Regressievergelijking
In dit artikel wordt uitgelegd wat een regressievergelijking is en waarvoor deze wordt gebruikt. Op dezelfde manier leer je hoe je een regressievergelijking kunt vinden, een opgeloste oefening en ten slotte een online rekenmachine om de regressievergelijking voor elke dataset te berekenen.
Wat is de regressievergelijking?
De regressievergelijking is de vergelijking die het beste past bij een puntendiagram, dat wil zeggen dat de regressievergelijking de beste benadering is van een reeks gegevens.
De regressievergelijking heeft de vorm y=β 0 +β 1 x, waarbij β 0 de constante van de vergelijking is en β 1 de helling van de vergelijking.

Als je naar de regressievergelijking kijkt, is het de vergelijking van een lijn. Dit betekent dat de relatie tussen onafhankelijke variabele X en afhankelijke variabele Y wordt gemodelleerd als een lineaire relatie, aangezien de lijn een lineaire relatie vertegenwoordigt.
De regressievergelijking stelt ons dus in staat om de onafhankelijke variabele en de afhankelijke variabele van een dataset wiskundig met elkaar in verband te brengen. Hoewel de regressievergelijking doorgaans niet in staat is om de waarde van elke waarneming nauwkeurig te bepalen, wordt deze toch gebruikt om een benadering van de waarde ervan te verkrijgen.
Zoals u in het vorige diagram kunt zien, helpt de regressievergelijking ons de trend van een dataset te zien en welk type relatie er bestaat tussen de onafhankelijke variabele en de afhankelijke variabele.
Hoe de regressievergelijking te berekenen
De formules voor het berekenen van de coëfficiënten van de eenvoudige lineaire regressievergelijking zijn als volgt:
![\begin{array}{c}\beta_1=\cfrac{\displaystyle \sum_{i=1}^n (x_i-\overline{x})(y_i-\overline{y})}{\displaystyle \sum_{i=1}^n (x_i-\overline{x})^2}\\[12ex]\beta_0=\overline{y}-\beta_1\overline{x}\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-459281504d26f92756115054ef567021_l3.png "Rendered by QuickLaTeX.com")
Goud:
-

is de constante van de regressievergelijking.
-

is de helling van de regressievergelijking.
-

is de waarde van de onafhankelijke variabele X van gegevens i.
-

is de waarde van de afhankelijke variabele Y van gegevens i.
-

is het gemiddelde van de waarden van de onafhankelijke variabele
-

is het gemiddelde van de waarden van de afhankelijke variabele Y.
Voorbeeld van het berekenen van de regressievergelijking
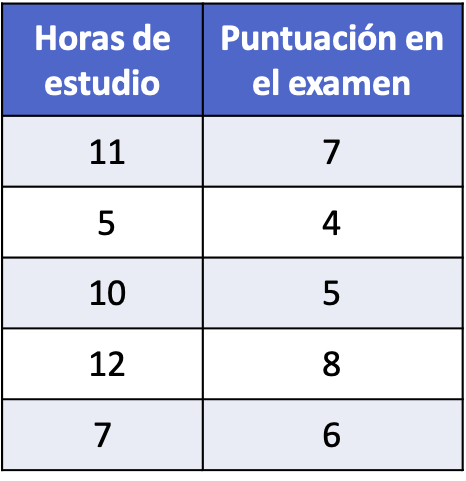
- Na het afleggen van een statistiektentamen is aan vijf studenten gevraagd hoeveel uren studie ze aan het tentamen hebben besteed, de gegevens staan in onderstaande tabel. Bereken de regressievergelijking op basis van de verzamelde statistische gegevens om de studie-uren lineair te relateren aan het behaalde cijfer. Bepaal vervolgens welk cijfer een leerling die 8 uur heeft gestudeerd krijgt.
Om de regressievergelijking voor de voorbeeldgegevens te vinden, moeten we de coëfficiënten b 0 en b 1 van de vergelijking bepalen en om dit te doen moeten we de formules gebruiken die we in het bovenstaande gedeelte hebben gezien.
Om de formules voor de lineaire regressievergelijking echter toe te passen, moeten we eerst het gemiddelde van de onafhankelijke variabele en het gemiddelde van de afhankelijke variabele berekenen:
![\begin{array}{c}\overline{x}=\cfrac{11+5+10+12+7}{5}=9\\[4ex]\overline{y}=\cfrac{7+4+5+8+6}{5}=6\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-7a7aa6f1f20fa4ff0d61a2ad0dd2ea1f_l3.png "Rendered by QuickLaTeX.com")
Nu we de gemiddelden van de variabelen kennen, berekenen we de coëfficiënt β 1 van het model met behulp van de bijbehorende formule:
![\begin{array}{c}\beta_1=\cfrac{\displaystyle \sum_{i=1}^n (x_i-\overline{x})(y_i-\overline{y})}{\displaystyle \sum_{i=1}^n (x_i-\overline{x})^2}\\[10ex] \beta_1=\cfrac{\begin{array}{c}(11-9)(7-6)+(5-9)(4-6)+(10-9)(5-6)+\\+(12-9)(8-6)+(7-9)(6-6)\end{array}}{(11-9)^2+(5-9)^2+(10-9)^2+(12-9)^2+(7-9)^2}\\[6ex]\beta_1=0,4412\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-d9407478d6d590c0d970ac41963f6fbe_l3.png "Rendered by QuickLaTeX.com")
Ten slotte berekenen we de coëfficiënt β 0 van het model met behulp van de bijbehorende formule:
![\begin{array}{l}\beta_0=\overline{y}-\beta_1\overline{x}\\[3ex]\beta_0=6-0,4412\cdot 9 \\[3ex]\beta_0=2,0294\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-a8872fb5b9904b106d02b504ae36bb92_l3.png "Rendered by QuickLaTeX.com")
Kort gezegd is de vergelijking van de lineaire regressielijn van het probleem als volgt:

Hieronder ziet u de grafische weergave van de voorbeeldgegevens samen met de eenvoudige lineaire regressiemodelvergelijking:
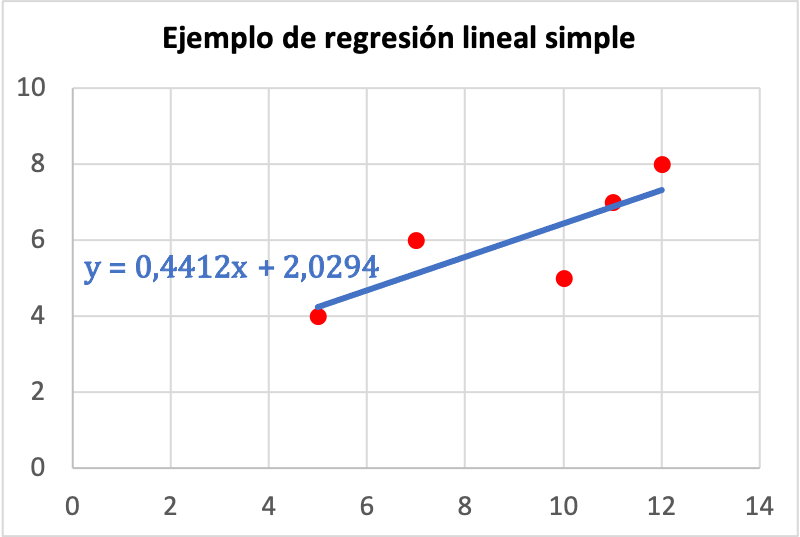
Nadat we de regressievergelijking hebben berekend, kunt u, om het cijfer te voorspellen dat een leerling die 8 uur heeft gestudeerd, deze waarde zal behalen eenvoudigweg deze waarde in de resulterende regressievergelijking invullen:

Volgens het uitgevoerde lineaire regressiemodel krijgt een student dus een score van 5,56 op het examen als hij acht uur heeft gestudeerd.
Regressievergelijking rekenmachine
Voer een voorbeeldgegevens in de onderstaande rekenmachine in om uw regressievergelijking te berekenen. U moet de gegevensparen scheiden, zodat in het eerste vak alleen de waarden van de onafhankelijke variabele X staan en in het tweede vak alleen de waarden van de afhankelijke variabele Y.
Gegevens moeten worden gescheiden door een spatie en moeten worden ingevoerd met de punt als decimaal scheidingsteken.
Meerdere lineaire regressievergelijkingen
We hebben zojuist gezien wat de eenvoudige lineaire regressievergelijking is, maar het regressiemodel kan ook een meervoudig lineair regressiemodel zijn, dat twee of meer onafhankelijke variabelen omvat. Meervoudige lineaire regressie maakt het dus mogelijk om meerdere verklarende variabelen lineair aan een responsvariabele te koppelen.
De vergelijking voor het meervoudige lineaire regressiemodel is:

Goud:
-

is de afhankelijke variabele.
-
is de onafhankelijke variabele i.
-
is de constante van de meervoudige lineaire regressievergelijking.
-

is de regressiecoëfficiënt die aan de variabele is gekoppeld
.
-

is de fout of het residu, dat wil zeggen het verschil tussen de waargenomen waarde en de door het model geschatte waarde.
-

is het totale aantal variabelen in het model.
Dus als we een monster hebben met een totaal van

observaties kunnen we het meervoudige lineaire regressiemodel in matrixvorm opstellen:

De bovenstaande matrixuitdrukking kan worden herschreven door aan elke matrix een letter toe te wijzen:

Door het kleinste kwadratencriterium toe te passen, kunnen we dus tot de formule komen voor het schatten van de coëfficiënten van een meervoudige lineaire regressievergelijking :

De toepassing van deze formule is echter zeer omslachtig en tijdrovend. Daarom wordt in de praktijk aanbevolen om computersoftware (zoals Minitab of Excel) te gebruiken waarmee u veel sneller een meervoudig regressiemodel kunt maken.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder