Scatterplots maken en interpreteren in spss
Een spreidingsdiagram is een type diagram dat we kunnen gebruiken om de relatie tussen twee variabelen weer te geven. Dit helpt ons zowel de richting (positief of negatief) als de sterkte (zwak, matig, sterk) van de relatie tussen de twee variabelen te visualiseren.
In deze tutorial wordt uitgelegd hoe u spreidingsdiagrammen in SPSS maakt en interpreteert.
Hoe u spreidingsdiagrammen maakt in SPSS
Stel dat we de volgende dataset hebben die de bestudeerde uren en behaalde examenscores voor 15 studenten weergeeft:
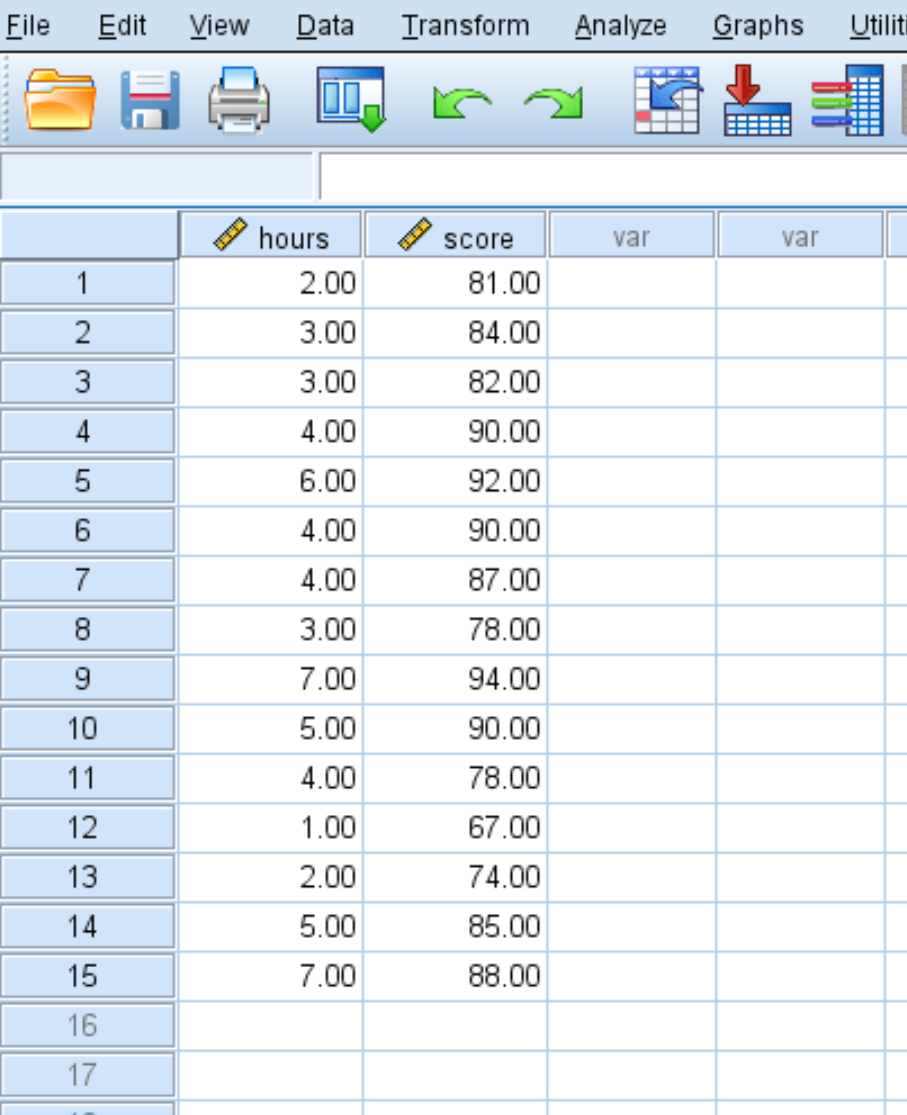
We kunnen een spreidingsdiagram maken om de relatie tussen de bestudeerde uren en de examenscore te visualiseren.
Basisspreidingsdiagram
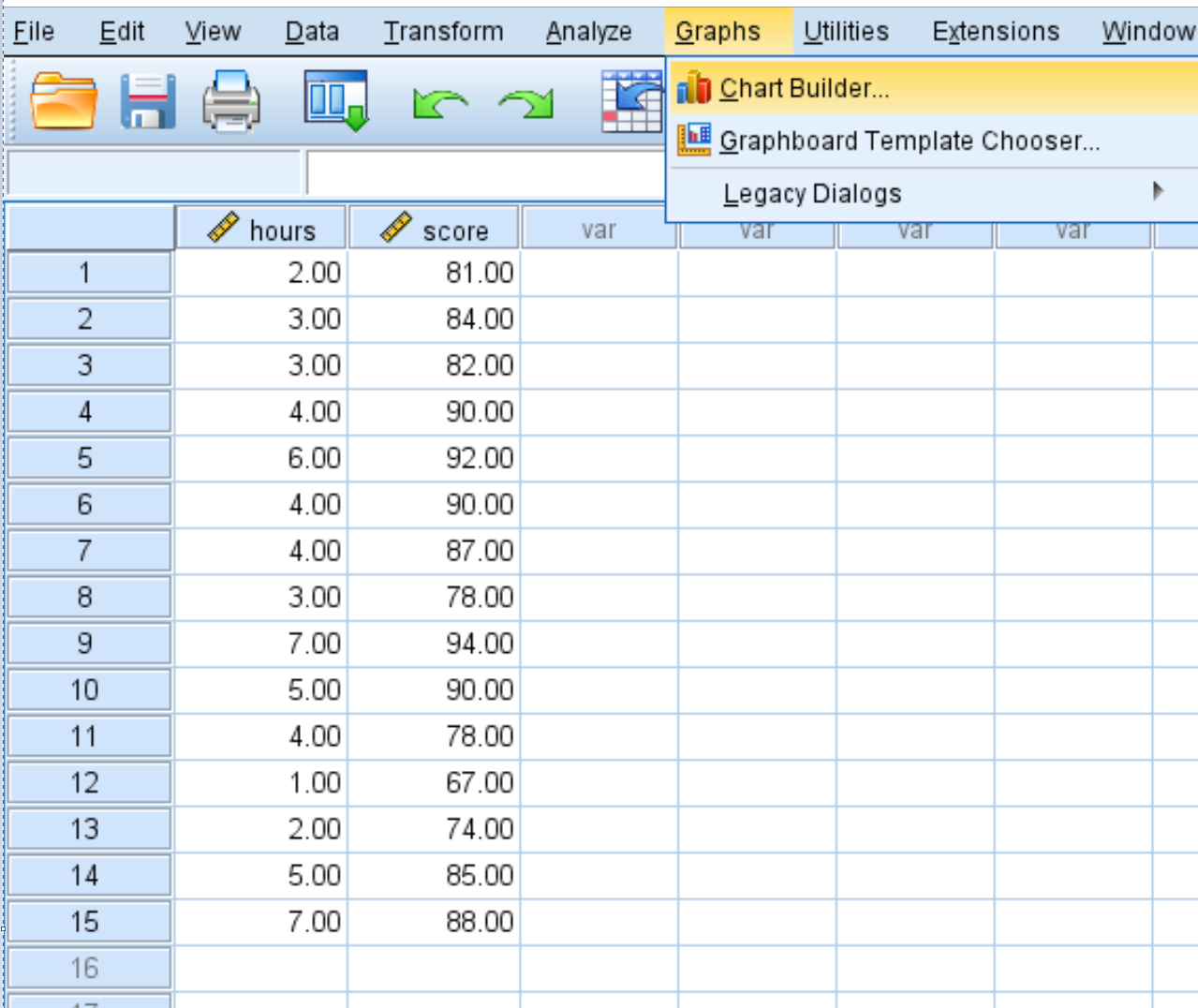
We kunnen een basisspreidingsdiagram maken in SPSS door op het tabblad Diagrammen te klikken en vervolgens op Chart Builder :
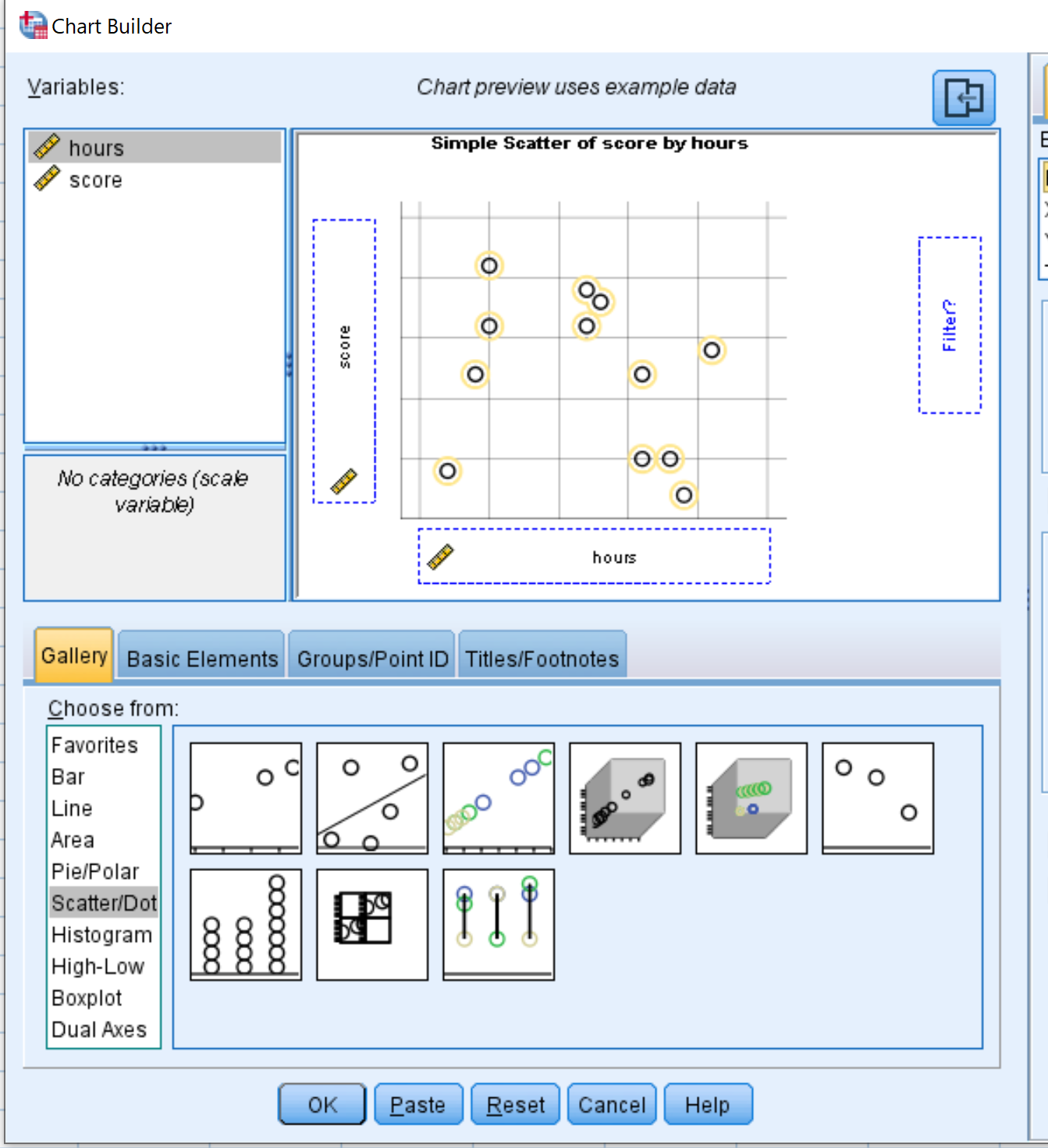
In het venster dat verschijnt, klikt u op Scatter/Point in de Kies uit: lijst. Sleep vervolgens de eerste optie met de tekst Simple Scatter naar het bewerkingsvenster. Sleep de variabele tijden op de X-as en de score op de Y-as:
Zodra u op OK klikt, verschijnt het volgende spreidingsdiagram:
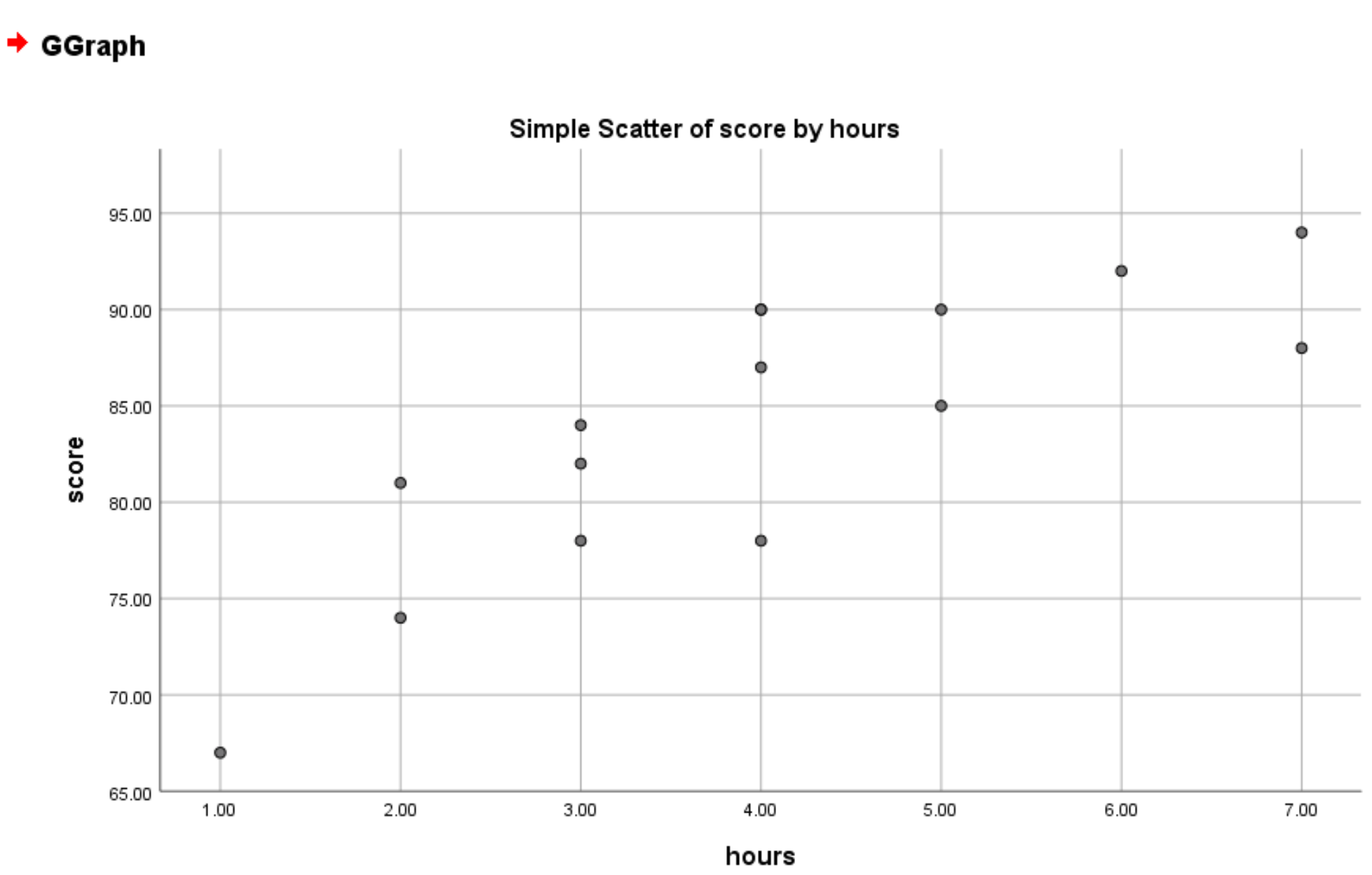
Standaard kiest SPSS een minimumpunt voor de y-as op basis van de kleinste waarde in uw dataset. In dit voorbeeld is het minimumpunt op de y-as 65. Als u dit wilt wijzigen in 0, klikt u op Y-as1 (Punt1) in het vak Elementeigenschappen en stelt u de minimumwaarde in op 0:
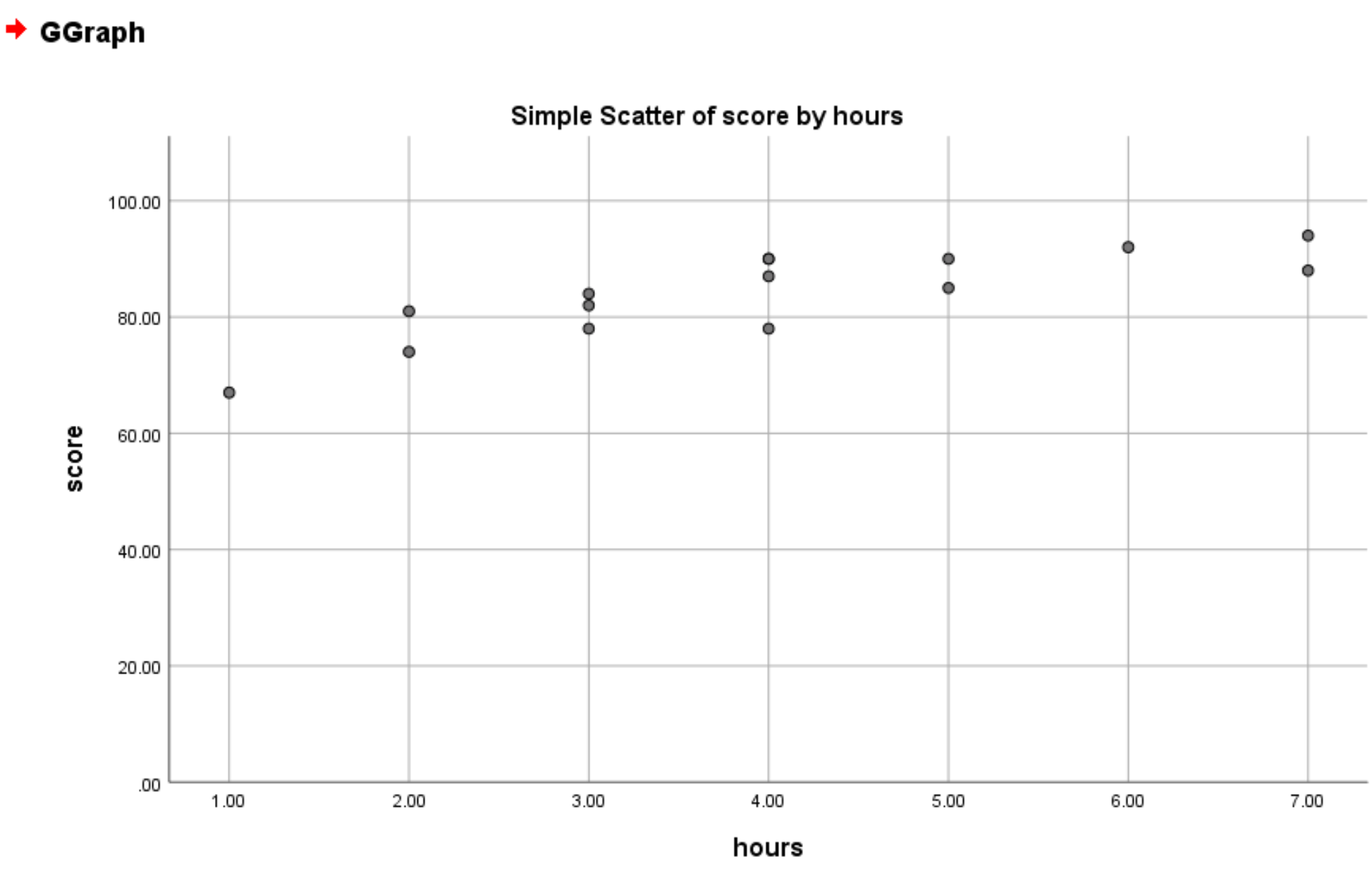
Zodra u op OK klikt, verschijnt er een nieuw spreidingsdiagram met de minimale y-aswaarde ingesteld op 0:
Spreidingsdiagram met regressielijn
We kunnen ook een spreidingsdiagram maken met een lijn die het beste past door de optie Eenvoudige spreiding met passende lijn te selecteren in het Chart Builder-venster:
Zodra we op OK klikken, verschijnt er een spreidingsdiagram met een lijn die het beste past:
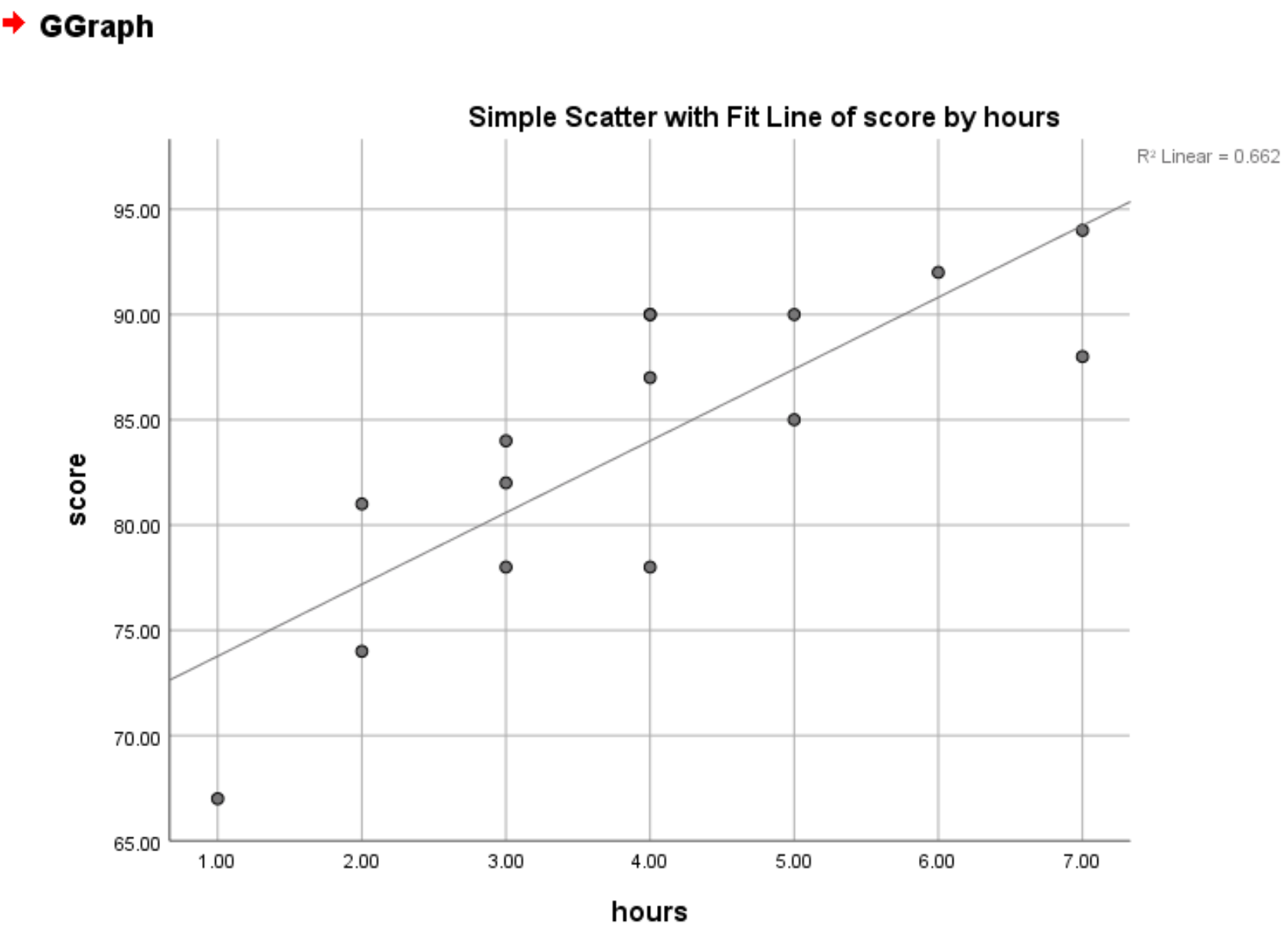
De R 2 -waarde verschijnt ook in de rechterbovenhoek van de grafiek. Dit vertegenwoordigt het percentage variatie in de responsvariabele dat kan worden verklaard door de voorspellende variabele. In dit geval betekent dit dat 66,2% van de variatie in examenscores kan worden verklaard door het aantal uren dat wordt gestudeerd.
Geclusterde puntenwolk
Laten we aannemen dat we ook een categorische variabele in onze dataset hebben, zoals geslacht:
In dit geval kunnen we een spreidingsdiagram maken van de bestudeerde uren versus de examenresultaten, gegroepeerd op geslacht.
Om dit te doen, kunnen we de Chart Builder opnieuw openen en Gegroepeerde spreiding als diagramtype kiezen. Opnieuw plaatsen we de variabele uren op de x-as en de score op de y-as, maar deze keer voegen we geslacht toe als variabele onder Kleur instellen:
Zodra we op OK klikken, verschijnt het volgende gegroepeerde spreidingsdiagram:
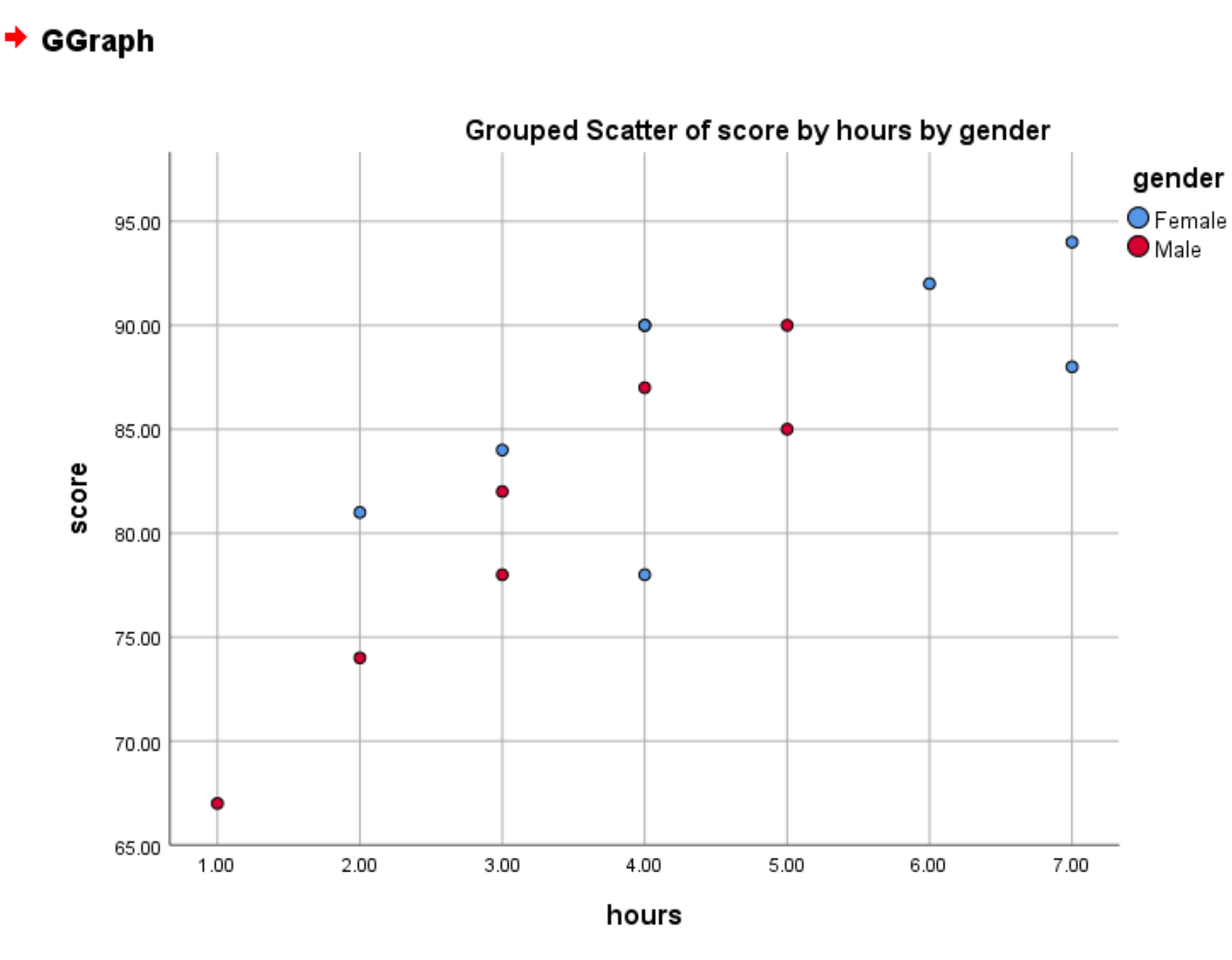
De rode cirkels vertegenwoordigen mannen en de blauwe cirkels vertegenwoordigen vrouwen.
Über den Autor
Dr.benjamin anderson
Ik ben Benjamin, een gepensioneerde hoogleraar statistiek die nu een toegewijde Statorials-lesgever is. Ik heb uitgebreide ervaring en expertise op het gebied van statistiek en ik ben vastbesloten om mijn kennis te delen met studenten via Statorials. Lees verder