Hoe residuen in regressieanalyse te berekenen
Eenvoudige lineaire regressie is een statistische methode die u kunt gebruiken om de relatie tussen twee variabelen, x en y, te begrijpen.
Een variabele, x , staat bekend als een voorspellende variabele. De andere variabele, y , staat bekend als deresponsvariabele .
Stel dat we bijvoorbeeld de volgende gegevensset hebben met het gewicht en de lengte van zeven individuen:
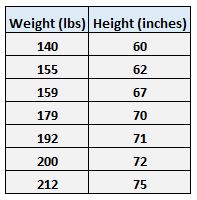
Laat gewicht de voorspellende variabele zijn en laat lengte de responsvariabele zijn.
Als we deze twee variabelen grafisch weergeven met behulp van een spreidingsdiagram , met het gewicht op de x-as en de hoogte op de y-as, ziet het er zo uit:
Uit het spreidingsdiagram kunnen we duidelijk zien dat naarmate het gewicht toeneemt, de lengte ook de neiging heeft toe te nemen, maar om deze relatie tussen gewicht en lengte daadwerkelijk te kwantificeren moeten we lineaire regressie gebruiken.
Met behulp van lineaire regressie kunnen we de lijn vinden die het beste bij onze gegevens past:
De formule voor deze lijn met de beste pasvorm is geschreven:
ŷ = b0 + b1 x
waarbij ŷ de voorspelde waarde van de responsvariabele is, b 0 het snijpunt is, b 1 de regressiecoëfficiënt is en x de waarde van de voorspellende variabele is.
In dit voorbeeld is de best passende regel:
maat = 32.783 + 0.2001*(gewicht)
Hoe residuen te berekenen
Merk op dat de gegevenspunten in ons spreidingsdiagram niet altijd exact overeenkomen met de lijn die het beste past:
Dit verschil tussen het datapunt en de lijn wordt het residu genoemd. Voor elk gegevenspunt kunnen we het residu van dat punt berekenen door het verschil tussen de werkelijke waarde en de voorspelde waarde uit de best passende lijn te halen.
Voorbeeld 1: Berekening van een residu
Denk bijvoorbeeld aan het gewicht en de lengte van de zeven individuen in onze dataset:
Het eerste individu weegt 140 pond. en een hoogte van 60 centimeter.
Om de verwachte lengte van deze persoon te achterhalen, kunnen we zijn gewicht in de lijn van de best passende vergelijking plaatsen:
maat = 32.783 + 0.2001*(gewicht)
De voorspelde grootte van dit individu is dus:
hoogte = 32,783 + 0,2001*(140)
hoogte = 60,797 inch
Het residu voor dit gegevenspunt is dus 60 – 60,797 = -0,797 .
Voorbeeld 2: Berekening van een residu
We kunnen exact hetzelfde proces gebruiken als hierboven om het residu voor elk gegevenspunt te berekenen. Laten we bijvoorbeeld het residu berekenen voor het tweede individu in onze dataset:
Het tweede individu weegt 155 pond. en een hoogte van 62 inch.
Om de verwachte lengte van deze persoon te achterhalen, kunnen we zijn gewicht in de lijn van de best passende vergelijking plaatsen:
maat = 32.783 + 0.2001*(gewicht)
De voorspelde grootte van dit individu is dus:
hoogte = 32,783 + 0,2001*(155)
hoogte = 63,7985 inch
Het residu voor dit gegevenspunt is dus 62 – 63,7985 = -1,7985 .
Bereken alle residuen
Met dezelfde methode als de vorige twee voorbeelden kunnen we de residuen voor elk gegevenspunt berekenen:
Merk op dat sommige residuen positief zijn en andere negatief. Als we alle residuen bij elkaar optellen, is hun totaal nul.
Dit komt omdat lineaire regressie de lijn vindt die het totale kwadraat van de residuen minimaliseert. Daarom gaat de lijn perfect door de gegevens, waarbij sommige gegevenspunten boven de lijn liggen en andere onder de lijn.
Bekijk residuen
Houd er rekening mee dat een residu eenvoudigweg de afstand is tussen de werkelijke waarde van de gegevens en de waarde die wordt voorspeld door de best passende regressielijn. Hier ziet u hoe deze afstanden er visueel uitzien op een puntenwolk:
Houd er rekening mee dat sommige residuen groter zijn dan andere. Bovendien zijn sommige residuen positief en andere negatief, zoals we eerder vermeldden.
Een restpad creëren
Het punt van het berekenen van residuen is om te zien hoe goed de regressielijn bij de gegevens past.
Grotere residuen geven aan dat de regressielijn niet goed bij de gegevens past, dat wil zeggen dat de feitelijke gegevenspunten de regressielijn niet benaderen.
Kleinere residuen geven aan dat de regressielijn beter bij de gegevens past, dat wil zeggen dat de feitelijke gegevenspunten dichter bij de regressielijn liggen.
Een handig type plot om alle residuen in één keer te visualiseren is een residuenplot. Een residuele plot is een type plot dat voorspelde waarden versus residuen voor een regressiemodel weergeeft.
Dit type plot wordt vaak gebruikt om te evalueren of een lineair regressiemodel al dan niet geschikt is voor een bepaalde dataset en om de heteroskedasticiteit van de residuen te controleren.
Bekijk deze tutorial om te leren hoe u een residuele plot maakt voor een eenvoudig lineair regressiemodel in Excel.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder