Hoe u een chi square fit-test uitvoert in excel
Een chikwadraat-goodness-of-fit-test wordt gebruikt om te bepalen of een categorische variabele al dan niet een hypothetische verdeling volgt.
In deze zelfstudie wordt uitgelegd hoe u een chikwadraat-goodness-of-fit-test uitvoert in Excel.
Voorbeeld: Chi-kwadraat goodness-of-fit-test in Excel
Een winkeleigenaar vertelt dat er elke dag van de week evenveel klanten naar zijn winkel komen. Om deze hypothese te testen, registreert een onafhankelijke onderzoeker het aantal klanten dat in een bepaalde week de winkel binnenkomt en ontdekt het volgende:
- Maandag: 50 klanten
- Dinsdag: 60 klanten
- Woensdag: 40 klanten
- Donderdag: 47 klanten
- Vrijdag: 53 klanten
We zullen de volgende stappen gebruiken om een chikwadraat-goodness-of-fit-test uit te voeren om te bepalen of de gegevens consistent zijn met de claim van de winkeleigenaar.
Stap 1: Voer de gegevens in.
Eerst voeren we de gegevenswaarden voor het verwachte aantal klanten per dag in één kolom in en het waargenomen aantal klanten per dag in een andere kolom:
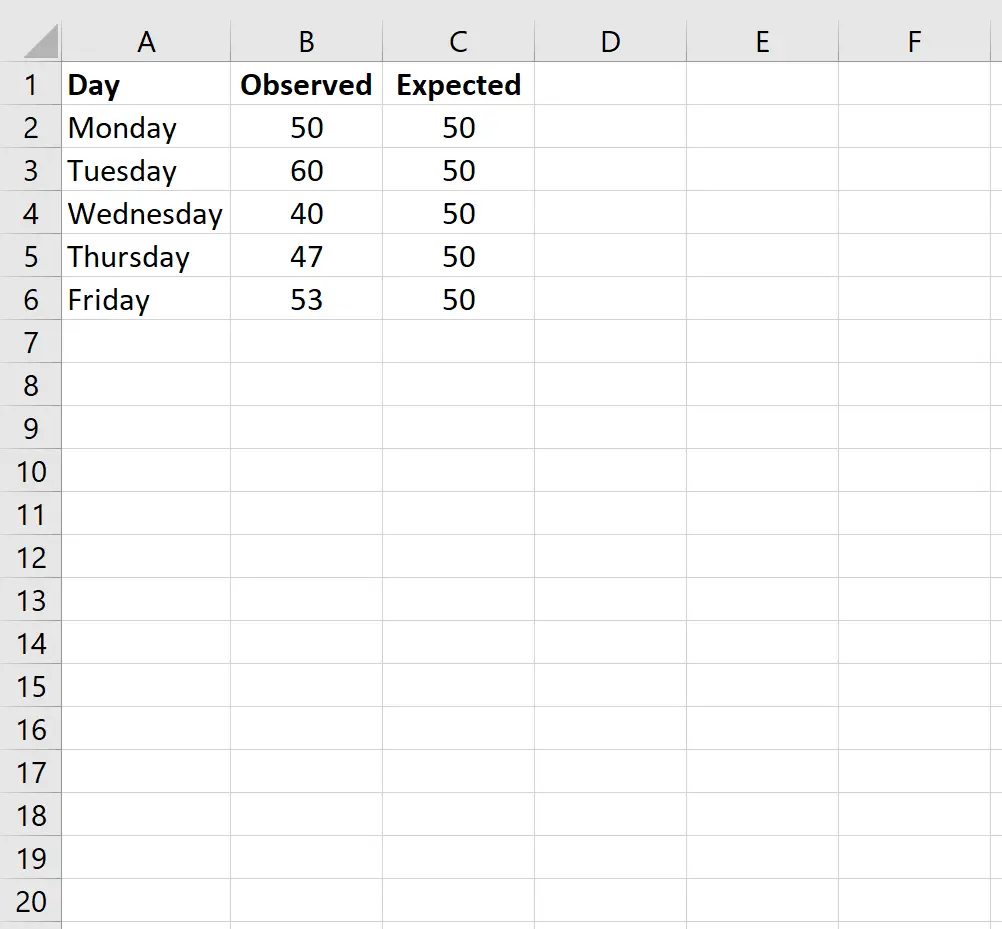
Let op: Er waren in totaal 250 klanten. Dus als de winkeleigenaar verwacht dat er elke dag een gelijk aantal klanten de winkel binnenkomt, verwacht hij 50 klanten per dag.
Stap 2: Zoek het verschil tussen de waargenomen en verwachte waarden.
De Chi-kwadraatteststatistiek voor de goodness-of-fit-test is X 2 = Σ(OE) 2 / E.
Goud:
- Σ: is een mooi symbool dat “som” betekent
- O: waargenomen waarde
- E: verwachte waarde
De volgende formule laat zien hoe u (OE) 2 /E voor elke rij berekent:
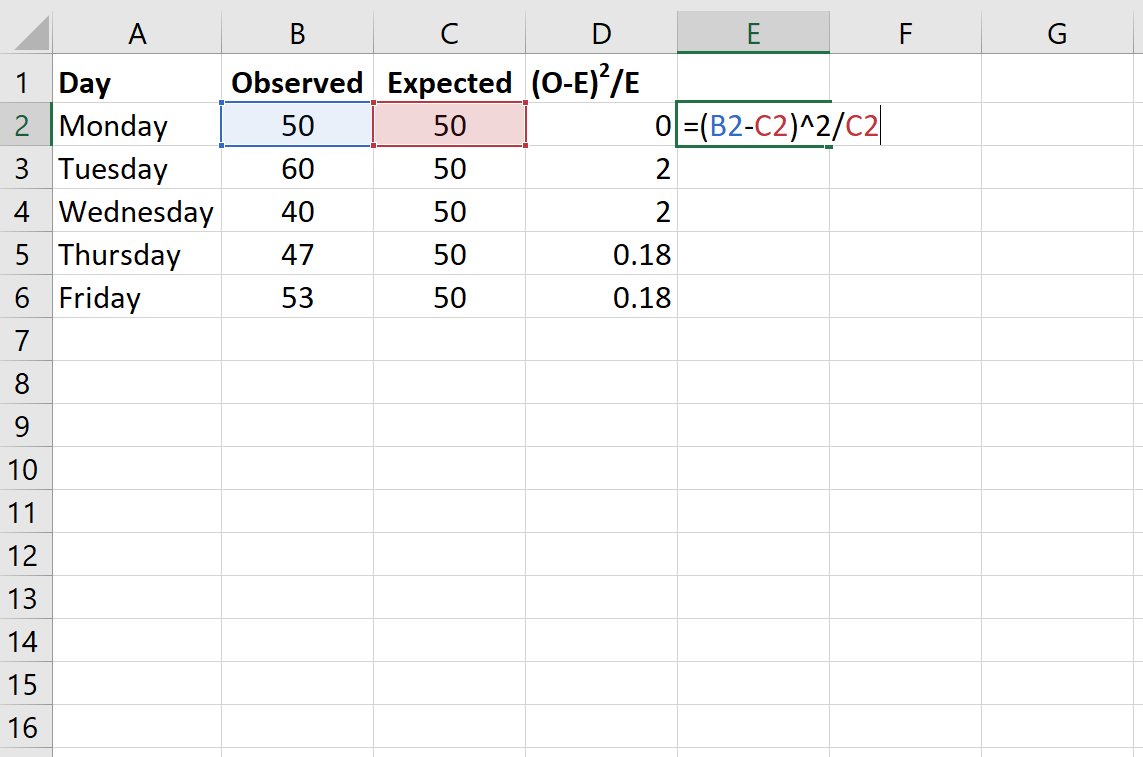
Stap 3: Bereken de chikwadraattoetsstatistiek en de bijbehorende p-waarde.
Ten slotte zullen we de Chi-kwadraat-teststatistiek en de bijbehorende p-waarde berekenen met behulp van de volgende formules:
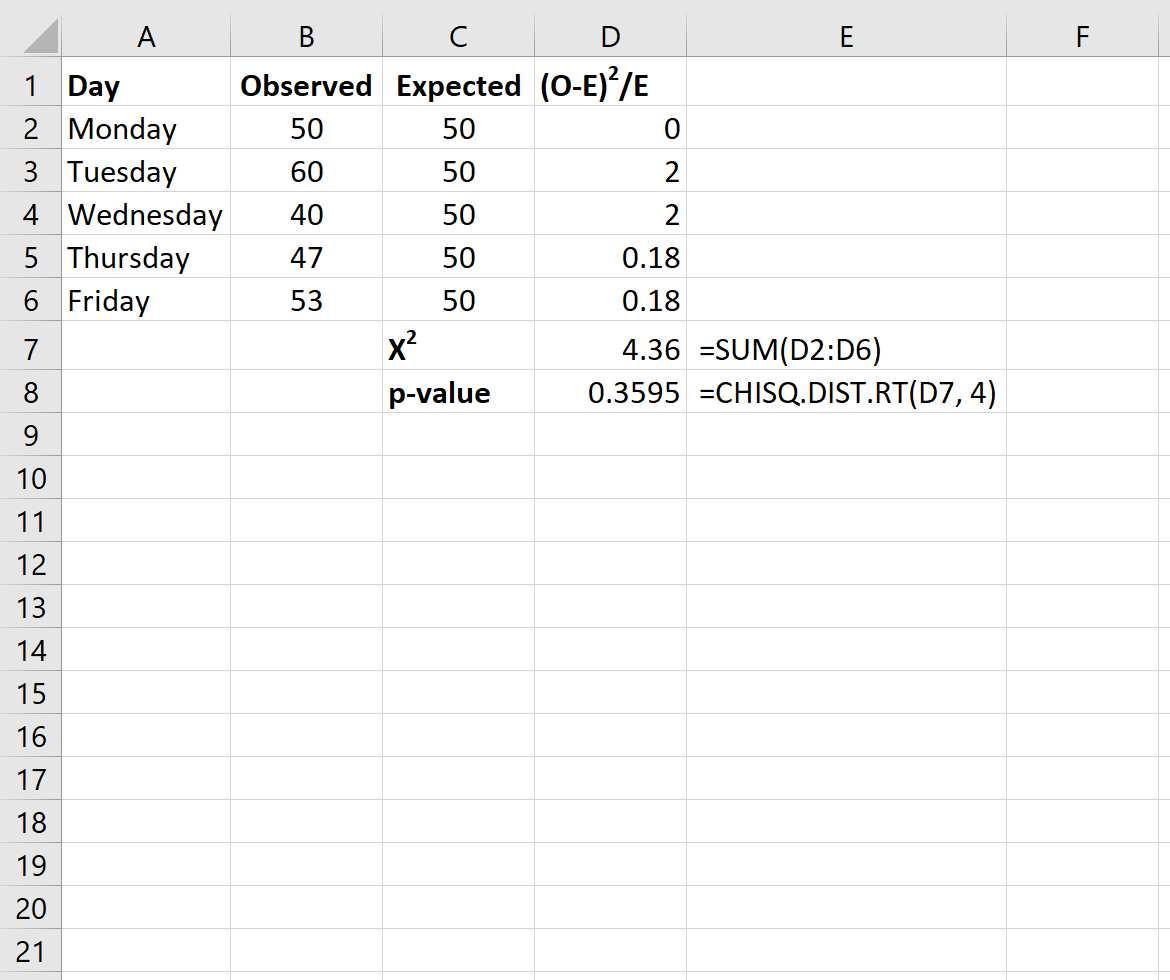
Opmerking: De Excel-functie CHISQ.DIST.RT(x, deg_freedom) retourneert de juiste waarschijnlijkheid van de Chi-kwadraatverdeling die is gekoppeld aan een teststatistiek x en een bepaalde vrijheidsgraad. De vrijheidsgraden worden berekend als n-1. In dit geval is deg_freedom = 5 – 1 = 4.
Stap 4: Interpreteer de resultaten.
De X2- teststatistiek voor de test is 4,36 en de overeenkomstige p-waarde is 0,3595 . Omdat deze p-waarde niet kleiner is dan 0,05, slagen we er niet in de nulhypothese te verwerpen. Dit betekent dat we niet genoeg bewijs hebben om te zeggen dat de werkelijke distributie van klanten verschilt van die gerapporteerd door de winkeleigenaar.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder