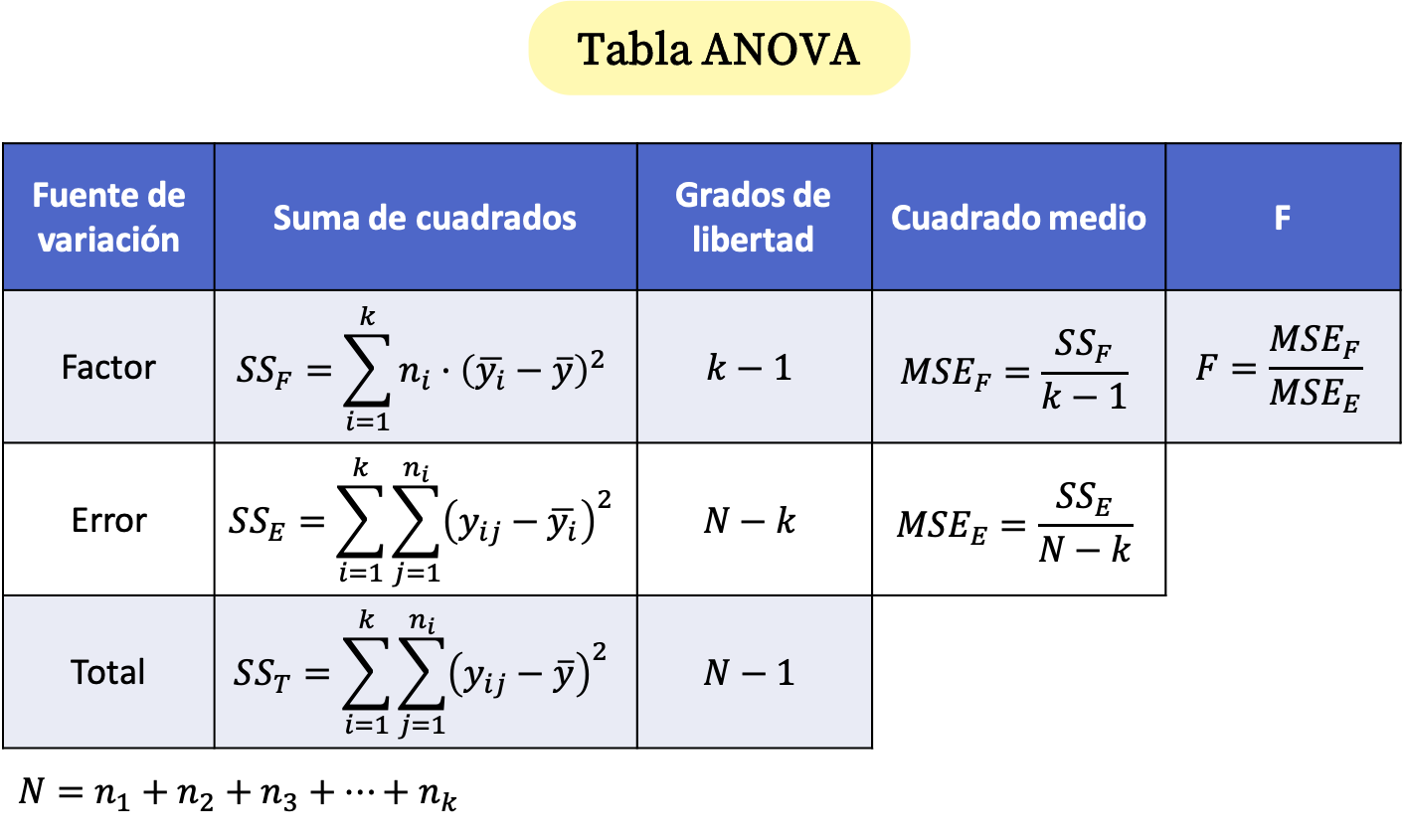
Goud:
-

is de steekproefomvang i.
-

is het totale aantal waarnemingen.
-

is het aantal verschillende groepen in de variantieanalyse.
-

is de waarde j van groep i.
-

is het gemiddelde van groep i.
-

Dit is het gemiddelde van alle geanalyseerde gegevens.
Voorbeeld van variantieanalyse (ANOVA)
Laten we, om het begrip ANOVA af te ronden, kijken hoe we variantieanalyse kunnen uitvoeren door stap voor stap een voorbeeld op te lossen.
- Er wordt een statistisch onderzoek uitgevoerd om de scores van vier studenten in drie verschillende vakken (A, B en C) te vergelijken. In de volgende tabel worden de scores weergegeven die elke leerling heeft behaald op een toets met een maximale score van 20. Voer een variantieanalyse uit om de scores te vergelijken die elke leerling voor elk vak heeft behaald.
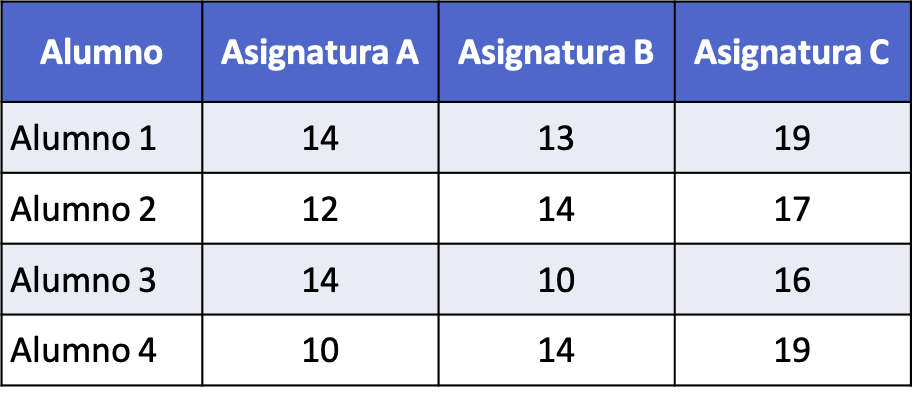
De nulhypothese van deze variantieanalyse is dat de gemiddelden van de scores van de drie onderwerpen gelijk zijn. Aan de andere kant is de nulhypothese dat sommige van deze gemiddelden verschillend zijn.
![\begin{cases}H_0: \mu_A=\mu_B=\mu_C=\mu\\[2ex]H_1: \exists \mu_i\neq \mu \quad i=A, B, C\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-d1587da405a54d6a2bae626989b04562_l3.png "Rendered by QuickLaTeX.com")
Om de variantieanalyse uit te voeren, moet u eerst het gemiddelde van elk onderwerp en het totale gemiddelde van de gegevens berekenen:




Zodra we de waarde van de gemiddelden kennen, berekenen we de kwadratensommen met behulp van de hierboven weergegeven formules voor variantieanalyse (ANOVA):
![\begin{aligned}\displaystyle SS_F&=\sum_{i=1}^k n_i(\overline{y}_i-\overline{y})^2\\[2ex] SS_F&= 4\cdot (12,5-14,33)^2+4\cdot (12,75-14,33)^2+4\cdot (17,75-14,33)^2\\[2ex] SS_F&=70,17\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-77b3fecdc3b577841da684cd80297288_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_E=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y}_i)^2\\[2ex] \displaystyle SS_E=\ &(14-12,5)^2+(12-12,5)^2+(14-12,5)^2+(10-12,5)^2+\\&+(13-12,75)^2+(14-12,75)^2+(10-12,75)^2+(14-12,75)^2+\\&+(19-17,75)^2+(17-17,75)^2+(16-17,75)^2+(19-17,75)^2\\[2ex] SS_E=\ &28,50\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-aa02f1b826df45c26ead3537ecc4c7e5_l3.png "Rendered by QuickLaTeX.com")
![\begin{aligned}\displaystyle SS_T=&\sum_{i=1}^k\sum_{j=1}^{n_i} (y_{ij}-\overline{y})^2\\[2ex] \displaystyle SS_T= \ &(14-14,33)^2+(12-14,33)^2+(14-14,33)^2+(10-14,33)^2+\\&+(13-14,33)^2+(14-14,33)^2+(10-14,33)^2+(14-14,33)^2+\\&+(19-14,33)^2+(17-14,33)^2+(16-14,33)^2+(19-14,33)^2\\[2ex] SS_T= \ &98,67\end{aligned}](https://statorials.org/wp-content/ql-cache/quicklatex.com-2eb66d1d37653749f38916c905108a3b_l3.png "Rendered by QuickLaTeX.com")
Vervolgens bepalen we de vrijheidsgraden van de factor, de fout en het totaal:



We berekenen nu de gemiddelde kwadratische fouten door de som van de kwadraten van de factor en de fout te delen door hun respectieve vrijheidsgraden:


En ten slotte berekenen we de waarde van de F-statistiek door de twee fouten te delen die in de vorige stap zijn berekend:

Kort gezegd zou de ANOVA-tabel voor de voorbeeldgegevens er als volgt uitzien:

Zodra alle waarden in de ANOVA-tabel zijn berekend, hoeft u alleen nog maar de verkregen resultaten te interpreteren. Om dit te doen, moeten we de waarschijnlijkheid vinden om een waarde te verkrijgen die groter is dan de F-statistiek in een Snedecor F-verdeling met de overeenkomstige vrijheidsgraden, dat wil zeggen dat we de p-waarde van de test moeten bepalen:
![P[F>11,08]=0,004″ title=“Rendered by QuickLaTeX.com“ height=“18″ width=“172″ style=“vertical-align: -5px;“></p>
</p>
<p> Als we daarom een significantieniveau α=0,05 nemen (het meest voorkomende), moeten we de nulhypothese verwerpen en de alternatieve hypothese accepteren, aangezien de p-waarde van de test lager is dan het significantieniveau. Dit betekent dat in ieder geval een deel van de gemiddelden van de onderzochte groepen verschilt van die van andere.</p>
</p>
<p class=](https://statorials.org/wp-content/ql-cache/quicklatex.com-b706e5d710c3919d145399dc9d8efca5_l3.png)

Opgemerkt moet worden dat er momenteel verschillende computerprogramma’s zijn die in slechts enkele seconden een variantieanalyse kunnen uitvoeren. Het is echter ook belangrijk om de theorie achter de berekeningen te kennen.
Aannames van variantieanalyse (ANOVA)
Om een variantieanalyse (ANOVA) uit te voeren, moet aan de volgende voorwaarden worden voldaan:
- Onafhankelijkheid : de waargenomen waarden zijn onafhankelijk van elkaar. Eén manier om de onafhankelijkheid van waarnemingen te garanderen, is door willekeur aan het steekproefproces toe te voegen.
- Homoscedasticiteit : er moet homogeniteit zijn in de varianties, dat wil zeggen dat de variabiliteit van de residuen constant is.
- Normaliteit : De residuen moeten normaal verdeeld zijn, of met andere woorden, ze moeten een normale verdeling volgen.
- Continuïteit : De afhankelijke variabele moet continu zijn.
Soorten variantieanalyse (ANOVA)
Er zijn drie soorten variantieanalyse (ANOVA) :
- Eénrichtingsvariantieanalyse (éénrichtings-ANOVA) : Bij variantieanalyse is er slechts één factor, dwz er is slechts één onafhankelijke variabele.
- Tweerichtingsvariantieanalyse (tweerichtings-ANOVA) : Variantieanalyse heeft twee factoren, dus twee onafhankelijke variabelen en de interactie daartussen worden geanalyseerd.
- Multivariate variantieanalyse (MANOVA) : Bij variantieanalyse is er meer dan één afhankelijke variabele. Het doel is om te bepalen of de onafhankelijke variabelen hun waarde veranderen wanneer de afhankelijke variabelen variëren.
Voor- en nadelen van variantieanalyse (ANOVA)
Ten slotte zullen we zien wanneer het voor ons gepast is om variantieanalyse te gebruiken en ook wat de grenzen zijn van dit soort statistische analyse.
Het belangrijkste voordeel van variantieanalyse (ANOVA) is dat er meer dan twee groepen tegelijkertijd kunnen worden vergeleken. In tegenstelling tot de t-test , waarbij u slechts het gemiddelde van één of twee steekproeven kunt analyseren, wordt variantieanalyse gebruikt om te bepalen of meerdere populaties al dan niet hetzelfde gemiddelde hebben.
Variantieanalyse vertelt ons echter niet welke studiegroep een ander gemiddelde heeft; het laat ons alleen weten of er significant verschillende gemiddelden zijn of dat alle gemiddelden vergelijkbaar zijn.
Op dezelfde manier is een ander nadeel van variantieanalyse dat aan vier eerdere aannames (zie hierboven) moet worden voldaan om de ANOVA-analyse uit te voeren, anders kunnen de getrokken conclusies verkeerd zijn. Daarom moet altijd worden geverifieerd dat de statistische dataset aan deze vier vereisten voldoet.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder